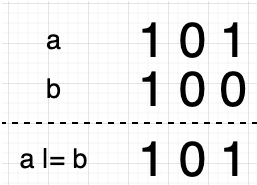说说你对Hash的理解?
hash的基本概念是把任意长度的输入通过一个hash算法之后,映射成固定长度的输出。
任意长度的输入转换成固定长度的输出会不会有问题?
有可能会碰到两个value值经过hash算法之后算出同样的hash值,产生hash冲突。
hash冲突可以避免吗?
理论上是无法避免的
好的hash算法应该考虑的点有哪些?
长文本能高效算出hash值;hash值不能逆推出原文;两次输入要保证hash值不同;降低hash冲突
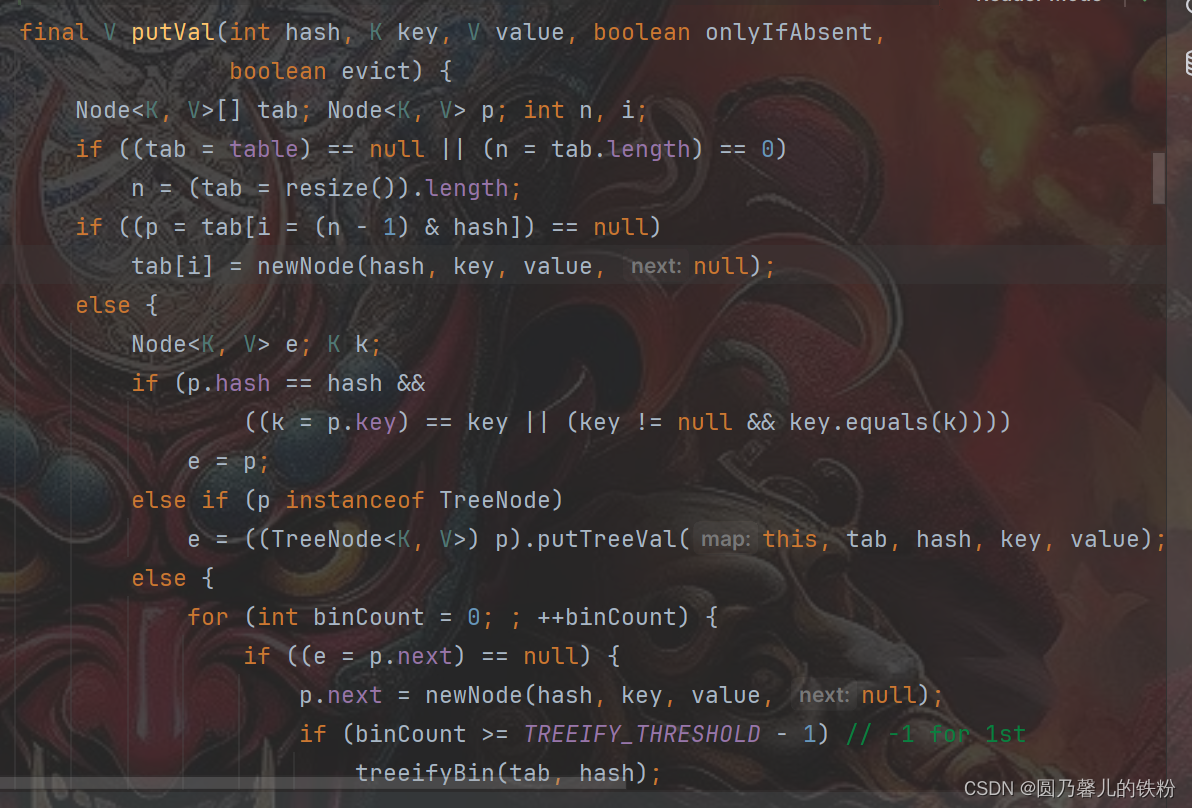
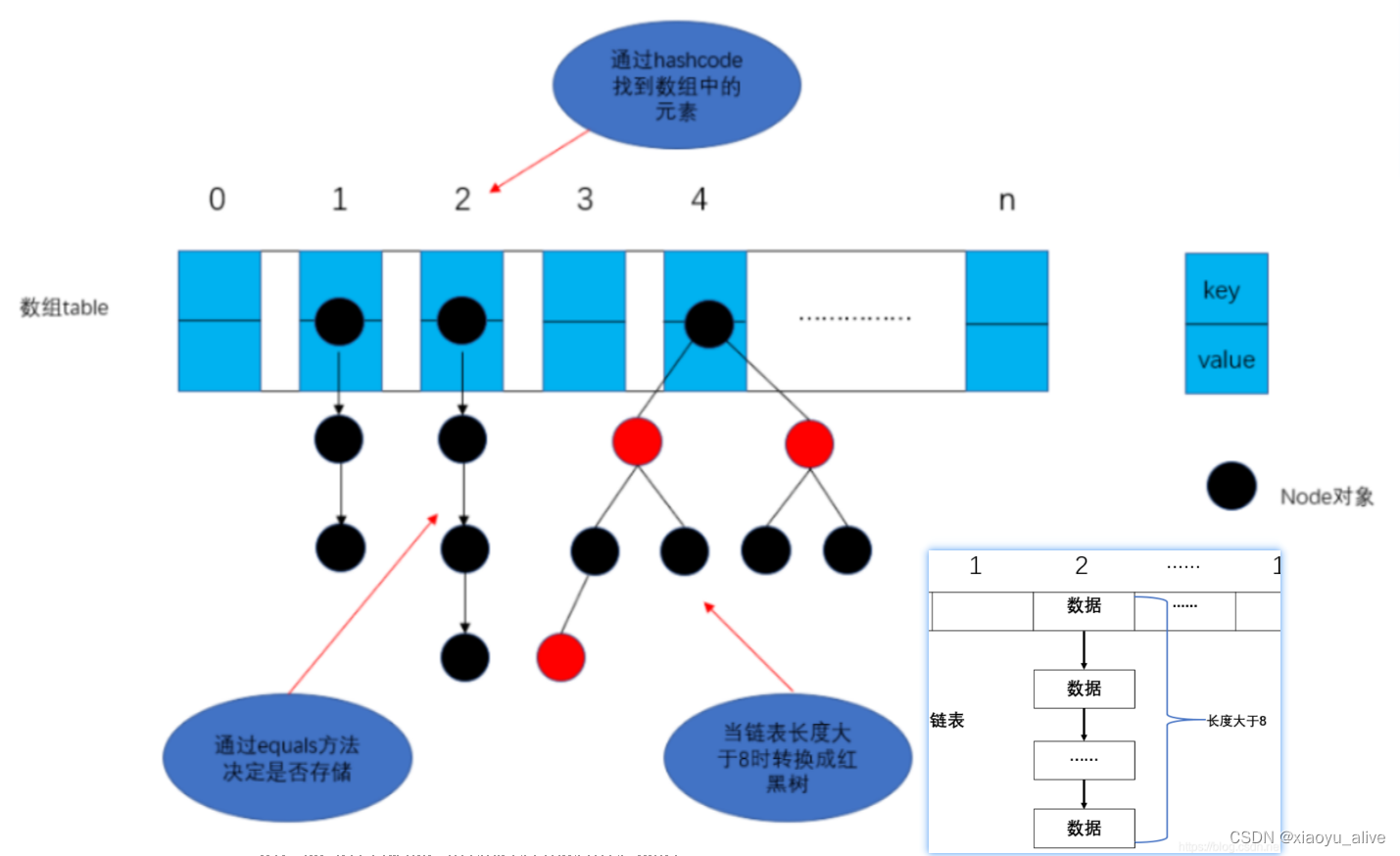
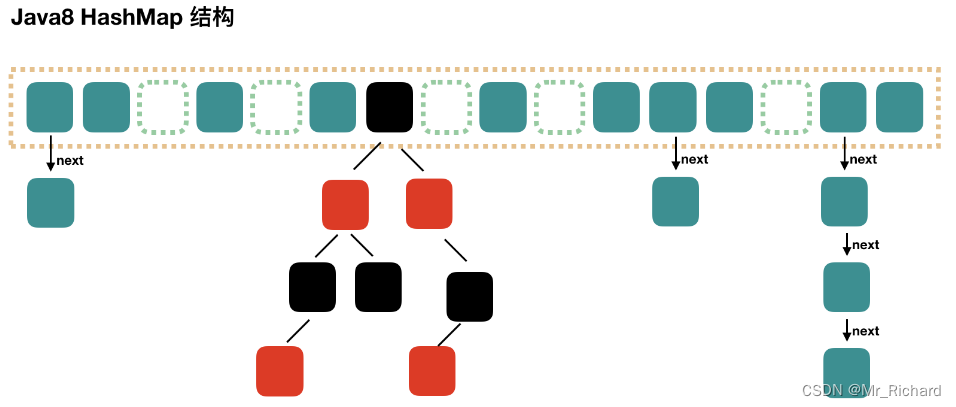
hashMap的存储结构?
jdk8后是:数组 + 链表 + 红黑树
每个数据单元都是Node结构,key、value、next、hash等字段,当发生hash冲突时当前桶位中的node与冲突node连成一个链表要用的字段
散列表什么时候创建?
散列表初始长度默认是16,散列表是懒加载机制,只有第一次put数据的时候,它才创建
默认的负载因子是多少,有什么作用?
默认负载因子是0.75,作用是计算扩容阈值用的,默认情况下的扩容阈值是16*0.75=12
链表转化为红黑树需要达到什么条件?
两个指标:一是链表长度达到8,二是当前散列表数组长度达到64,否则就是链表长度到了8,它也不会链转树,而是进行链表扩容
hash字段的值是怎么得到的?
hash值是key.hashcode二次加工得到的,加工原则是高16位 或 低16位得到一个新值。
散列表的长度必须是2的次方,寻址算法是hash & (table.length-1)
说说hashmap,put写数据的具体流程
前面的寻址算法都是一样的,都是根据kay,hashcode经过高低位异或之后的值,按位与 table.lenth-1,得到一个槽位下标,然后根据槽内的状况分为4种:
1.slot == null,把当前put方法传进来的key和value包装成一个node对象,放到这个slot中就可以了
2.slot != null,先对比node的key与当前put对象的key是否完全相等,如果完全相等就替换,不相等就属于hash冲突了,采用尾插法追加一个node就可以了
3.slot内的node已经链化,再追加一个节点的话,需要判断链表长度有没有达到树化标准,如果达到了要进行树化
4.冲突严重,转换成红黑树了
说下红黑树的写入操作
treeNode,继承了node,指向父节点,左右节点,表示颜色等4个字段,
首先找到一个合适的插入点,就是找到插入节点的父节点,红黑树满足二叉排序树的所有特性,找父节点的操作和二叉树是完全一致的,二分查找算法映射出来的结构,一颗倒立的二叉树,左节点小于当前节点,右节点大于当前节点,,每一次向下查找一层就可以排除掉一半的数据,一种是一直向下探测,直到查询到左子树或右子树为null,说明整个树中,它没有发现node的key与当前put的key一致的这个TreeNode,此时探测节点就是插入父节点所在,插入到父节点的左子树或者是右子树就完事了,根据插入节点的hash值和父节点hash值打消决定左右,插入会打破平衡,需要用到红黑树的平衡算法。第二种是根节点向下探测过程中,发现TreeNOde的key与当前put的key,完全一致,就说明它也是一次replace操作,直接替换TreeNode的value字段就可以了
红黑树原则:
1.每一个节点由红色或黑色组成
2.根是黑色
3.如果一个节点是红色的,那么它的子节点必须是黑色的
4.从一个节点到一个null引用的每一条路径必须包含相同数目的黑色节点
说下左旋和右旋
后续完善…
jdk8hashmap为什么要引入红黑树
解决hash冲突链化严重问题,链化后性能变低
hashmap什么情况下会触发扩容
写数据时会触发:一个是当前字段的数据量达到阈值后会触发扩容。
扩容后会扩容多大呢,算法是怎样的
table的长度必须是2的次方数,扩容都是按照上一次tableSize位移运算得到的,做一次左移 1位运算,假设当前tablesize是16,16<<1 == 32
为什么才用左移拿到tablesize的长度,而不是直接乘以2?
因为cpu不支持乘法运算,所有的乘法运算最终都是转化成加法计算的,使用位移运算更高效
老数组中的数据怎么迁移?
迁移其实就是挨个桶位推进迁移,一个桶位一个桶位的进行处理,主要还是看当前处理桶位的数据状态:
1.slot == null
2.slot != null,没有链化,当迁移的时候发现slot中存储的这个node节点,它的next是null的时候,说明这个slot没有发生过hash冲突,根据新表的tablesize计算出它在新表的位置,然后存放过去就可以了;迁移发现next字段不是null,说明这个slot发生过hash冲突,这个时候需要把当前slot中保存到这个链表,拆成两个链表,分别是高位链和低位链,低位链因为高位是0,所以迁移到node新表的时候,slot下标和老的是一样的,那高位链,当高位是1时,存储到新表后的位置是老表位置+老表的tablesize,比如说老表长度是16,存储在老表的位置是8,那存储扩容后的表位置就是8+16,下标24的桶位
红黑树的扩容
红黑树的节点对象,TreeNode结构,它依然保留了next字段,也就是说红黑树结构内部维护了一个链表,查询时不用,但新增删除节点时仍然需要维护这个链表,作用是方便拆分红黑树时使用,和普通的node没区别,根据高低位拆分成高位链和低位链,高位链存储在新表的老表位置+老表数组长度,然后计算出来的这个位置,低位链存房的位置和老表是同一个位置。不同的点是拆分出来的链表需要看下它的长度,如果长度<=6,直接将TreeNode转化成普通的node链接,放到扩容后的新表中就可以了,如果拆分出来的长度当然是大于6的,需要将链表升级成红黑树结构