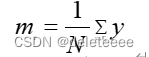Scikit-Learn K均值聚类
1、K均值聚类
K-均值(K-Means)是一种聚类算法,属于无监督学习。K-Means在机器学习知识结构中的位置如下:
1.1、K均值聚类及原理
聚类(Clustering)是指将一个数据对象集合划分成簇(子集),使得簇内对象彼此相似,簇间对象不相似。通俗来说,就是将数据划分到不同组中
根据算法原理,常用的聚类算法可分为:基于划分的聚类算法K-Means、基于层次的聚类算法HC、基于密度的聚类算法。本文主要介绍K-Means聚类
K-Means算法起源于1967年,由James MacQueen和J.B.Hartigan提出。K-Means中的K指的是类的数量,Means指均值
K-Means算法的基本原理是:根据样本特征的相似度或距离远近,将样本(N个点)划分成若干个类(K个集群),使得每个点都属于离其最近的中心点(均值)对应的类(集群)
其中,相似度通常使用欧几里得距离来度量,用于计算数据点与质心之间的距离(使用平方):
d ( X i , C j ) = ∣ ∣ X i − C j ∣ ∣ 2 d(X_i,C_j)=||X_i-C_j||^2 d(Xi,Cj)=∣∣Xi−Cj∣∣2
其中, X i X_i Xi是数据点, C j C_j Cj是质心
K-Means假设一个样本属于一个类,K-Means的类别是样本的中心(均值);K-Means的损失函数是样本与其所属类的中心之间的距离平方和:
J = ∑ j = 1 k ∑ i = 1 N j ∣ ∣ X i − C j ∣ ∣ 2 J=\sum_{j=1}^{k}\sum_{i=1}^{N_j}||X_i-C_j||^2 J=j=1∑ki=1∑Nj∣∣Xi−Cj∣∣2
其中, N j N_j Nj表示第 j j j个簇中的样本数量
K-Means算法的本质是物以类聚,其主要执行步骤如下:
- 初始化聚类中心(随机选取K个样本作为初始的聚类中心)
- 给聚类中心分配样本(计算各样本与各聚类中心的距离,把每个样本分配给距离它最近的聚类中心)
- 移动聚类中心(新的聚类中心移动到这个聚类所有样本的均值处)
- 停止移动(重复第二、第三步,直到聚类中心不再移动为止)
K-Means算法采用的是迭代的方法,得到的是局部最优解
那么,如何确定K值呢?K-Means通常根据损失函数和轮廓系数确定K值, J J J越小,聚类效果越好;轮廓系数越大,聚类效果越好
1.2、K均值聚类的优缺点
2、Scikit-Learn K均值聚类
2.1、Scikit-Learn K均值聚类API
Scikit-Learn提供了K均值聚类算法的API:
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init='auto', max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='lloyd')
官方对该API的描述为:
K-Means算法通过把样本分离成n个具有相同方差的类的方式来对数据进行聚类,最小化一个称为惯量或簇内平方和的准则。该算法需要指定簇的数量。它可以很好地扩展到大量样本,并已经在许多不同领域的应用领域被广泛使用
k-Means算法将一组N样本X划分成K个不相交的簇C,每个都用该簇中样本的均值 μ j \mu_j μj描述。这个均值通常被称为簇的“质心”;尽管它们处在同一个空间,但它们通常不是从X中挑选出的点,虽然它们是处在同一个空间
K-Means算法旨在选择一个质心,能够最小化惯性或簇内平方和的标准:
∑ i = 0 n min μ j ∈ C ( ∣ x i − μ j ∣ 2 ) \sum_{i=0}^{n} \min {\mu{j} \in C}\left(\left|x_{i}-\mu_{j}\right|^{2}\right) i=0∑nminμj∈C(∣xi−μj∣2)
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
中文官方文档:https://scikit-learn.org.cn/view/383.html
API参数及说明如下:
| 参数 | 说明 |
|---|---|
n_clusters |
要形成的簇数或要生成的质心数,默认为8 |
init |
初始化方法,默认为k-means++,表示选择初始的聚类中心之间的距离要尽可能远;其他还有random:从初始质心的数据中随机选择观测值 |
n_init |
使用不同质心运行K均值算法的次数种子,默认为auto |
max_iter |
k均值算法的最大迭代次数,默认300 |
tol |
收敛阈值,默认为1e-4 |
random_state |
确定质心初始化的随机数生成,默认为None |
copy_x |
是否复制原始数据,默认为True |
algorithm |
K-Means要使用的算法,默认为auto,其他参数有full、elkan |
常用属性及说明如下:
| 属性 | 说明 |
|---|---|
cluster_centers_ |
簇中心坐标 |
inertia_ |
样本到其最近的聚类中心的距离平方和 |
n_iter_ |
迭代次数 |
常用方法及说明如下:
| 方法 | 说明 |
|---|---|
fit(X,y) |
训练K-均值聚类 |
fit_transform(X) |
训练K-均值聚类并将X变换为簇距离空间 |
predict(X) |
预测X中每个样本所属的最接近的聚类 |
transform(X) |
将X转换为簇距离空间 |
2.2、K均值聚类案例
下面使用样本数据进行演示
创建样本数据:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
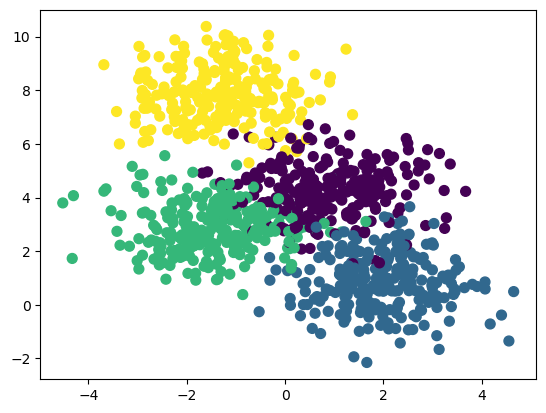
# 生成了包含5个类别的1000条样本数据
X, y = make_blobs(n_samples=1000, centers=5, random_state=1)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=15)
plt.show()

这里我们指定聚类的数目为5,但是实际情况中我们是不知道聚类的数目是多少的,这需要多次尝试
模型训练与评估:
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score # 轮廓系数法SC
# 划分训练集(80%)和测试集(20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# K-Means聚类器
kmeans = KMeans(n_clusters=5, n_init="auto")
# 训练模型
kmeans.fit(X_train, y_train)
# 模型评估
# 损失函数J(拐点法/手肘法)
print(kmeans.inertia_) # 1525.6665836724683
# 轮廓系数法SC
print(silhouette_score(X_test, y_test)) # 0.5635285557582774
绘制质心:
from pylab import mpl
# 使用全局字体
plt.rcParams["font.family"] = "SimHei"
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 创建一个画板和两个子图(1x2)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
markers = ["x", "o", "^", "s", "*"]
centers = kmeans.cluster_centers_
axes[0].scatter(X_train[:, 0], X_train[:, 1], marker="o", c=y_train, s=15)
axes[0].set_title("训练集的质心位置")
axes[1].scatter(X_test[:, 0], X_test[:, 1], marker="o", c=y_test, s=15)
axes[1].set_title("测试集的质心位置")
for idx, c in enumerate(centers):
axes[0].plot(c[0], c[1], markers[idx], markersize=10)
axes[1].plot(c[0], c[1], markers[idx], markersize=10)
plt.show()

![[Python] 什么是KMeans<span style='color:red;'>聚</span><span style='color:red;'>类</span>算法以及<span style='color:red;'>scikit</span>-<span style='color:red;'>learn</span>中的KMeans使用案例](https://img-blog.csdnimg.cn/direct/bdaa4fef9dc04fa4b65ae25e096d22ee.png)