相关代码见文末
1.概述
问题背景:
传统Seq2Seq模型的局限性: 早期的机器翻译和文本生成任务常采用基于循环神经网络(RNN)的序列到序列(Seq2Seq)模型,这类模型在处理长序列时容易遇到梯度消失/爆炸问题,导致训练效率低,难以捕捉长期依赖。
RNN网络的问题: RNN及其变种如LSTM和GRU在网络结构上的顺序执行特性限制了其并行计算能力,使得训练速度受限。此外,对于某些复杂语言结构的理解和生成不够高效和准确。
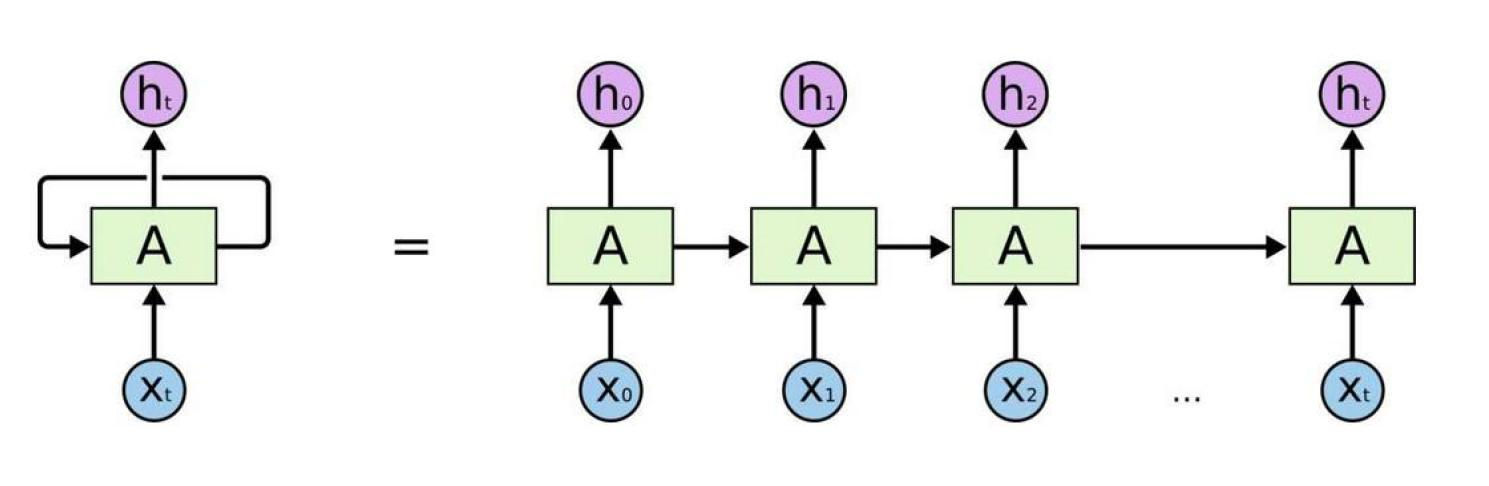
Word2Vec的局限性: 传统的词嵌入方法如Word2Vec虽然能有效学习单词的分布式表示,但它基于上下文独立的假设生成固定向量,无法体现单词在不同语境中的多义性。例如,“干哈那”这样的词语,在不同上下文中可能有完全不同的含义,但Word2Vec会为其分配一个固定的向量,不能灵活适应这些变化。
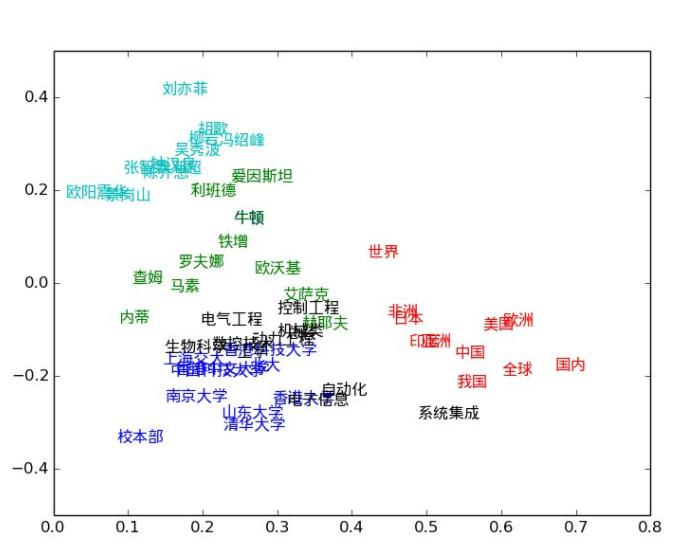
BERT的解决方案:
<