前言
之前虽然了解过 Transformer 架构,但是没有自己实现过。
最近阅读 transformers 库中 Llama 模型结构,于是想试着亲手实现一个简单的 Transformer。
在实现过程中加深了理解,同时发现之前阅读 Llama 中一些错误的地方,因此做一个记录。
笔者小白,如果实现过程中存在错误,请不吝指出。
Embedding
Embedding 可以将高维的离散文本数据映射到低维的连续向量空间。这不仅减小了输入数据的维度,也有助于减少数据的稀疏性,提高模型的性能和效率。
同时,词嵌入可以捕捉单词之间的语义关系,相似的单词在嵌入空间中会更接近。
使用 Pytorch 可以很方便定义出 Embedding 模型:
class Embedder(nn.Module):
def __init__(self, vocab_size: int, d_model: int) -> None:
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.embed(x)
Positional Encoding
Transformer 中没有类似 RNN 的循环机制,需要通过位置编码记录单词的位置和顺序。
其计算位置编码的公式如下:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos,2i)}=sin(\frac{pos}{10000^{2i/d_{model}}})PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{2i/d_{model}}})PE(pos,2i+1)=cos(100002i/dmodelpos)
其中 pospospos 是位置,而 iii 是维度。
Pytorch 实现位置编码器代码如下:
class PositionalEncoder(nn.Module):
def __init__(
self, d_model: int = 512, max_seq_len: int = 2048, base: int = 10000
) -> None:
super().__init__()
self.d_model = d_model
inv_freq_half = 1.0 / (
base ** (torch.arange(0, d_model, 2, dtype=torch.float) / d_model)
)
inv_freq = torch.arange(0, d_model, dtype=inv_freq_half.dtype)
inv_freq[..., 0::2] = inv_freq_half
inv_freq[..., 1::2] = inv_freq_half
pos = torch.arange(max_seq_len, dtype=inv_freq.dtype)
pe = torch.einsum("i, j -> ij", pos, inv_freq)
pe[..., 0::2] = pe[..., 0::2].sin()
pe[..., 1::2] = pe[..., 1::2].cos()
self.register_buffer("pe", pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 使 embedding 相对大一些
x = x * math.sqrt(self.d_model)
seq_len = x.shape[1]
pe = self.pe[:seq_len].to(dtype=x.dtype)
return x + pe
在 PyTorch 中,nn.Module 类中的 register_buffer() 方法用于将一个张量(或缓冲区)注册为模型的一部分。
注册的缓冲区不会参与模型的梯度计算,但会在模型的保存和加载时保持状态。
register_buffer() 的主要作用是在模型中保留一些不需要梯度更新的状态。
在前向传播中加入位置编码前扩大 embedding 的值,是为了保证原始语言信息不会因为加入位置信息而丢失。
Mask
Mask 在 Transformer 中有很重要的作用:
- 在 Encoder 和 Decoder 中,Mask 会遮住用于 Padding 的位置。
- 在 Decoder 中,Mask 会遮住预测剩余位置,防止 Dcoder 提前得到信息。
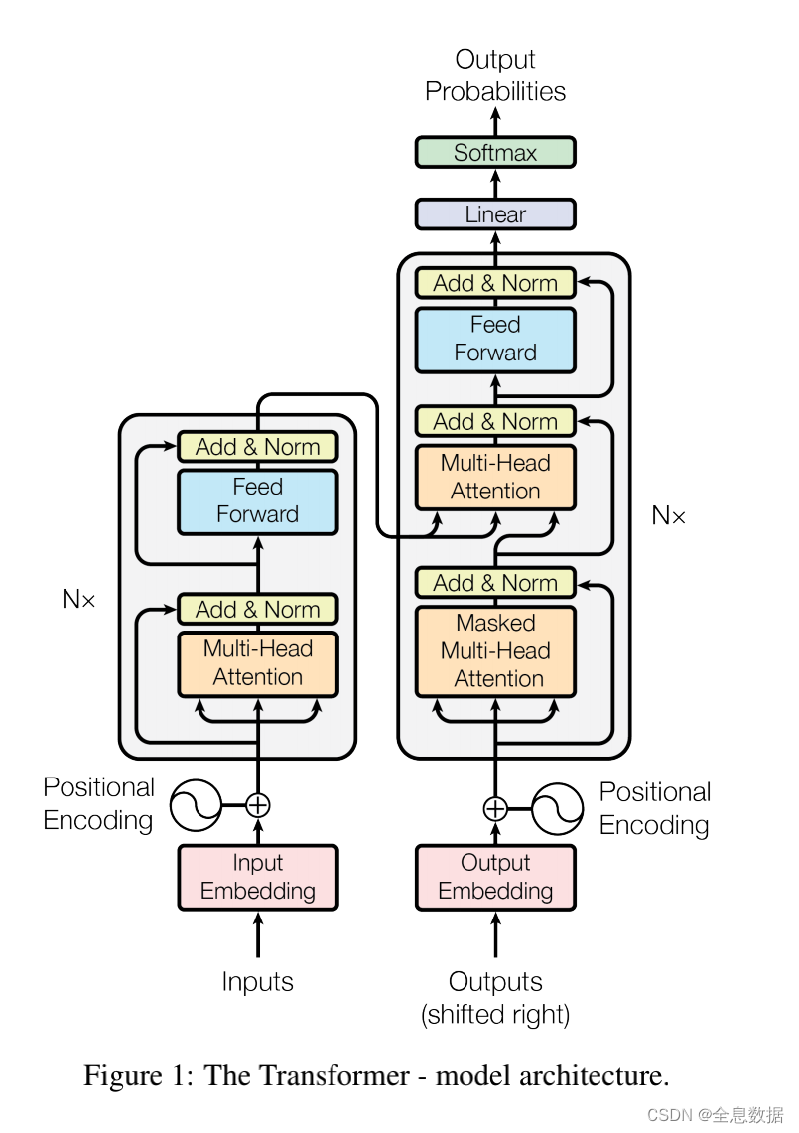
Multi-Headed Attention
多头注意力是 Transformer 中的核心模块,它们网络结构如下:
在多头注意力中,会将 embedding 分割为 hhh 个头,每个头的维度为 dmodel/hd_{model} / hdmodel/h。
In this work we employ h=8h = 8h=8 parallel attention layers, or heads. For each of these we use dkd_kdk = dvd_vdv = dmodel/hd_{model}/hdmodel/h = 64.
多头注意力公式如下:
MultiHead(Q,K,V)=Concat(head1,…,headn)WOMultiHead(Q,K,V)=Concat(head_1,…,head_n)W^OMultiHead(Q,K,V)=Concat(head1,…,headn)WO
headi=Attention(QWiQ,KWiK,VWiV)head_i=Attention(QW_iQ,KW_iK,VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)
多头注意力代码如下:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, heads: int = 8, dropout: int = 0.1) -> None:
super().__init__()
self.d_model = d_model
self.heads = heads
self.d_k = self.d_model // self.heads
if self.heads * self.d_k != self.d_model:
raise ValueError(
f"d_model must be divisible by heads (got `d_model`: {self.d_model}"
f" and `heads`: {self.heads})."
)
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.o_proj = nn.Linear(d_model, d_model)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: Optional[torch.Tensor] = None,
):
bsz = q.shape[0]
# translate [bsz, seq_len, d_model] to [bsz, seq_len, heads, d_k]
q = self.q_proj(q).view(bsz, -1, self.heads, self.d_k)
k = self.k_proj(k).view(bsz, -1, self.heads, self.d_k)
v = self.v_proj(v).view(bsz, -1, self.heads, self.d_k)
# translate [bsz, seq_len, heads, d_k] to [bsz, heads, seq_len, d_k]
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# calculate attention
scores = attention(q, k, v, self.d_k, mask, self.dropout)
# cat multi-heads
concat = scores.transpose(1, 2).contiguous().view(bsz, -1, self.d_model)
output = self.o_proj(concat)
return output
注意力计算公式为:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dkQKT)V
其中计算注意力的代码如下:
def attention(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
d_k: int,
mask: Optional[torch.Tensor] = None,
dropout: Optional[nn.Dropout] = None,
) -> torch.Tensor:
# calculate the scores
# q: [bsz, heads, seq_len, d_k]
# k: [bsz, heads, d_k, seq_len]
scores = torch.matmul(q, k.transpose(-1, -2)) / torch.sqrt(d_k)
if mask is not None:
# tanslate [bsz, seq_len, seq_len] to [bsz, 1, seq_len, seq_len]
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
The Feed-Forward Network
Feed-Forward 由两个线性变换和一个激活函数构成。
This consists of two linear transformations with a ReLU activation in between.
其公式如下:
FFN=max(0,xW1+b1)W2+b2FFN=max(0,xW_1+b_1)W_2+b_2FFN=max(0,xW1+b1)W2+b2
该网络中输入输出维度为 512,中间线性层维度为 2048。
The dimensionality of input and output is dmodel=512d_{model} = 512dmodel=512, and the inner-layer has dimensionality dff=2048d_{ff} = 2048dff=2048.
实现代码如下:
class FeedForward(nn.Module):
def __init__(
self, d_model: int = 512, d_ff: int = 2048, dropout: float = 0.1
) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
Norm
正则化可以防止数据在不同网络中流动时范围差距过大,保证模型稳定性。
实现代码如下:
class Norm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-6) -> None:
super().__init__()
self.dim = d_model
self.alpha = nn.Parameter(torch.ones(self.dim))
self.bias = nn.Parameter(torch.zeros(self.dim))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
norm = (
self.alpha
* (x - x.mean(dim=-1, keepdim=True))
/ (x.std(dim=-1, keepdim=True) + self.eps)
+ self.bias
)
return norm
Assemble
Transformer 由多个 EncoderLayer 和 DecoderLayer 组合在一起,首先实现 EncoderLayer。
[注意] 在每个子层输出和下一个子层输入以及正则化前,有一层 dropout。
We apply dropout [33] to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of Pdrop = 0.1
EncoderLayer 实现代码如下:
class EncoderLayer(nn.Module):
def __init__(
self, d_model: int = 512, heads: int = 8, d_ff: int = 2048, dropout: float = 0.1
) -> None:
super().__init__()
self.attn = MultiHeadAttention(d_model, heads, dropout)
self.dropout_1 = nn.Dropout(dropout)
self.norm_1 = Norm(d_model)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.dropout_2 = nn.Dropout(dropout)
self.norm_2 = Norm(d_model)
def forward(
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
) -> torch.Tensor:
x = x + self.dropout_1(self.attn(x, x, x, mask))
x = self.norm_1(x)
x = x + self.dropout_2(self.ffn(x))
x = self.norm_2(x)
return x
DecoderLayer 实现代码如下:
class DecoderLayer(nn.Module):
def __init__(
self, d_model: int = 512, heads: int = 8, d_ff: int = 2048, dropout: float = 0.1
) -> None:
super().__init__()
self.attn_1 = MultiHeadAttention(d_model, heads, dropout)
self.dropout_1 = nn.Dropout(dropout)
self.norm_1 = Norm(d_model)
self.attn_2 = MultiHeadAttention(d_model, heads, dropout)
self.dropout_2 = nn.Dropout(dropout)
self.norm_2 = Norm(d_model)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.dropout_3 = nn.Dropout(dropout)
self.norm_3 = Norm(d_model)
def forward(
self,
x: torch.Tensor,
enc_output: torch.Tensor,
src_mask: torch.Tensor,
tgt_mask: torch.Tensor,
) -> torch.Tensor:
x = x + self.dropout_1(self.attn_1(x, x, x, tgt_mask))
x = self.norm_1(x)
x = x + self.dropout_2(self.attn_2(x, enc_output, enc_output, src_mask))
x = self.norm_2(x)
x = x + self.dropout_3(self.ffn(x))
x = self.norm_3(x)
return x
Encoder 和 Decoder 分别由 N 个 EncoderLayer 和 DecoderLayer 组成。
代码实现如下:
class Encoder(nn.Module):
def __init__(
self,
vocab_size: int,
N: int = 6,
d_model: int = 512,
max_seq_len: int = 2048,
heads: int = 8,
d_ff: int = 2048,
dropout: float = 0.1,
) -> None:
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, max_seq_len)
self.layers = nn.ModuleList(
[EncoderLayer(d_model, heads, d_ff, dropout) for _ in range(N)]
)
def forward(self, src: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
x = self.embed(src)
x = self.pe(x)
for layer in self.layers:
x = layer(x, mask)
return x
class Decoder(nn.Module):
def __init__(
self,
vocab_size: int,
N: int = 6,
d_model: int = 512,
max_seq_len: int = 2048,
heads: int = 8,
d_ff: int = 2048,
dropout: float = 0.1,
) -> None:
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, max_seq_len)
self.layers = nn.ModuleList(
[DecoderLayer(d_model, heads, d_ff, dropout) for _ in range(N)]
)
def forward(
self,
tgt: torch.Tensor,
enc_output: torch.Tensor,
src_mask: torch.Tensor,
tgt_mask: torch.Tensor,
) -> torch.Tensor:
x = self.embed(tgt)
x = self.pe(x)
for layer in self.layers:
x = layer(x, enc_output, src_mask, tgt_mask)
return x
最后组装成 Transformer!
class Transformer(nn.Module):
def __init__(
self,
src_vocab: int,
tgt_vocab: int,
N: int = 6,
d_model: int = 512,
max_seq_len: int = 2048,
heads: int = 8,
d_ff: int = 2048,
dropout: float = 0.1,
) -> None:
super().__init__()
self.encoder = Encoder(src_vocab, N, d_model, max_seq_len, heads, d_ff, dropout)
self.decoder = Decoder(tgt_vocab, N, d_model, max_seq_len, heads, d_ff, dropout)
self.out = nn.Linear(d_model, tgt_vocab)
def forward(
self,
src: torch.Tensor,
tgt: torch.Tensor,
src_mask: torch.Tensor,
tgt_mask: torch.Tensor,
) -> torch.Tensor:
enc_output = self.encoder(src, src_mask)
dec_output = self.decoder(tgt, enc_output, src_mask, tgt_mask)
output = F.softmax(self.out(dec_output), dim=-1)
return output
Test
测试一下代码能不能运行,按照如下配置测试:
from transformer_scratch import Transformer
import torch
bsz = 4
max_seq_len = 1024
src_vocab = 128
tgt_vocab = 64
N = 3
d_ff = 512
model = Transformer(src_vocab, tgt_vocab, N=N, max_seq_len=max_seq_len, d_ff=d_ff)
src = torch.randint(low=0, high=src_vocab, size=(bsz, max_seq_len))
tgt = torch.randint(low=0, high=tgt_vocab, size=(bsz, max_seq_len))
src_mask = torch.ones(size=(bsz, max_seq_len, max_seq_len))
tgt_mask = torch.ones(size=(bsz, max_seq_len, max_seq_len))
res = model(src, tgt, src_mask, tgt_mask)
print(f"Output data shape is: {res.shape}")
输出:Output data shape is: torch.Size([4, 1024, 64])
Reference
在编写过程中参考下面的博客,感谢大佬分享自己的经验。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。



























![[C#]使用OpenCvSharp图像滤波中值滤波均值滤波高通滤波双边滤波锐化滤波自定义滤波](https://img-blog.csdnimg.cn/direct/a4d6680252384ddfbc8c001467e75f89.png)





