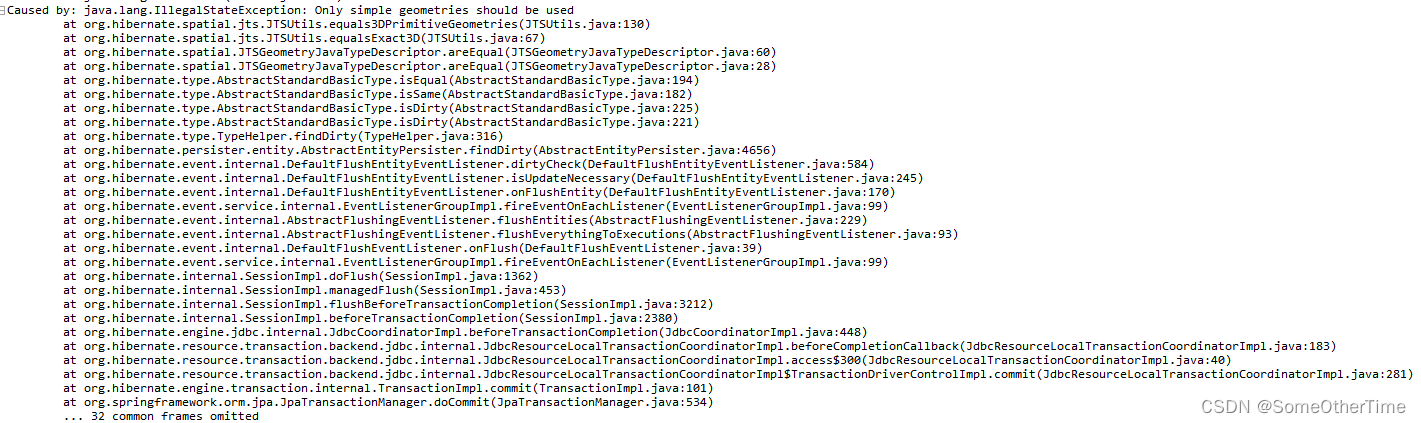
SENet(Squeeze-and-Excitation Networks)是2017年提出的一种经典的通道注意力机制,这种注意力可以让网络更加专注于一些重要的featuremap,它通过对特征通道间的相关性进行建模,把重要的特征图进行强化来提升模型的性能。论文链接 代码实现
模型
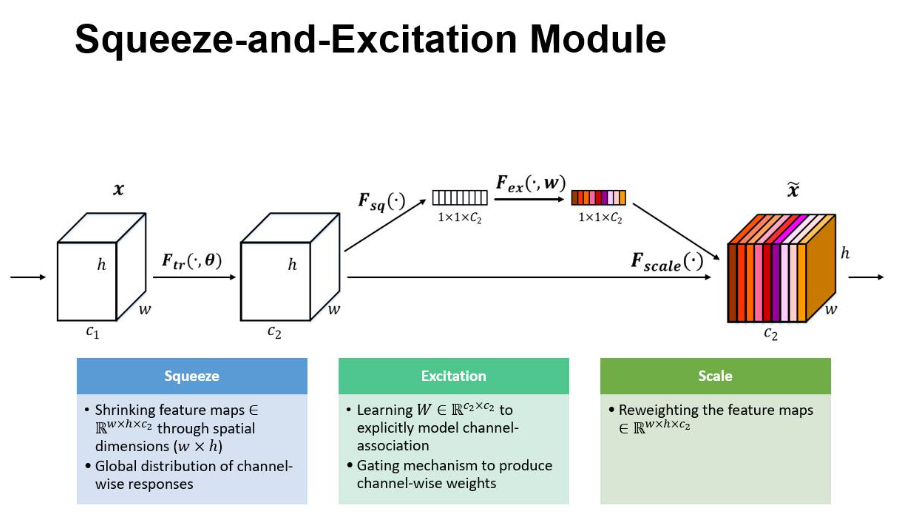
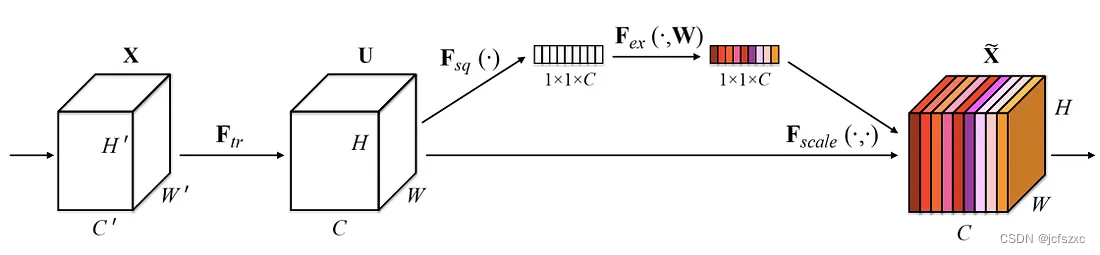
SENet的模型结果如图所示:

网络的输入 X X X是个多通道的图片,其维度为 [ H ′ , W ′ , C ′ ] [H',W^′,C^′] [H′,W′,C′] ,经过一系列卷积等维度变化操作后得到U,其维度是 [ H , W , C ] [H,W,C] [H,W,C] ,其中C是通道的数量,那么我们融合不同通道的特征呢,这个时候就进入到了SENet,对于U,先经过全局平均池化的操作,即将U的维度由 [ H , W , C ] [H,W,C] [H,W,C]变成 [ 1 , 1 , C ] [1,1,C] [1,1,C],这一步对应着上图中的 F s q ( ⋅ ) F_{sq} ( \cdot) Fsq(⋅) ,实际上是对每一个特征图的特征通过池化的方式做了一个总结,这个总结作为初始值送入后面的多层神经网络,学习到不同通道的权重。全连接层的结构为:

这个多层感知机的结构非常简单,就是两个全连接层和两个激活函数,在第一次全连接层后使用Relu激活函数,此时得到的输出维度为 [ 1 , 1 , C ′ ′ ] [1,1,C''] [1,1,C′′] 。第二个全连接层后使用Sigmoid函数,将每层数值归一化到0-1之间,以此表示每个通道的权重,第二个全连接的输出也为 [ 1 , 1 , C ] [1,1,C] [1,1,C]。得到了最后 [ 1 , 1 , C ] [1,1,C] [1,1,C]的输出后,我们将 U U U和刚刚得到的权重结果相乘,得到最终的特征图 X ^ \hat X X^,它和 U U U的维度一致,但是在 X ^ \hat X X^中,不同特征图已经根据权重结果进行了重新加权。
代码
附上SENet的一个简单实现:
def SENet(input):
#全局平均池化
x = nn.AdaptiveAvgPool2d((1,1))(input)
x = x.view(1, -1)
#第一个全连接层
x = nn.Linear(2, 1)(x)
x = nn.functional.relu(x)
#第二个全连接层
x = nn.Linear(1, 2)(x)
x = nn.functional.sigmoid(x)
return x
if __name__ == '__main__':
input = torch.ones(1, 2 ,2 ,2)
output = SENet(input)
# 将SENet的输出维度进行变化,以便后面的乘机操作
output = output.view(input.shape[0], input.shape[1],1, 1)
SE_output = input*output

![[NSSRound#1 Basic]basic_check](https://img-blog.csdnimg.cn/img_convert/c86ecc247d71f727c920eb80eac89bbf.png)









![[C++ QT项目实战]----C++ QT系统登陆界面设计](https://img-blog.csdnimg.cn/direct/cb3caae712914429a9a0f0df087dc9b7.png)