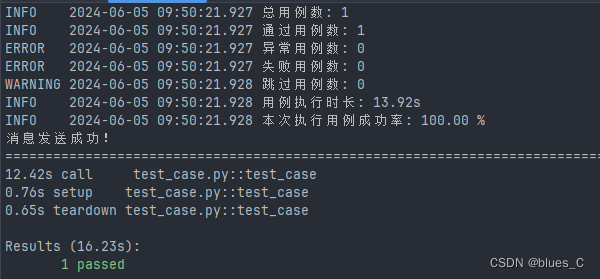
1.安装过程报错unable to sign certificate: must specify a CommonName
[root@node1 ~]# ./kk init registry -f config-sample.yaml -a kubesphere.tar.gz
_ __ _ _ __
| | / / | | | | / /
| |/ / _ _| |__ ___| |/ / ___ _ _
| \| | | | '_ \ / _ \ \ / _ \ | | |
| |\ \ |_| | |_) | __/ |\ \ __/ |_| |
\_| \_/\__,_|_.__/ \___\_| \_/\___|\__, |
__/ |
|___/
11:28:47 CST [GreetingsModule] Greetings
11:28:47 CST message: [node1]
Greetings, KubeKey!
11:28:47 CST success: [node1]
11:28:47 CST [UnArchiveArtifactModule] Check the KubeKey artifact md5 value
11:28:49 CST success: [LocalHost]
11:28:49 CST [UnArchiveArtifactModule] UnArchive the KubeKey artifact
11:28:49 CST skipped: [LocalHost]
11:28:49 CST [UnArchiveArtifactModule] Create the KubeKey artifact Md5 file
11:28:49 CST skipped: [LocalHost]
11:28:49 CST [RegistryPackageModule] Download registry package
11:28:49 CST message: [localhost]
downloading amd64 harbor v2.5.3 ...
11:28:56 CST message: [localhost]
downloading amd64 docker 24.0.6 ...
11:28:56 CST message: [localhost]
downloading amd64 compose v2.2.2 ...
11:28:56 CST success: [LocalHost]
11:28:56 CST [ConfigureOSModule] Get OS release
11:28:56 CST success: [node1]
11:28:56 CST [ConfigureOSModule] Prepare to init OS
11:28:57 CST success: [node1]
11:28:57 CST [ConfigureOSModule] Generate init os script
11:28:57 CST success: [node1]
11:28:57 CST [ConfigureOSModule] Exec init os script
11:28:58 CST stdout: [node1]
setenforce: SELinux is disabled
Disabled
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-arptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_local_reserved_ports = 30000-32767
net.core.netdev_max_backlog = 65535
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.core.somaxconn = 32768
net.ipv4.tcp_max_syn_backlog = 1048576
net.ipv4.neigh.default.gc_thresh1 = 512
net.ipv4.neigh.default.gc_thresh2 = 2048
net.ipv4.neigh.default.gc_thresh3 = 4096
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_max_tw_buckets = 1048576
net.ipv4.tcp_max_orphans = 65535
net.ipv4.udp_rmem_min = 131072
net.ipv4.udp_wmem_min = 131072
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.arp_accept = 1
net.ipv4.conf.default.arp_accept = 1
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.default.arp_ignore = 1
vm.max_map_count = 262144
vm.swappiness = 0
vm.overcommit_memory = 0
fs.inotify.max_user_instances = 524288
fs.inotify.max_user_watches = 524288
fs.pipe-max-size = 4194304
fs.aio-max-nr = 262144
kernel.pid_max = 65535
kernel.watchdog_thresh = 5
kernel.hung_task_timeout_secs = 5
11:28:58 CST success: [node1]
11:28:58 CST [ConfigureOSModule] configure the ntp server for each node
11:28:58 CST skipped: [node1]
11:28:58 CST [InitRegistryModule] Fetch registry certs
11:28:58 CST success: [node1]
11:28:58 CST [InitRegistryModule] Generate registry Certs
[certs] Using existing ca certificate authority
11:28:59 CST message: [LocalHost]
unable to sign certificate: must specify a CommonName
11:28:59 CST failed: [LocalHost]
error: Pipeline[InitRegistryPipeline] execute failed: Module[InitRegistryModule] exec failed:
failed: [LocalHost] [GenerateRegistryCerts] exec failed after 1 retries: unable to sign certificate: must specify a CommonName
解决办法
配置文件原因导致的,修改配置文件将注释打开
官网是注释掉的
这是官网的截取
registry:
# 如需使用 kk 部署 harbor, 可将该参数设置为 harbor,不设置该参数且需使用 kk 创建容器镜像仓库,将默认使用docker registry。
type: harbor
# 如使用 kk 部署的 harbor 或其他需要登录的仓库,可设置对应仓库的auths,如使用 kk 创建的 docker registry 仓库,则无需配置该参数。
# 注意:如使用 kk 部署 harbor,该参数请于 harbor 启动后设置。
#auths:
# "dockerhub.kubekey.local":
# username: admin
# password: Harbor12345
# 设置集群部署时使用的私有仓库
privateRegistry: ""
本地修改的
[root@node1 ~]#
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: sample
spec:
hosts:
1. {name: node1, address: 10.1.1.1, internalAddress: 10.1.1.1, user: root, password: "123456"}
roleGroups:
etcd:
- node1
control-plane:
- node1
worker:
- node1
registry:
- node1
controlPlaneEndpoint:
## Internal loadbalancer for apiservers
# internalLoadbalancer: haproxy
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.22.12
clusterName: cluster.local
autoRenewCerts: true
containerManager: docker
etcd:
type: kubekey
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
## multus support. https://github.com/k8snetworkplumbingwg/multus-cni
multusCNI:
enabled: false
registry:
type: harbor
domain: dockerhub.kubekey.local
tls:
selfSigned: true
certCommonName: dockerhub.kubekey.local
auths:
"dockerhub.kubekey.local":
username: admin
password: Harbor12345
privateRegistry: "dockerhub.kubekey.local"
namespaceOverride: "kubesphereio"
# privateRegistry: ""
# namespaceOverride: ""
registryMirrors: []
insecureRegistries: []
addons: []
2.报错显示缺少包
pull image failed: Failed to exec command: sudo -E /bin/bash -c "env PATH=$PATH docker pull dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1 --platform amd64"
downloading image: dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1
14:10:52 CST message: [node1]
pull image failed: Failed to exec command: sudo -E /bin/bash -c "env PATH=$PATH docker pull dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1 --platform amd64"
Error response from daemon: unknown: repository kubesphereio/pod2daemon-flexvol not found: Process exited with status 1
14:10:52 CST retry: [node1]
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/pause:3.5
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/kube-apiserver:v1.22.12
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/kube-controller-manager:v1.22.12
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/kube-scheduler:v1.22.12
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/kube-proxy:v1.22.12
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/coredns:1.8.0
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/k8s-dns-node-cache:1.15.12
14:10:57 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/kube-controllers:v3.26.1
14:10:58 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/cni:v3.26.1
14:10:58 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/node:v3.26.1
14:10:58 CST message: [node1]
downloading image: dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1
14:10:58 CST message: [node1]
pull image failed: Failed to exec command: sudo -E /bin/bash -c "env PATH=$PATH docker pull dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1 --platform amd64"
Error response from daemon: unknown: repository kubesphereio/pod2daemon-flexvol not found: Process exited with status 1
14:10:58 CST failed: [node1]
error: Pipeline[CreateClusterPipeline] execute failed: Module[PullModule] exec failed:
failed: [node1] [PullImages] exec failed after 3 retries: pull image failed: Failed to exec command: sudo -E /bin/bash -c "env PATH=$PATH docker pull dockerhub.kubekey.local/kubesphereio/pod2daemon-flexvol:v3.26.1 --platform amd64"
Error response from daemon: unknown: repository kubesphereio/pod2daemon-flexvol not found: Process exited with status 1
这是缺少安装包,外网下载然后本地导入
docker save -o pod2daemon-flexvo.tar registry.cn-beijing.aliyuncs.com/kubesphereio/pod2daemon-flexvo:v3.26.1
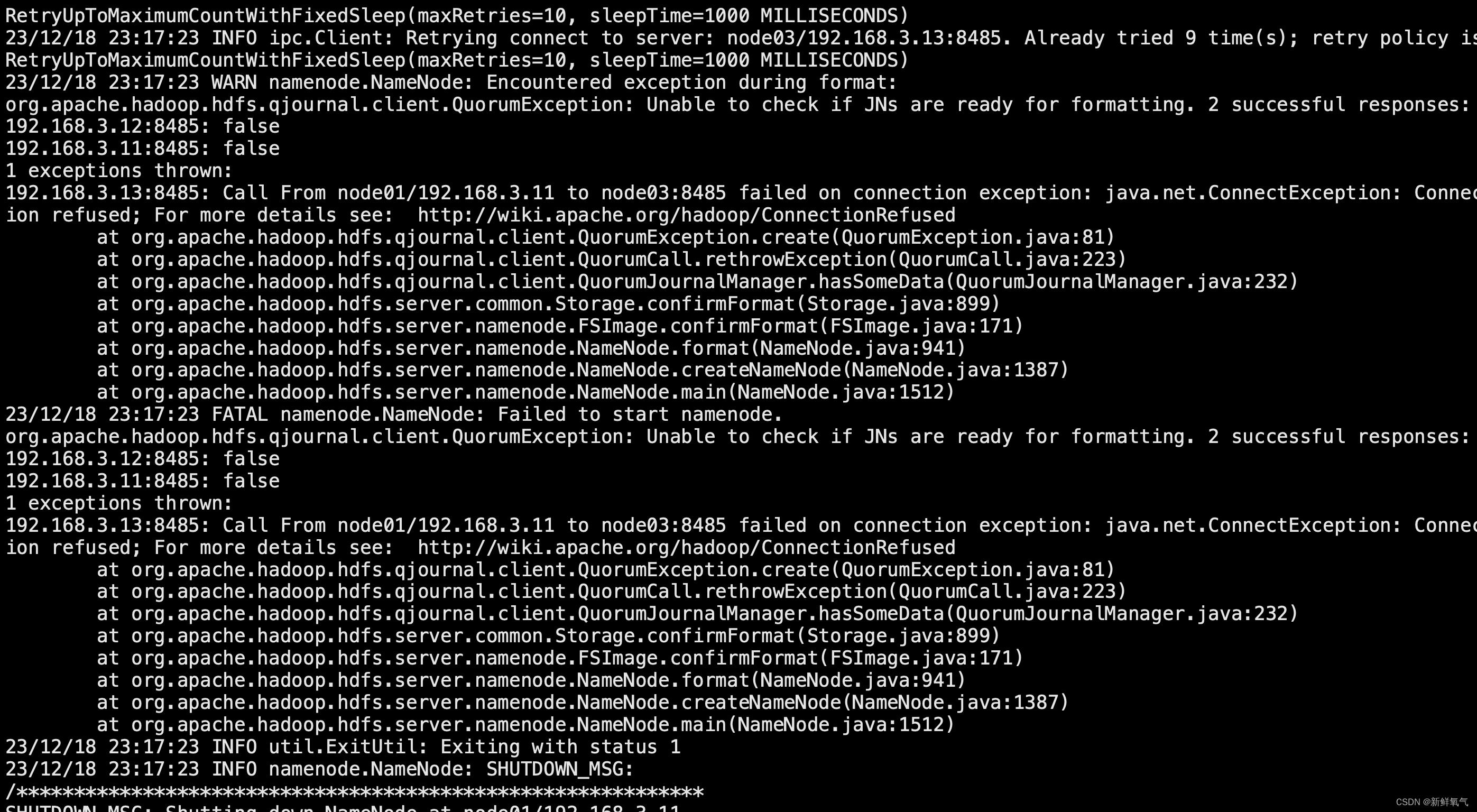
3、etcd x509 certificate is valid for 127.0.0.1 not 155.1.94.77 error
remote error tls bad certifcate servianem
13:10:44 CST [CertsModule] Generate etcd Certs
[certs] Using existing ca certificate authority
[certs] Using existing admin-node1 certificate and key on disk
[certs] Using existing member-node1 certificate and key on disk
[certs] Using existing node-node1 certificate and key on disk
13:10:44 CST success: [LocalHost]
13:10:44 CST [CertsModule] Synchronize certs file
13:10:46 CST success: [node1]
13:10:46 CST [CertsModule] Synchronize certs file to master
13:10:46 CST skipped: [node1]
13:10:46 CST [InstallETCDBinaryModule] Install etcd using binary
13:10:47 CST success: [node1]
13:10:47 CST [InstallETCDBinaryModule] Generate etcd service
13:10:47 CST success: [node1]
13:10:47 CST [InstallETCDBinaryModule] Generate access address
13:10:47 CST success: [node1]
13:10:47 CST [ETCDConfigureModule] Health check on exist etcd
13:10:47 CST skipped: [node1]
13:10:47 CST [ETCDConfigureModule] Generate etcd.env config on new etcd
13:10:48 CST success: [node1]
13:10:48 CST [ETCDConfigureModule] Refresh etcd.env config on all etcd
13:10:48 CST success: [node1]
13:10:48 CST [ETCDConfigureModule] Restart etcd
13:10:52 CST success: [node1]
13:10:52 CST [ETCDConfigureModule] Health check on all etcd
13:10:52 CST message: [node1]
etcd health check failed: Failed to exec command: sudo -E /bin/bash -c "export ETCDCTL_API=2;export ETCDCTL_CERT_FILE='/etc/ssl/etcd/ssl/admin-node1.pem';export ETCDCTL_KEY_FILE='/etc/ssl/etcd/ssl/admin-node1-key.pem';export ETCDCTL_CA_FILE='/etc/ssl/etcd/ssl/ca.pem';/usr/local/bin/etcdctl --endpoints=https://10.1.1.1:2379 cluster-health | grep -q 'cluster is healthy'"
Error: client: etcd cluster is unavailable or misconfigured; error #0: x509: certificate is valid for 127.0.0.1, ::1, 155.1.94.77, not 10.1.1.247
error #0: x509: certificate is valid for 127.0.0.1, ::1, 155.1.94.77., not 10.1.1.1: Process exited with status 1
13:10:52 CST retry: [node1]
这是因为旧版本的证书已经生成导致的证书有问题,删除文件里面生成的证书
删除这个路径下已经生成的证书/etc/ssl/etcd/ssl
使用./kk delete cluster,删除其他文件保留镜像images文件夹,建议删除先备份
4.May 31 15:48:14 node1 etcd[43663]: listen tcp 155.1.94.77:2380: bind: cannot assign requested address
不能绑定地址,是因为网段原因,实际ip是10.1.1.1,映射IP155段,需要用10段的ip才能绑定
May 31 15:48:14 node1 etcd[43663]: peerTLS: cert = /etc/ssl/etcd/ssl/member-node1.pem, key = /etc/ssl/etcd/ssl/member-node1-key.pem, trusted-ca = /etc/ssl/etcd/ssl/ca.pem, client-cert-auth = true, crl-file =
May 31 15:48:14 node1 etcd[43663]: listen tcp 155.1.94.77:2380: bind: cannot assign requested address
May 31 15:48:14 node1 systemd[1]: etcd.service: main process exited, code=exited, status=1/FAILURE
May 31 15:48:14 node1 systemd[1]: Failed to start etcd.
-- Subject: Unit etcd.service has failed
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit etcd.service has failed.
--
-- The result is failed.
5.离线安装需要harbor配置仓库名
执行配置文件
[root@node1 ~]# ./create_project_harbor.sh
bash: ./create_project_harbor.sh: /bin/bash^M: bad interpreter: No such file or directory
这是因为格式原因,里面有空格不能识别
sed -i "s/\r//" create_project_harbor.sh
5.执行安装集群报错需要rhel-7.5-amd64.iso
./kk create cluster -f config-sample.yaml -a kubesphere.tar.gz --with-packages
–with-packages:若需要安装操作系统依赖,需指定该选项。
报错显示需要rhel-7.5-amd64.iso 系统,
rhel是商业操作系统 建议自己把依赖装好 conntrack socat 这两装上就行了 然后安装的时候不要加 –wit-packages
6.执行创建集群报错
W0603 11:26:02.921549 60122 utils.go:69] The recommended value for "clusterDNS" in "KubeletConfiguration" is: [10.233.0.10]; the provided value is: [169.254.25.10]
[init] Using Kubernetes version: v1.22.12
[preflight] Running pre-flight checks
[WARNING FileExisting-socat]: socat not found in system path
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.6. Latest validated version: 20.10
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileExisting-conntrack]: conntrack not found in system path #缺少组件
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
11:26:03 CST stdout: [node1]
[preflight] Running pre-flight checks
W0603 11:26:03.194656 60202 removeetcdmember.go:80] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
W0603 11:26:03.198708 60202 cleanupnode.go:109] [reset] Failed to evaluate the "/var/lib/kubelet" directory. Skipping its unmount and cleanup: lstat /var/lib/kubelet: no such file or directory
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
11:26:03 CST message: [node1]
init kubernetes cluster failed: Failed to exec command: sudo -E /bin/bash -c "/usr/local/bin/kubeadm init --config=/etc/kubernetes/kubeadm-config.yaml --ignore-preflight-errors=FileExisting-crictl,ImagePull"
报错缺少安装文件
socat not found in system path
- 这是一个警告,说明你的系统中没有找到socat这个工具。socat是一个多功能的网络工具,尽管在kubeadm的预检查中它可能不是必需的,但建议最好还是安装它,因为它可能在某些操作中被使用到。
Docker version is not on the list of validated versions
- 这也是一个警告,表示你当前使用的Docker版本(24.0.6)并不在kubeadm官方验证过的Docker版本列表中。虽然这个警告不一定会阻止kubeadm的操作,但建议使用一个经过验证的Docker版本(如20.10),以避免潜在的问题。
contrack not found in system path
- 这是一个错误,表示kubeadm在预检查阶段没有找到contrack这个命令。但通常我们使用的应该是conntrack,它是Linux内核用来跟踪网络连接的工具。你可能需要安装或检查conntrack-tools包是否已正确安装在你的系统上。
kubeadm reset 相关输出
- 在重置过程中,kubeadm会尝试停止kubelet服务、卸载挂载的目录、删除Kubernetes的配置文件和状态目录。从日志来看,kubeadm成功地删除了部分文件和目录,但遇到了对/var/lib/kubelet目录评估失败的问题(可能是因为该目录不存在或不可访问)。
CNI配置和iptables/IPVS表未清理
- 重置过程不会清理CNI(容器网络接口)配置和iptables/IPVS表。如果你需要清理这些,你需要手动执行相关命令。
yum -y install conntrack-tools
yum -y install socat
7、报错因为是挂在文件找不到,在创建集群初始化calico一直等待,超时失败报错日志
kubelet MountVolume.SetUp failed for volume “bpffs” : hostPath type check failed: /sys/fs/bpf is not a directory
14:17:31 CST message: [node1]
Default storageClass in cluster is not unique!
14:17:31 CST skipped: [node1]
14:17:31 CST [DeployStorageClassModule] Deploy OpenEBS as cluster default StorageClass
14:17:31 CST message: [node1]
Default storageClass in cluster is not unique!
14:17:31 CST skipped: [node1]
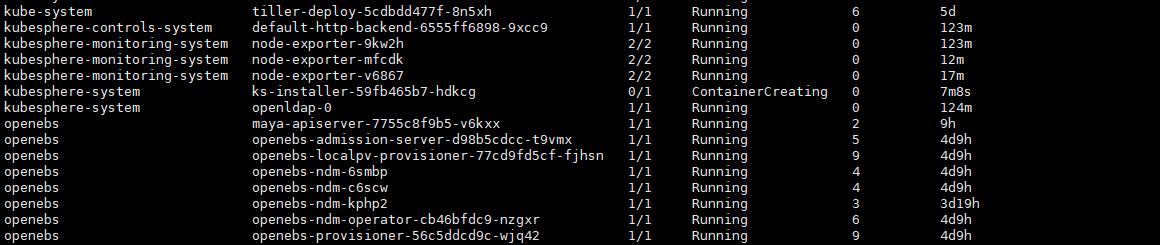
#查看pod
[root@node1 logs]# kubectl get po -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-769bbc4c9-2smqd 0/1 Pending 0 4h39m <none> <none> <none> <none>
kube-system calico-node-hsj57 0/1 Init:0/3 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system coredns-558b97598-d6v2c 0/1 Pending 0 4h39m <none> <none> <none> <none>
kube-system coredns-558b97598-gqwh4 0/1 Pending 0 4h39m <none> <none> <none> <none>
kube-system kube-apiserver-node1 1/1 Running 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system kube-controller-manager-node1 1/1 Running 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system kube-proxy-c4tg9 1/1 Running 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system kube-scheduler-node1 1/1 Running 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system nodelocaldns-kcz4p 1/1 Running 0 4h39m 10.1.1.1 node1 <none> <none>
kube-system openebs-localpv-provisioner-7869648cbc-cls8s 0/1 Pending 0 4h39m <none> <none> <none> <none>
kubesphere-system ks-installer-6c6c47d8f8-jnzj9 0/1 Pending 0 4h39m <none> <none> <none> <none>
#查看日志
kubectl describe pod calico-node-hsj57 -n kube-system
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedMount 7m6s (x117 over 4h27m) kubelet MountVolume.SetUp failed for volume "bpffs" : hostPath type check failed: /sys/fs/bpf is not a directory
Warning FailedMount 2m33s (x128 over 4h7m) kubelet (combined from similar events): Unable to attach or mount volumes: unmounted volumes=[bpffs], unattached volumes=[policysync kube-api-access-xqn6h var-run-calico bpffs host-local-net-dir lib-modules cni-log-dir cni-bin-dir xtables-lock var-lib-calico cni-net-dir sys-fs nodeproc]: timed out waiting for the condition
[root@node1 logs]# ls -ld /sys/fs/bpf
ls: cannot access /sys/fs/bpf: No such file or directory
[root@node1 logs]# cat /boot/config/-$(uname -r)| grep CONFIG_BPF
cat: /boot/config/-3.10.0-862.el7.x86_64: No such file or directory
[root@node1 logs]# cat /boot/config-$(uname -r)| grep CONFIG_BPF
CONFIG_BPF_JIT=y
是因为不支持挂载的功能,这跟内核版本有关 linux版本cnetos7.5
centos7.8版本
[root@node1 cert]# cat /boot/config-$(uname -r) | grep CONFIG_BPF
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
要重新安装系统内核
8报错failed to create network harbor_harbor error response for daemon
failed to setup ip tables:unable to enable skip DNAT rule 重启docker解决
systemctl start docker
























![[图解]企业应用架构模式2024新译本讲解11-领域模型4](https://img-blog.csdnimg.cn/direct/c1af0c61336243618e07696d663d1976.png)





![[经验] 房地产企业印花税的计税依据是什么 #媒体#知识分享#其他](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fwww.hao123rr.com%2Fzb_users%2Fcache%2Fly_autoimg%2F%25E6%2588%25BF%25E5%259C%25B0%25E4%25BA%25A7%25E4%25BC%2581%25E4%25B8%259A%25E5%258D%25B0%25E8%258A%25B1%25E7%25A8%258E%25E7%259A%2584%25E8%25AE%25A1%25E7%25A8%258E%25E4%25BE%259D%25E6%258D%25AE%25E6%2598%25AF%25E4%25BB%2580%25E4%25B9%2588.jpg&pos_id=yGc3X0nG)