1.论文介绍
SAM-Adapter: Adapting Segment Anything in Underperformed Scenes
SAM适配器:在表现不佳的场景中适配任何片段
SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes:
Camouflage, Shadow, Medical Image Segmentation, and More
SAM无法分割任何内容?- SAM适配器:在表现不佳的场景中适配SAM:摄影、阴影、医学图像分割等
2023年 arXiv
Paper Code
2.摘要
大型模型(也称为基础模型)的出现为人工智能研究带来了重大进展。一个这样的模型是Segment Anything(SAM),它是为图像分割任务而设计的。然而,与其他基础模型一样,我们的实验结果表明,SAM在某些分割任务中可能会失败或表现不佳,例如阴影检测和隐藏对象检测(隐藏对象检测)。这项研究首先为将大型预训练图像分割模型SAM应用于这些下游任务铺平了道路,即使在SAM表现不佳的情况下。而不是微调SAM网络,我们提出SAM适配器,它采用了特定于域的信息或视觉提示到分割网络,通过使用简单而有效的适配器。通过将特定任务的知识与大模型学习到的一般知识相结合,SAM-Adapter可以显着提高SAM在挑战性任务中的性能,如大量实验所示。我们甚至可以超越特定任务的网络模型,并在我们测试的任务中实现最先进的性能:隐藏对象检测,阴影检测。我们还测试了息肉分割(医学图像分割),并取得了更好的结果。我们相信,我们的工作为SAM在下游任务中的应用开辟了机会,在各个领域都有潜在的应用,包括医学图像处理、农业、遥感等。
Keywords:SAM,SAM适配器
3.Introduction
人工智能研究已经见证了一种范式转变,模型在大量数据上进行了大规模训练。这些模型,或称为基础模型,如BERT,DALL-E和GPT-3,在许多语言或视觉任务中显示出有希望的结果。最近,在基础模型中,Segment Anything(SAM)作为在大型视觉语料库上训练的通用图像分割模型具有独特的地位。事实证明,SAM在不同的场景中具有成功的分割能力,这使其成为图像分割和计算机视觉相关领域的突破性一步。然而,由于计算机视觉涵盖了广泛的问题,SAM的不完整性是显而易见的,这与其他基础模型相似,因为训练数据无法涵盖整个语料库,并且工作场景会发生变化。在这项研究中,我们首先在一些具有挑战性的低级结构分割任务中测试SAM,包括隐藏对象检测(隐藏场景)和阴影检测,我们发现在一般图像上训练的SAM模型在这些情况下不能完美地“分割任何东西”。因此,一个关键的研究问题是:如何利用大型模型从大量语料库中获得的能力,并利用它们来造福下游任务?
在这里,我们介绍SAM适配器,它作为上述研究问题的解决方案。这项开创性的工作是首次尝试使大型预训练图像分割模型SAM适应特定的下游任务,并提高性能。正如其名称所述,SAMAdapter是一种非常简单但有效的自适应技术,它利用了内部知识和外部控制信号。具体来说,它是一个轻量级模型,可以用相对少量的数据学习对齐,并作为一个额外的网络,从该任务的样本中注入特定于任务的指导信息。使用视觉提示将信息传递到网络,这已被证明是高效和有效的,可以使冻结的大型基础模型适应许多下游任务,并且具有最少数量的附加可训练参数。
具体来说:SAM适配器可以直接应用于各种任务的定制数据集,以提高性能的协助SAM。可以毫不费力地将联合收割机多个显式条件组合起来,以多条件控制微调SAM。
本文的主要贡献可以概括如下:
- 首先,对作为基础模型的Segment Anything(SAM)模型的不完备性进行了分析,提出了如何利用SAM模型为下游任务服务的研究问题。
- 其次,我们首次提出了自适应方法SAM-Adapter,以使SAM适应下游任务并实现增强的性能。适配器将特定于任务的知识与大型模型学习的一般知识相结合。可以灵活地设计特定于任务的知识。
- 第三,尽管SAM的骨干是一个简单的普通模型,缺乏为两个特定的下游任务量身定制的专门结构,但我们的方法仍然超过了现有的方法,并在这些下游任务中达到了最先进的(SOTA)性能。
4. 网络结构详解
使用SAM作为backbone:
SAM适配器的目标是利用从SAM中学习的知识。因此,本文使用SAM作为分割网络的骨干。SAM的图像编码器是ViT-H/16模型,具有14 x14窗口注意力和四个等间隔的全局注意力块。保持预训练图像编码器的权重冻结。还利用SAM的掩码解码器,它由一个修改后的Transformer解码器块和一个动态掩码预测头组成。使用预训练的SAM的权重来初始化我们方法的掩码解码器的权重,并在训练期间调整掩码解码器。在SAM的原始掩码解码器中不输入任何提示。
图像编码器参数不训练,只训解码器,提示编码器不使用。
适配器:
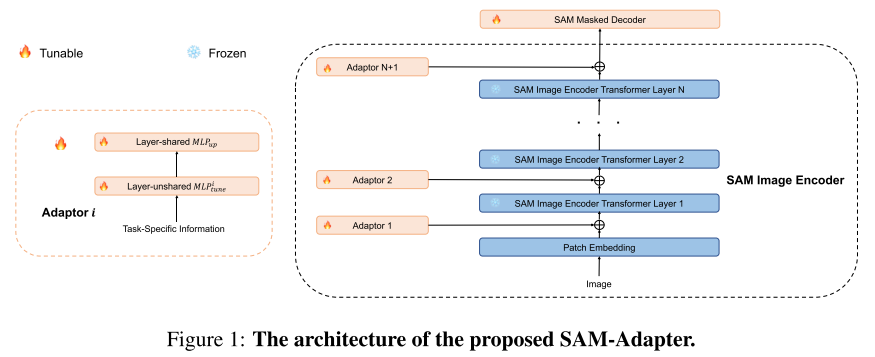
接下来,任务特定的知识Fi被学习并通过适配器注入到网络中。采用了提示的概念,它利用了基础模型已经在大数据集上被训练的事实。使用适当的提示来引入特定于任务的知识可以增强模型对下游任务的泛化能力,特别是当注释数据很少时。所提出的SAM适配器的架构如上图所示。目标是保持适配器的设计简单而高效。因此,选择使用仅由两个MLP和两个MLP中的激活函数组成的适配器。具体地,适配器获取信息Fi并获得提示Pi:
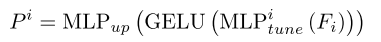
其中 M L P t u n e i MLP^i_{tune} MLPtunei是用于为每个适配器生成任务特定提示线性层。 M L P u p MLP_{up} MLPup是所有适配器共享的上投影层,用于调整Transformer要素的尺寸。Pi是指附加到SAM模型的每个Transformer层的输出提示。GELU是GELU激活函数。信息Fi可以被选择为各种形式。
输入任务特定信息:
值得注意的是,信息Fi可以根据任务而具有各种形式,并且可以被灵活地设计。例如,它可以以某种形式从任务的特定数据集的给定样本中提取,例如纹理或频率信息,或一些手工制作的规则。此外,Fi可以是由多个引导信息组成的合成形式:
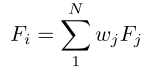
其中Fj可以是一种特定类型的知识/特征,并且wj是用于控制合成强度的可调节权重。
5.实验
在实验中,选择了两种类型的视觉知识,补丁嵌入Fpe和高频分量Fhfc,wj被设置为1。因此,Fi由Fi = Fhfc +Fpe导出。MLPi tune具有32个线性层,MLPi up是一个线性层,其将来自GELU激活的输出映射到Transformer层的输入数量。我们使用SAM的ViT-H版本。平衡BCE损失用于阴影检测。BCE损失和IOU损失被用于隐藏对象检测和息肉分割。AdamW优化器用于所有的实验。初始学习率设置为2 e-4。余弦衰减应用于学习率。对图像对象分割的训练进行20个epoch。阴影分割训练了90个epoch。息肉分割被训练120个时期。实验使用PyTorch在四个NVIDIA Tesla A100 GPU上实现。
其实就是把提示编码器换成高频分量+补丁分量,然后以SAM为backbone,微调SAM使其适配下游任务。




















![[Linux]进程间通信—管道通信](https://img-blog.csdnimg.cn/direct/581ed5271a884471ac576e9b06097057.png#pic_center)