用十六进制对特定字符编码,利用百分号标识搜索字符串解码十六进制字符。
(笔记模板由python脚本于2024年06月09日 18:05:25创建,本篇笔记适合喜好探寻URL的coder翻阅)
Python 官网:https://www.python.org/
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
地址:https://lqpybook.readthedocs.io/
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
- My CSDN主页、My HOT博、My Python 学习个人备忘录
- 好文力荐、 老齐教室

本文质量分:
本文地址: https://blog.csdn.net/m0_57158496/
CSDN质量分查询入口:http://www.csdn.net/qc
- ◆ URL的编码解码(一)
-
- 1、需要编码的URL字符集
- 2、ASCII字符集
- 3、主机域名限制
- 4、url解码
-
- 4.1 解码函数
- 4.2 代码解析
- 5、URL编码
-
- 5.1 编码函数
- 5.2 代码解析
- 6、完整源码(Python)
◆ URL的编码解码(一)
1、需要编码的URL字符集
需要编码的URL字符集,通常包括那些在URL中有特殊意义的字符,以及非ASCII字符。这些字符需要被编码,以便URL可以正确地被解析和传输。
以下是需要编码的字符集的详细列表:
- 非ASCII字符:任何非ASCII字符都需要被编码,因为URL标准是基于ASCII字符集的。(由于非ascii字符的编码解码,相对复杂一些,请见我的专门讨论笔记:《非ASCII码的编码》,本篇笔记仅讨论ascii字符的编码解码。)
- 保留字符:即使某些字符在URL的特定部分是允许的,但如果它们用于其他目的,也需要被编码。这些字符包括:
;(%3B)/(%2F)?(%3F):(%3A)@(%40)&(%26)=(%3D)+(%2B)$(%24),(%2C)
- 不安全字符:这些字符在URL中有特殊意义,或者在某些情况下可能导致URL解析错误。它们包括:
(空格) 被编码为%20或+"(%22)<(%3C)>(%3E)#(%23)%(%25){(%7B)}(%7D)|(%7C)\\(%5C)^(%5E)~(%7E)[(%5B)](%5D)"(%22)'(%27)((%28))(%29)
- 控制字符:ASCII码中的控制字符(0-31和127)通常也被编码,因为它们可能在传输过程中被某些系统错误处理。
在URL编码过程中,这些字符通常被替换为%后跟两位十六进制数,代表该字符的ASCII码。例如,空格字符(ASCII码为32)被编码为%20。在某些情况下,+也可以用来代替空格,但这通常只适用于表单提交中的URL编码,而不是在HTTP GET请求的URL中。
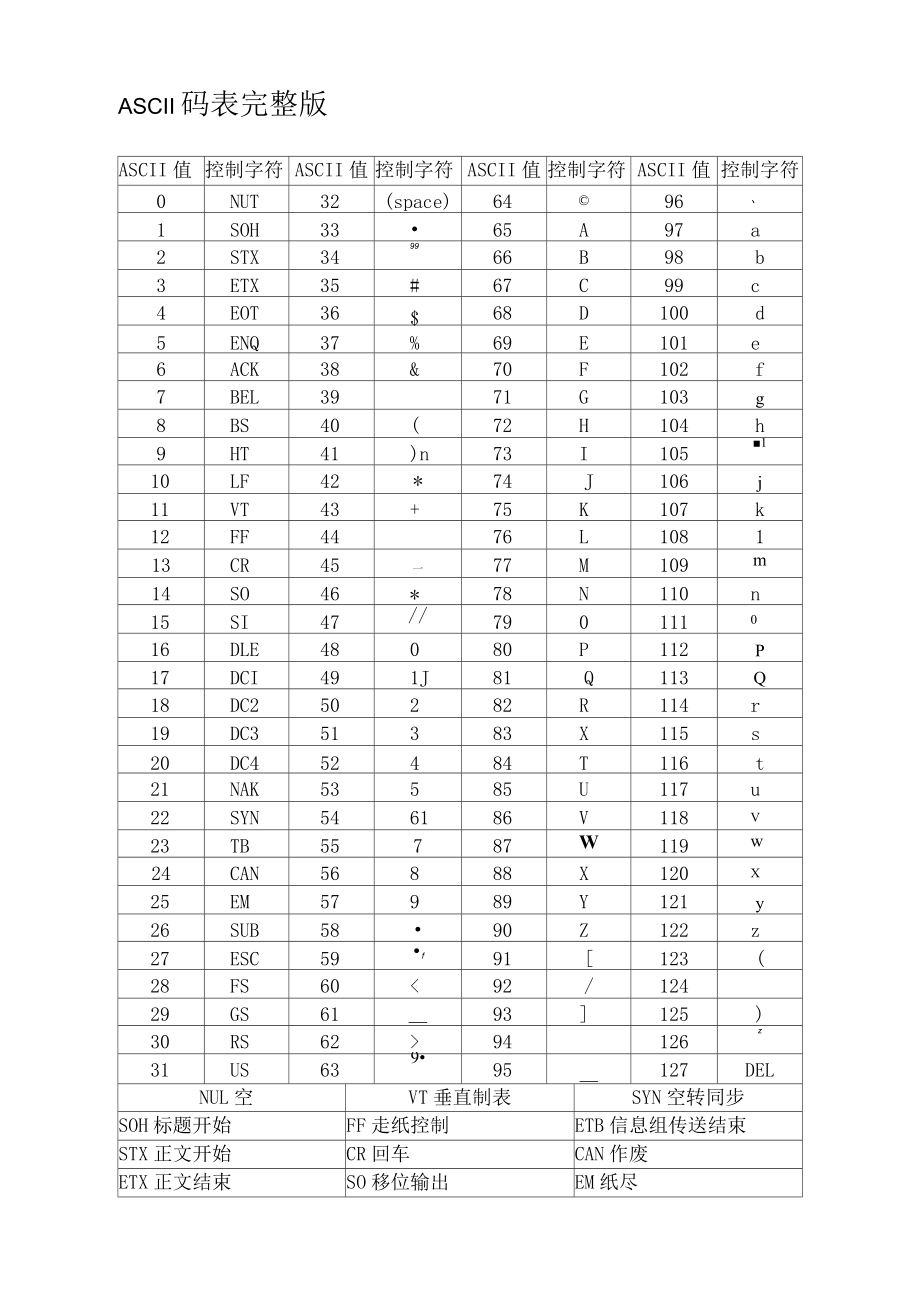
2、ASCII字符集
ASCII(美国信息交换标准代码)字符集总共包含128个字符。这些字符包括:
95个可打印字符:大小写字母A-Z、a-z、数字0-9、标点符号和其它符号。
33个非打印控制字符:用于控制打印机等硬件设备或提供数据流的控制。
这些字符被用于早期的计算机系统中,现在虽然已被更广泛的字符集如Unicode所取代,但ASCII仍然是计算机历史上一个重要的里程碑。
ASCII码的95个可打印字符
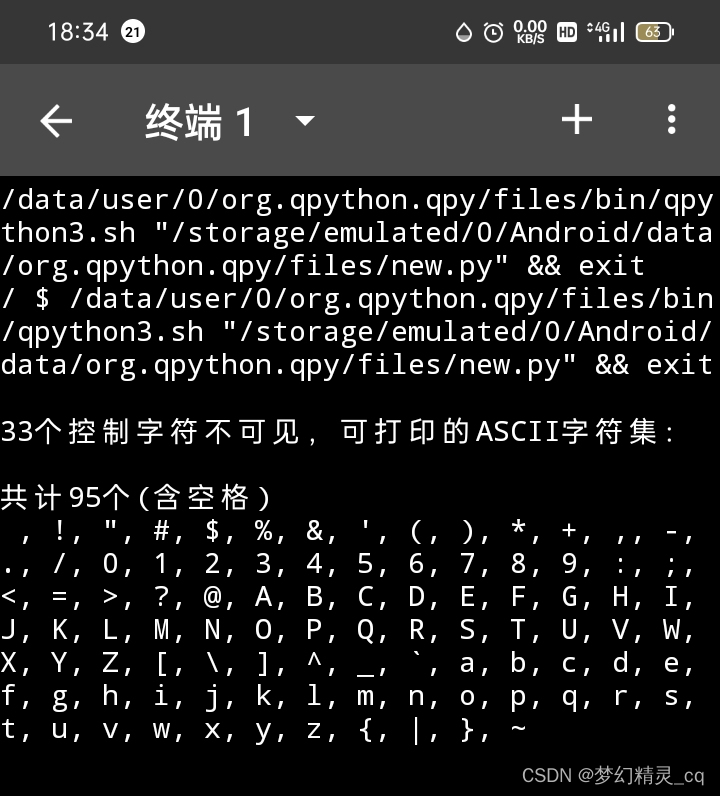
ASCII字符集共计128,除去0到31和127为控制码,这33个字符必须编码。另有保留字符10个,不安全字符18个,另有a-zA-Z大小写字母52个和10数字0-9可以不用编码外,不用编码的其它字符仅有 5 5 5个(128-33-28-62 = 5)而已。这5个字符,编不编码对浏览器解析url都没有影响。
鉴于此,为简单起见,不去纠结它们到底是哪几个字符,都给一并编码。这样子,就是字母数字不编码,设计代码实现逻辑,就不难了。🤪
3、主机域名限制
URL中的主机域名字符串有一些特定的限制,这些限制是由互联网标准和协议决定的。
以下是一些主要的限制:
- 字符集限制:域名可以包含字母(A-Z,不区分大小写)、数字(0-9)和连字符(-)。域名不区分大小写,但在域名系统中注册时,每个标签(由点分隔的部分)会被转换为小写。
- 长度限制:域名的总长度不能超过253个字符,包括点分隔符。每个标签(域名的部分)的长度不能超过63个字符。
- 标签限制:域名不能以连字符开头或结尾。
- 特殊字符:除了字母、数字和连字符外,域名中不允许使用其他特殊字符,如空格、百分号、下划线等。
- 顶级域名:域名必须有一个顶级域名(TLD),如.com、.org、.net等,并且TLD必须在ICANN(互联网名称与数字地址分配机构)或相应国家代码顶级域(ccTLD)的官方列表中。
- 国际化域名:虽然传统的域名只允许ASCII字符,但国际化域名(IDN)允许使用非ASCII字符,如中文、阿拉伯文等。这些字符会被转换为ASCII兼容的编码形式(Punycode)。
这些限制确保了域名在全球范围内的唯一性和可互操作性。遵守这些规则对于确保网站的正常访问和DNS(域名系统)的稳定运行至关重要。
大多数url仅包括主机域名和路径,路径一般都是用英文字符,因此仅对csaii字符编码解码,已可以应付大部分url。
4、url解码
url解码,就是把编码url中紧跟%后的两个十六进制字符,还原成ascii码。由于本文探讨的仅是ascii码的单字节字符,代码实现逻辑超强简单。只需用while循环遍历url字符串,将有编码过的十六进制字符还原就好了。
4.1 解码函数
Python代码
url = "https://blink.csdn.net/m/details/1714315?csdn_share_tail=%7B%22type%22%3A%22blink%22,%22rType%22%3A%22blink%22,%22rId%22%3A%221714315%22,%22source%22%3A%22m0_57158496%22%7D"
def charDecode(chars: str, char: str, k: int) -> tuple:
return (chr(int(chars[k+1:k+3],16)), k+3) if char == '%' else (char, k+1) # 如果有编码则解码返回,并更新检索url下标变量k
def urlDecode(url: str) -> str:
urlList = []; k = 0; n = len(url)
while k < n:
char, k = charDecode(url, url[k], k) # 函数返回解码字符并更新url遍历检索下标。
urlList += [char] # 追加收集已解码字符
return ''.join(urlList) # 拼接解码后的url字符串返回
if __name__ == '__main__':
strDecode = urlDecode(url)
print(f"\n编码Url:\n{url}\n\n解码后;\n{strDecode}")
代码运行效果截屏图片
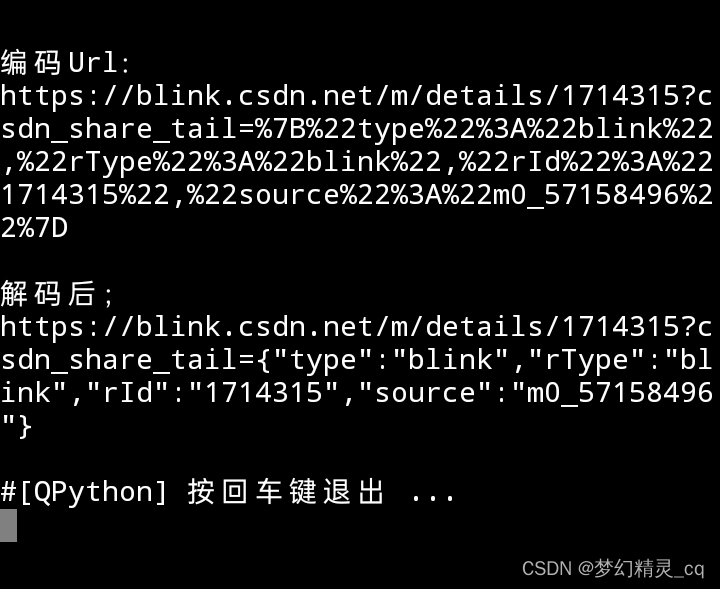
如图所见,程序函数把有编码的字符都还原成了ascii码。
4.2 代码解析
这段代码的目的是实现URL解码功能:
让我们逐步分析这段代码:
charDecode函数
这个函数接受三个参数:chars(要解码的字符串),char(当前字符),和k(当前字符在字符串中的索引)。如果当前字符是%,它假设接下来的两个字符是十六进制数,代表一个字符的ASCII码。函数将这些十六进制数转换为对应的字符,并返回这个字符以及更新后的索引k(增加3,因为跳过了%和两个十六进制数字符)。如果当前字符不是%,它就直接返回这个字符和下一个索引k+1。urlDecode函数
这个函数接受一个参数url(要解码的URL字符串)。它初始化一个空列表urlList来存储解码后的字符,以及一个变量k来跟踪当前字符的索引。函数遍历整个URL字符串,对每个字符调用charDecode函数进行解码,并将解码后的字符添加到urlList中。最后,它使用join方法将urlList中的所有字符拼接成一个字符串,并返回这个字符串。if __name__ == '__main__':
这部分是Python代码的常见结构,用于检测该脚本是否作为主程序运行。如果是,它将执行下面的代码。strDecode = urlDecode(url)
这行代码调用urlDecode函数,将提供的URL字符串解码,并将结果存储在变量strDecode中。print(f"\n编码Url:\n{url}\n\n解码后;\n{strDecode}")
这行代码打印出原始的编码URL和解码后的URL。
总结:
这段代码提供了一个简单的URL解码实现,可以处理包含十六进制编码字符的URL。它首先定义了一个辅助函数来解码单个字符,然后使用这个函数来解码整个URL字符串。
5、URL编码
URL编码,就是把url中不适宜的字符用%后接两个十六进制字符的形式。由于本文探讨的仅是ascii码的单字节字符,代码实现逻辑相对简单。只需用while循环遍历url字符串,将有编码需求的字符转换就好。
5.1 编码函数
Python代码
## 编码 ##
def charEncode(chars: str, char: str, k: int) -> tuple:
chars = set('abcdefghijklmnopqrstuvwxyzABCDRFGHIJKLMNOPQRSTUVWXYZ0123456789') # 不用url编码字符集
return (char, k+1) if char in chars else (f"%{hex(ord(char))[2:].upper()}", k+1)
def urlEncode(url: str) -> str:
urlList = []; k = 0; n = len(url)
while k < n:
char, k = charEncode(url, url[k], k)
urlList += [char]
return ''.join(urlList)
代码运行效果截屏图片
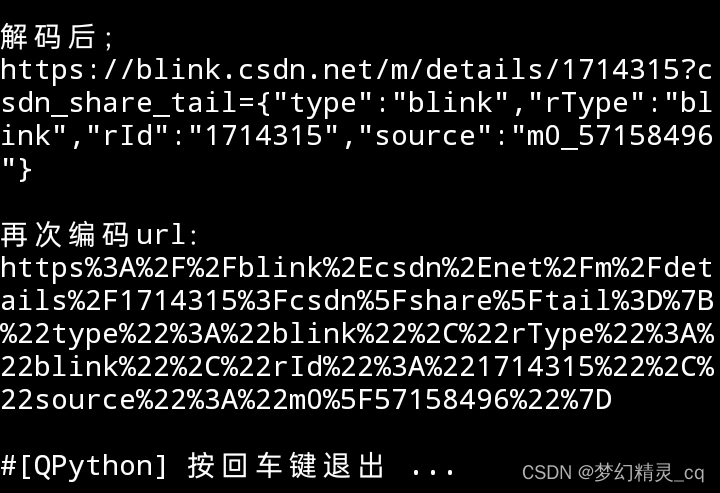
把:、/、.、?也一并编码了。😅😅这是一个 意 外 意外 意外。😋😋
修正代码
## 编码 ##
def charEncode(chars: str, char: str, k: int) -> tuple:
chars = set('abcdefghijklmnopqrstuvwxyzABCDRFGHIJKLMNOPQRSTUVWXYZ0123456789') # 不用url编码字符集
puncs = set('/.?,_=') # 编码放行标点字符
#return (char, k+1) if char in chars.union(puncs) else (f"%{hex(ord(char))[2:].upper()}", k+1)
return (char, k+1) if char in chars | puncs else (f"%{hex(ord(char))[2:].upper()}", k+1) # set对象拼接,可用set.union()方法,也可以用 | 连接运算符
def urlEncode(url: str) -> str:
urlList = [f"{url.split(':')[0]}:"] # 截取网络协议标识字符串
k = len(urlList[0]) # 检索下标初值
n = len(url) # 获取url长度
while k < n:
char, k = charEncode(url, url[k], k)
urlList += [char]
return ''.join(urlList)
if __name__ == '__main__':
strDecode = urlDecode(url)
reEncode = urlEncode(strDecode)
print(f"\n编码Url:\n{url}\n\n解码后;\n{strDecode}\n\n重新编码:\n{reEncode}\n\n原始编码 = 重新编码:{url == reEncode}\n")
代码运行效果截屏图片
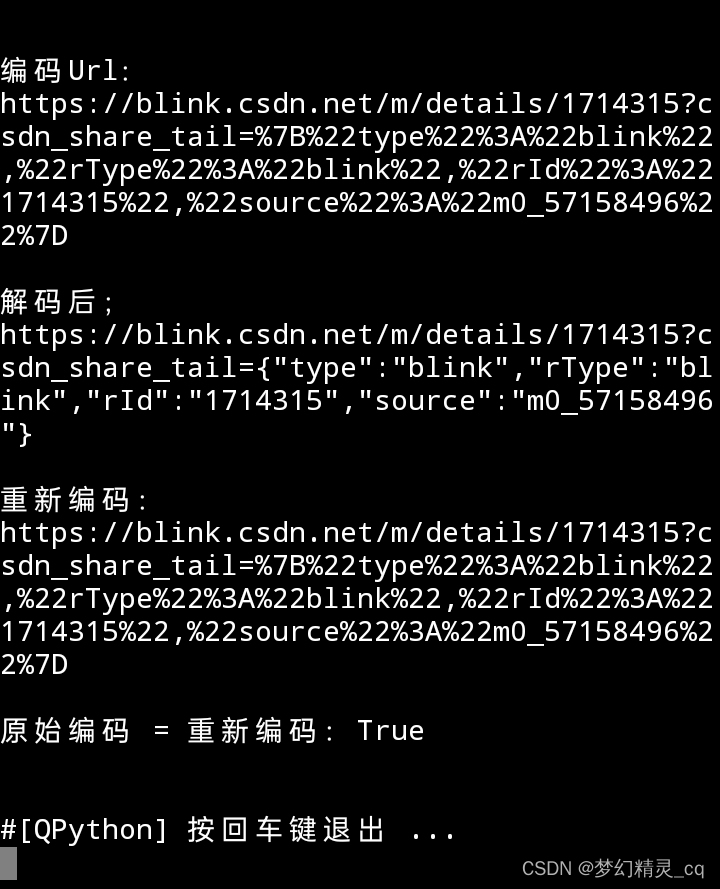
经与原始编码url比对验证,编码函数重新编码的url与其完全一致。代码修正成功!
5.2 代码解析
正在编辑中……
6、完整源码(Python)
(源码较长,点此跳过源码)
#!/sur/bin/nve python
# coding: utf-8
asciis = [chr(i) for i in range(32, 127)]
print(f"\n33个控制字符不可见,可打印的ASCII字符集:\n\n共计{len(asciis)}个(含空格)\n{', '.join(asciis)}\n")
url = "https://blink.csdn.net/m/details/1714315?csdn_share_tail=%7B%22type%22%3A%22blink%22,%22rType%22%3A%22blink%22,%22rId%22%3A%221714315%22,%22source%22%3A%22m0_57158496%22%7D"
## 解码 ##
def charDecode(chars: str, char: str, k: int) -> tuple:
return (chr(int(chars[k+1:k+3],16)), k+3) if char == '%' else (char, k+1)
def urlDecode(url: str) -> str:
urlList = []; k = 0; n = len(url)
while k < n:
char, k = charDecode(url, url[k], k)
urlList += [char]
return ''.join(urlList)
## 编码 ##
def charEncode(chars: str, char: str, k: int) -> tuple:
chars = set('abcdefghijklmnopqrstuvwxyzABCDRFGHIJKLMNOPQRSTUVWXYZ0123456789') # 不用url编码字符集
puncs = set('/.?,_=') # 编码放行标点字符
#return (char, k+1) if char in chars.union(puncs) else (f"%{hex(ord(char))[2:].upper()}", k+1)
return (char, k+1) if char in chars | puncs else (f"%{hex(ord(char))[2:].upper()}", k+1) # set对象拼接,可用set.union()方法,也可以用 | 连接运算符
def urlEncode(url: str) -> str:
urlList = [f"{url.split(':')[0]}:"] # 截取网络协议标识字符串
k = len(urlList[0]) # 检索下标初值
n = len(url) # 获取url长度
while k < n:
char, k = charEncode(url, url[k], k)
urlList += [char]
return ''.join(urlList)
if __name__ == '__main__':
strDecode = urlDecode(url)
reEncode = urlEncode(strDecode)
print(f"\n编码Url:\n{url}\n\n解码后;\n{strDecode}\n\n重新编码:\n{reEncode}\n\n原始编码 = 重新编码:{url == reEncode}\n")
上一篇: Python 中的“点阵字体”(“点阵字体”是个啥?,在python中怎么使?在现在全面高清的$5G$时代,它还有用“武”之地)
下一篇:
我的HOT博:
本次共计收集 311 篇博文笔记信息,总阅读量43.82w。数据于2024年03月22日 00:50:22完成采集,用时6分2.71秒。阅读量不小于6.00k的有 7 7 7篇。
001
标题:让QQ群昵称色变的神奇代码
(浏览阅读 5.9w )
地址:https://blog.csdn.net/m0_57158496/article/details/122566500
点赞:25 收藏:86 评论:17
摘要:让QQ昵称色变的神奇代码。
首发:2022-01-18 19:15:08
最后编辑:2022-01-20 07:56:47002
标题:Python列表(list)反序(降序)的7种实现方式
(浏览阅读 1.1w )
地址:https://blog.csdn.net/m0_57158496/article/details/128271700
点赞:8 收藏:35 评论:8
摘要:Python列表(list)反序(降序)的实现方式:原址反序,list.reverse()、list.sort();遍历,全数组遍历、1/2数组遍历;新生成列表,resersed()、sorted()、负步长切片[::-1]。
首发:2022-12-11 23:54:15
最后编辑:2023-03-20 18:13:55003
标题:pandas 数据类型之 DataFrame
(浏览阅读 9.7k )
地址:https://blog.csdn.net/m0_57158496/article/details/124525814
点赞:7 收藏:36
摘要:pandas 数据类型之 DataFrame_panda dataframe。
首发:2022-05-01 13:20:17
最后编辑:2022-05-08 08:46:13004
标题:个人信息提取(字符串)
(浏览阅读 8.2k )
地址:https://blog.csdn.net/m0_57158496/article/details/124244618
点赞:2 收藏:15
摘要:个人信息提取(字符串)_个人信息提取python。
首发:2022-04-18 11:07:12
最后编辑:2022-04-20 13:17:54005
标题:Python字符串居中显示
(浏览阅读 7.6k )
地址:https://blog.csdn.net/m0_57158496/article/details/122163023
评论:1006
标题:罗马数字转换器|罗马数字生成器
(浏览阅读 7.5k )
地址:https://blog.csdn.net/m0_57158496/article/details/122592047
摘要:罗马数字转换器|生成器。
首发:2022-01-19 23:26:42
最后编辑:2022-01-21 18:37:46007
标题:回车符、换行符和回车换行符
(浏览阅读 6.0k )
地址:https://blog.csdn.net/m0_57158496/article/details/123109488
点赞:2 收藏:3
摘要:回车符、换行符和回车换行符_命令行回车符。
首发:2022-02-24 13:10:02
最后编辑:2022-02-25 20:07:40
截屏图片

(此文涉及ChatPT,曾被csdn多次下架,前几日又因新发笔记被误杀而落马。躺“未过审”还不如回收站,回收站还不如永久不见。😪值此年底清扫,果断移除。留此截图,以识“曾经”。2023-12-31)

精品文章:
- 好文力荐:齐伟书稿 《python 完全自学教程》 Free连载(已完稿并集结成书,还有PDF版本百度网盘永久分享,点击跳转免费🆓下载。)
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
◆ Python 入门指南【Python 3.6.3】
好文力荐:
- 全栈领域优质创作者——[寒佬](还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是编程学习的两大利器。
- 【8大编程语言的适用领域】先别着急选语言学编程,先看它们能干嘛
- 靠谱程序员的好习惯
- 大佬帅地的优质好文“函数功能、结束条件、函数等价式”三大要素让您认清递归
CSDN实用技巧博文: