声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
经常有小伙伴问我,面对如此多的预测程序,到底哪一个模型预测效果的最好?事实上,不存在一种预测效果最好的程序。
根据“没有免费午餐定理”:不存在一种机器学习算法适合于任何领域或任务。如果有人宣称自己的模型在所有问题上都好于其他模型,那么他肯定是在吹牛。
也就是说,模型预测效果同时取决于数据和模型的匹配程度,任何算法都有局限性,并不是模型越复杂效果越好(但是新颖的模型肯定更受审稿人喜爱一些)。没有数据空谈模型效果不现实,只有尝试了才知道是否匹配。
因此,为了解决大家的选择困难症,本期为大家推出了Attention模型全家桶!将CNN/TCN/LSTM/BiGRU-Attention四种多变量回归模型打包到全家桶中,方便大家选择最适合自己数据的模型!
当然,全家桶价格也是非常优惠的,相当于单买的5折优惠左右!同时,作者在这里承诺,一次购买永久更新!日后也会推出其他算法结合注意力机制的模型,如BiTCN-Attention等等,但如果你之后再买,一旦推出新模型,价格肯定是会上涨的!所以需要创新或对比的小伙伴请早下手早超生!!
数据介绍
本期采用的数据是经典的回归预测数据集,是为了方便大家替换自己的数据集,各个变量采用特征1、特征2…表示,无实际含义,最后一列即为输出。
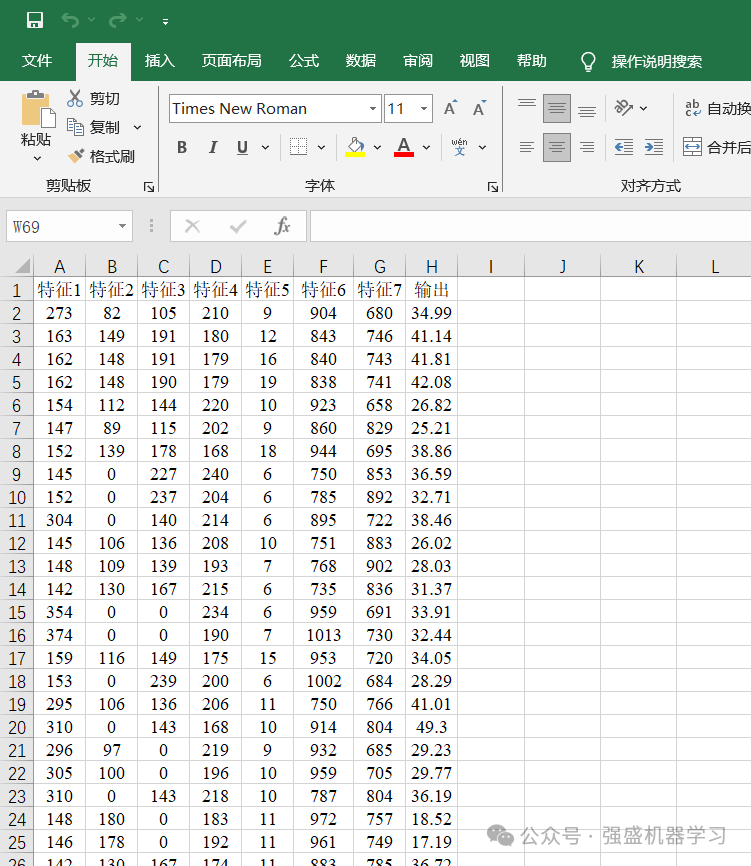
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可,无需更改代码,非常方便!
效果展示
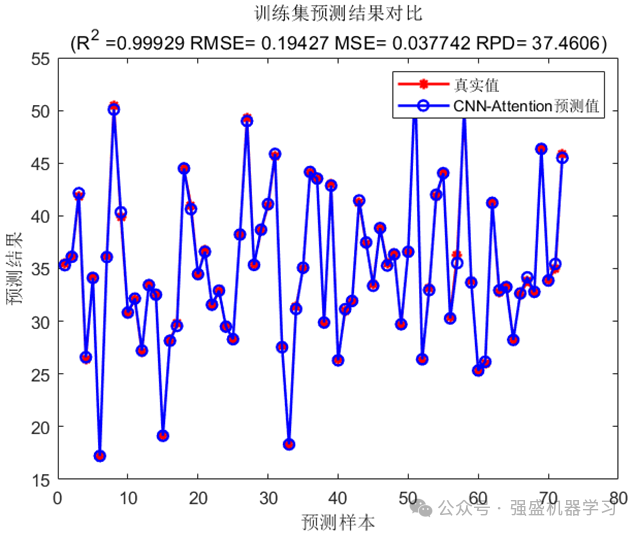
这里以CNN-Attention为例,展示一下模型运行结果(不同模型出图数量与效果可能略有不同,具体可查看全家桶中每个模型的链接):
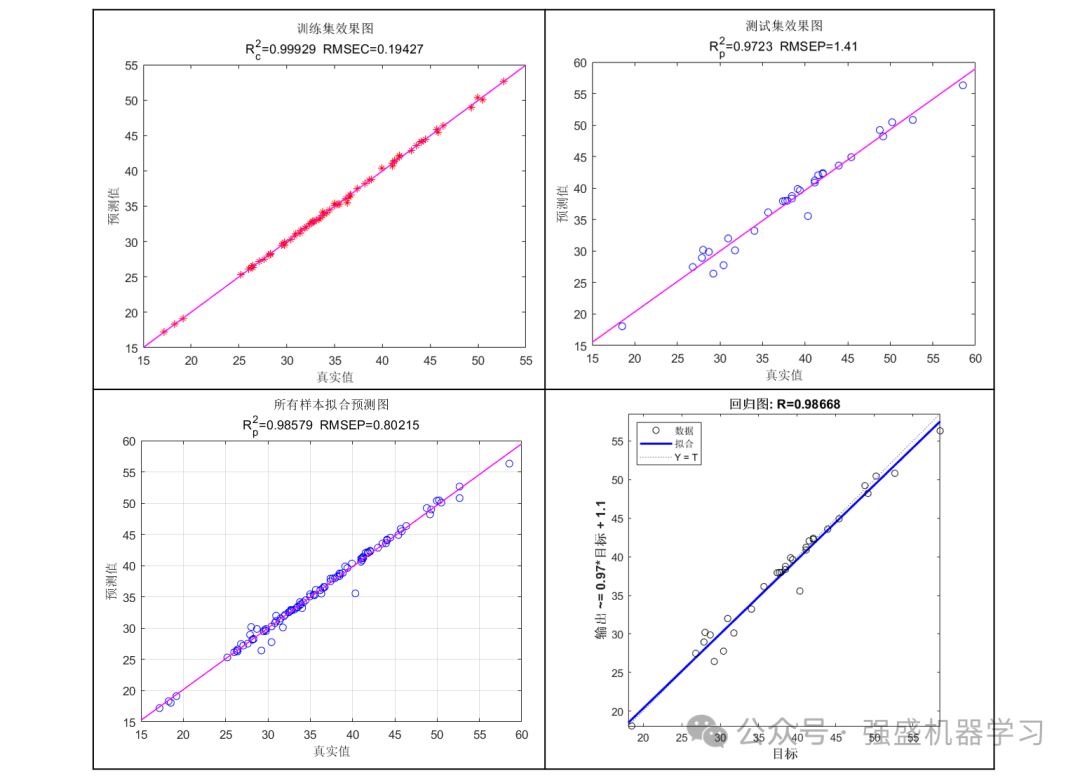
训练集预测结果图:
测试集预测结果图:
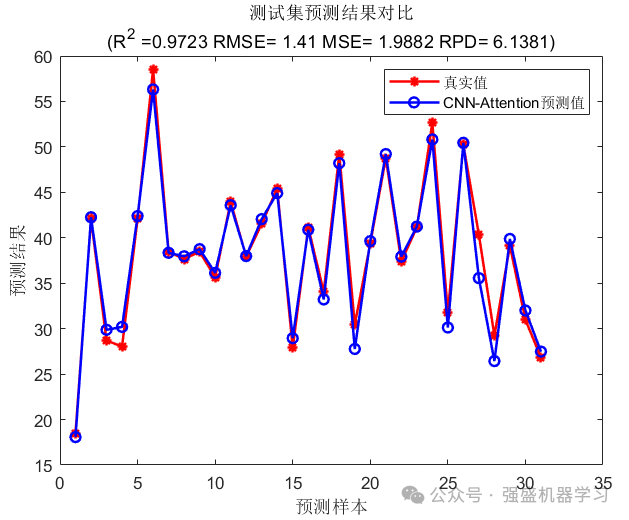
误差直方图:
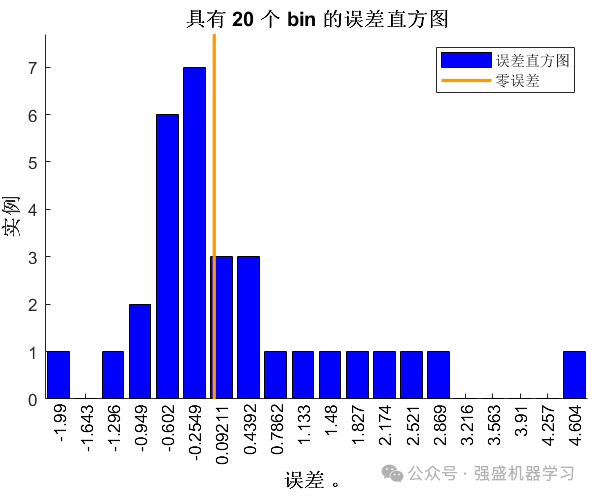
线性拟合图:
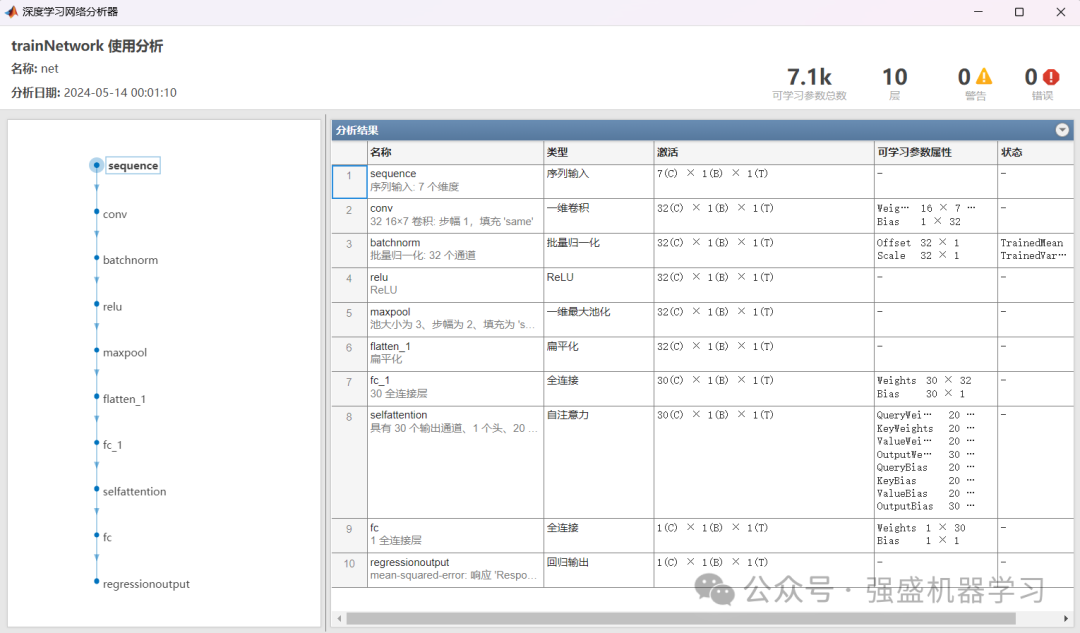
网络结构图:
命令行窗口误差显示:

以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,不像其他代码一样需要每个文件运行很多次!
适用平台:Matlab2023及以上,没有的文件夹里已经免费提供安装包,直接下载即可!
原理简介
此处主要为大家讲解下本期全家桶使用的自注意力机制:
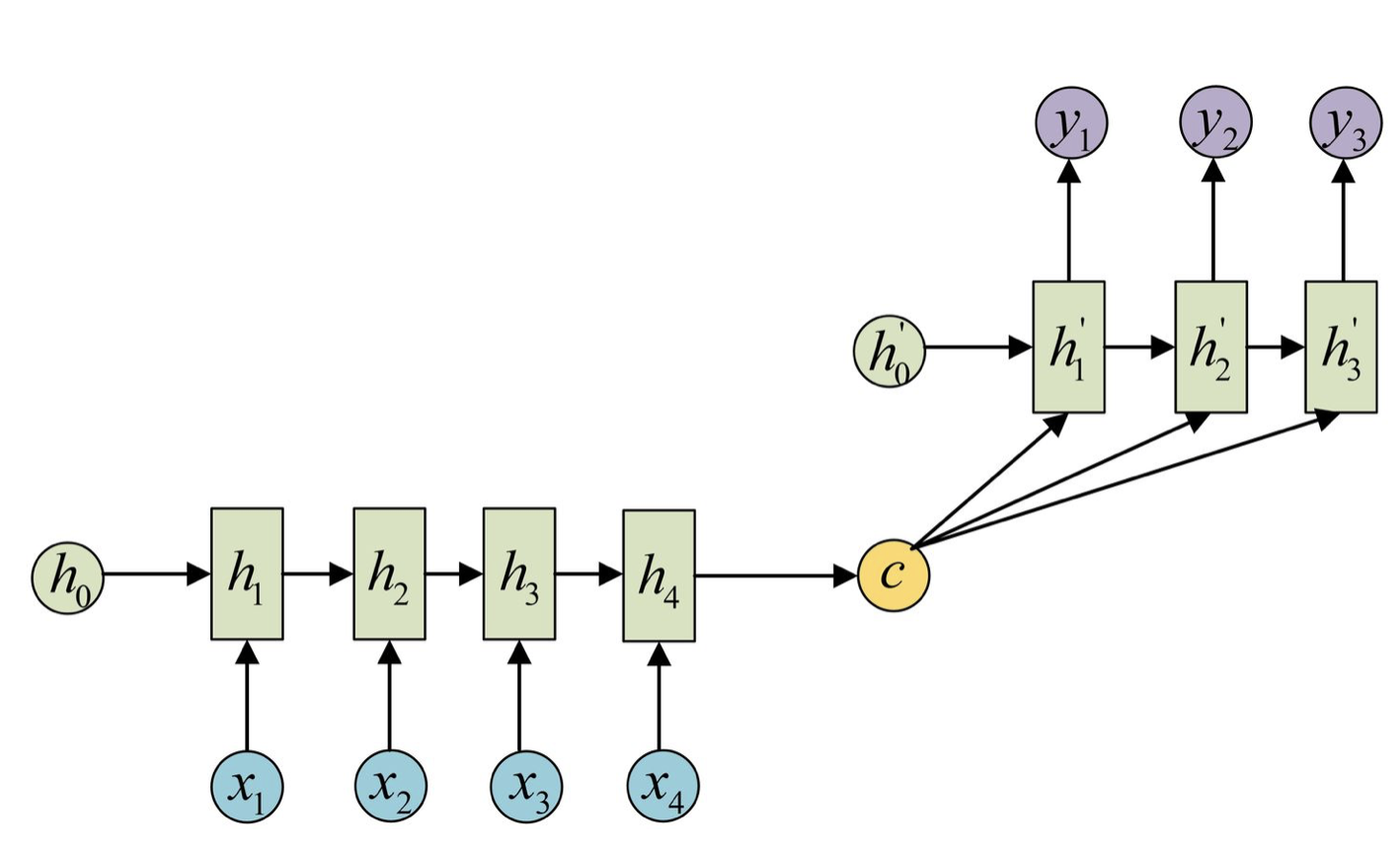
注意力机制最早由Bahdanau提出,通过学习对图像中不同区域的注意力权重,将视觉注意力引入到图像描述生成模型中,从而提升了模型的质量和准确性。后来,注意力机制被广泛应用于其他领域,它通过动态计算注意力权重来适应不同的输入情况。这种机制使得模型能够处理更长的输入序列,可以更好地捕捉序列中的依赖关系。
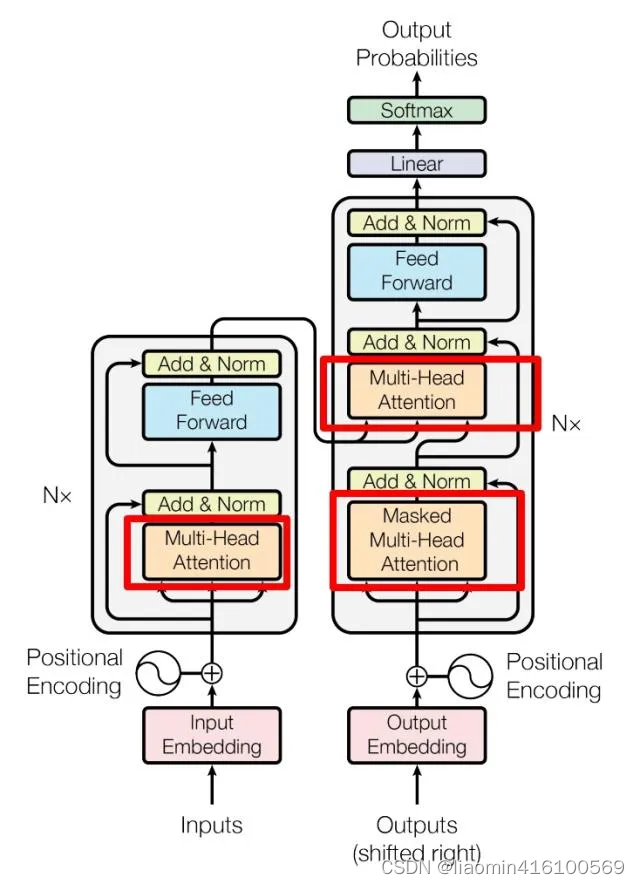
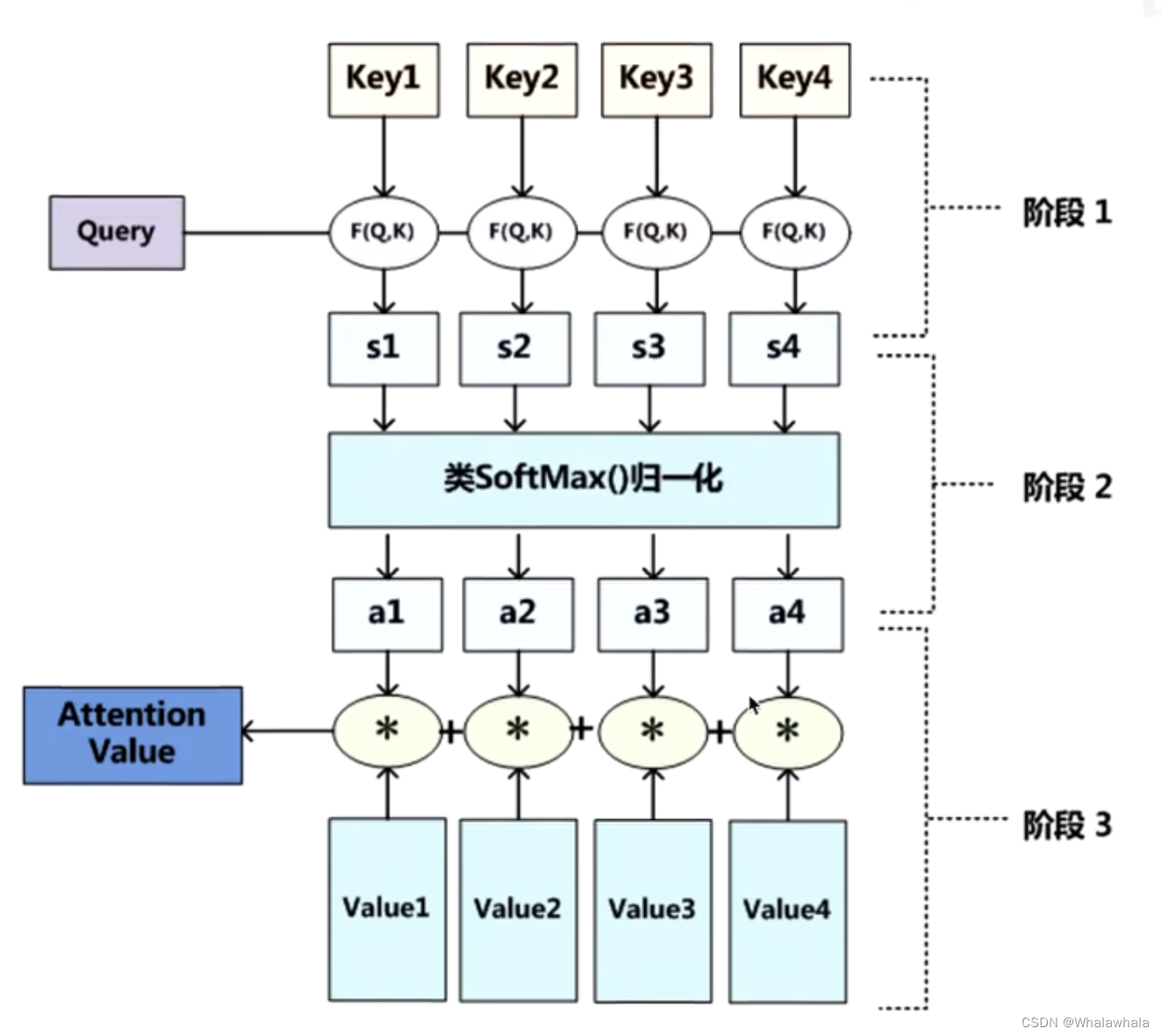
自注意力机制在传统注意力机制的基础上进行了进一步改良,通过并行计算,同时计算一句话中所有元素之间的相似性得分,从而获取全局的信息而非单一上下文的信息,这使得自注意力机制能够更全面地理解整个序列的语义,并更好地捕捉元素之间的复杂关系,其相关公式如下所示:
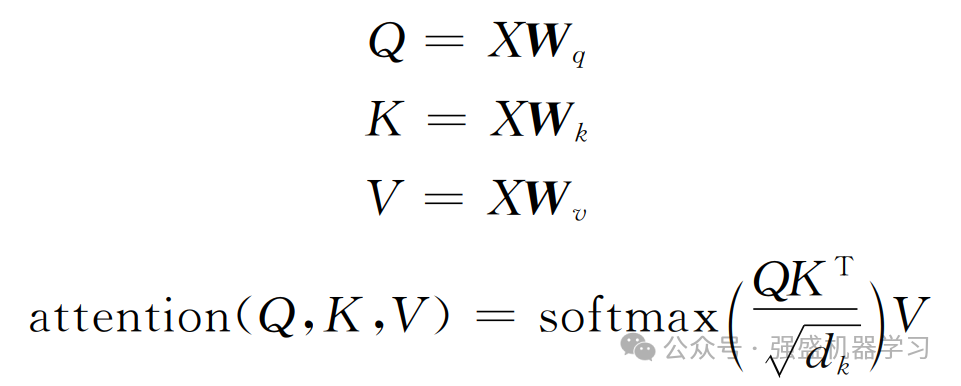
式中:Wq、Wk、Wv为线性变化矩阵;Q、K、V分别为查询向量(query)、键向量(key)和值向量(value);dk为查询向量和键向量的维度。最后,将注意力权重和值向量进行加权求和,得到自注意力机制的输出。
多头自注意力机制引入多个单注意力头,每个注意力头都是一个独立的自注意力机制,学习到一组不同的权重和表示。在多头自注意力机制中,输入序列首先通过线性变换映射到多个不同的query、key、和value空间。每个注意力头都会对这些映射后的查询、键和值进行独立的注意力计算,得到每个位置的表示。最后,将模型中每个注意力头的表示通过线性变换和拼接操作来合并,就得到最终的输出表示。

代码目录
以下所有代码,无需更改代码,直接替换Excel数据即可运行!可以说是非常方便,非常适合新手小白了!
日后也会推出其他算法结合注意力机制的模型,需要其他深度学习算法结合注意力模型的小伙伴也可以后台私信我~不过一旦推出新模型,价格肯定是会上涨的!所以需要创新或对比的小伙伴请早下手早超生!
代码获取
1.Attention全家桶获取方式(价格更划算!)
①点击下方小卡片,或后台回复关键词:注意力全家桶
2.CNN-Attention单品:
①点击下方小卡片,后台回复关键词,不区分大小写:CNNAttention
3.TCN-Attention单品:
①点击下方小卡片,后台回复关键词,不区分大小写:TCNAttention
4.BiGRU-Attention单品:
①点击下方小卡片,后台回复关键词,不区分大小写:BiGRUAttention
5.LSTM-Attention单品:
①点击下方小卡片,后台回复关键词,不区分大小写:LSTMAttention