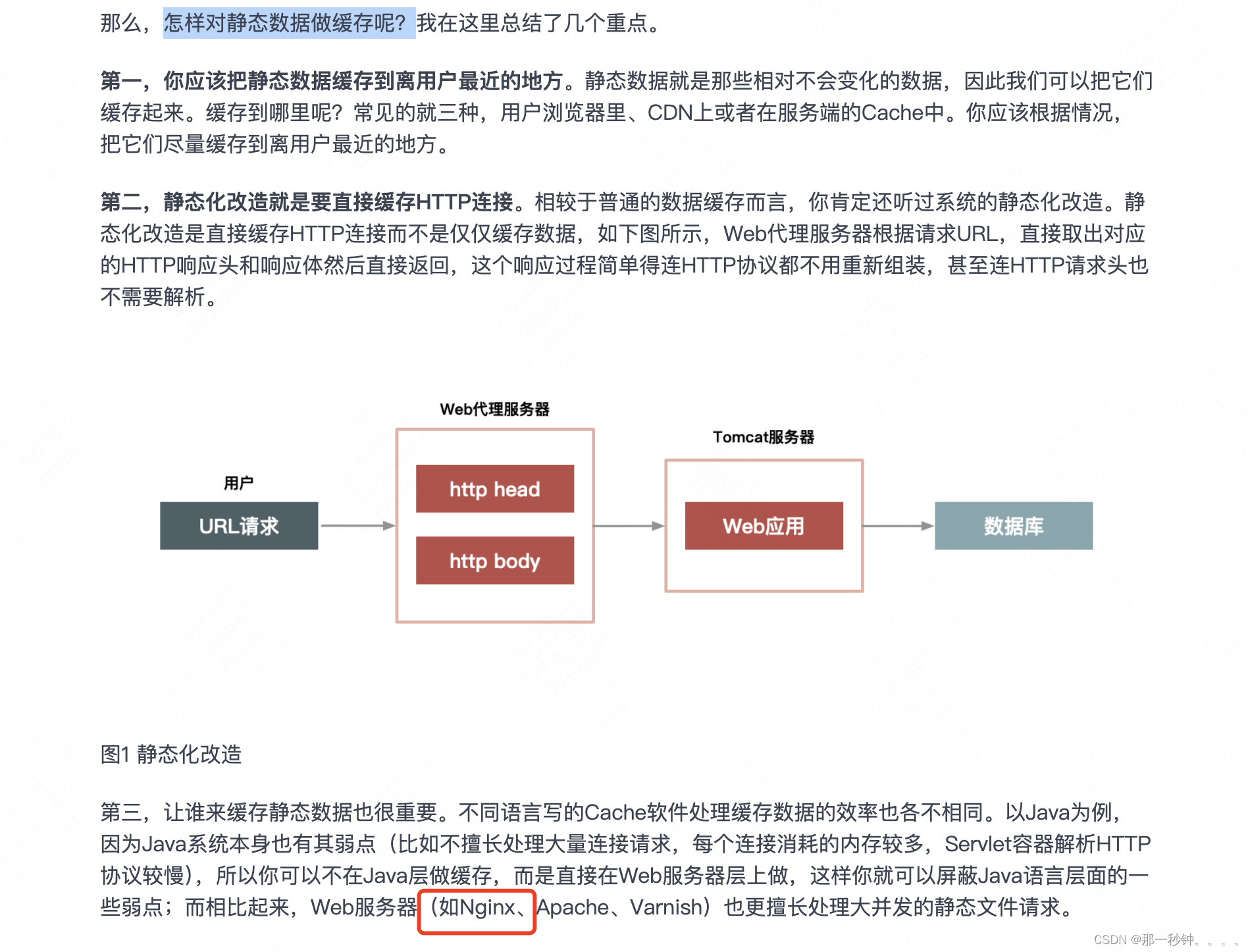
1. 简述Hive的开窗函数有哪些 ?
Hive的开窗函数(Window Functions)是一种特殊的函数,它在某种程度上类似于聚合函数,但是它们为每一行返回一个值,而不是将多行合并为一个单一的聚合输出。开窗函数在处理数据时能够提供更加丰富的数据分析能力。以下是Hive中一些常见的开窗函数:
ROW_NUMBER():
- 为结果集中的每一行分配一个唯一的序号,序号是连续的,从1开始。
RANK():
- 为结果集中的每一行分配一个排名,如果有相同的值,它们会获得相同的排名,并且排名会跳过后续的数字。
DENSE_RANK():
- 与RANK()类似,但是DENSE_RANK()不会跳过排名数字,即使有并列排名,后续的排名仍然是连续的。
LEAD():
- 返回结果集中当前行之后一行的值。可以指定一个offset来获取更远的行。
LAG():
- 返回结果集中当前行之前一行的值。可以指定一个offset来获取更远的行。
FIRST_VALUE():
- 返回窗口内指定列的第一个值。
LAST_VALUE():
- 返回窗口内指定列的最后一个值。
NTILE():
- 将结果集分为指定数量的桶,返回当前行所属桶的编号。
NTH_VALUE():
- 返回在窗口内指定行号的值。
开窗函数通常与OVER()子句一起使用,OVER()子句定义了窗口函数操作的窗口范围。窗口可以是:
- 从当前行开始到结果集的末尾。
- 从当前行开始到某个特定的行。
- 基于某个排序的行的范围。
以下是一个开窗函数使用的例子:
SELECT
column1,
column2,
ROW_NUMBER() OVER (ORDER BY column1) AS row_num
FROM
table_name;
在这个例子中,ROW_NUMBER()开窗函数为table_name表中的每一行按column1排序后分配一个唯一的序号。
开窗函数在进行复杂数据分析时非常有用,比如在处理时间序列数据、排名、层次结构数据等方面。它们提供了一种强大的工具,可以在不改变原始数据集的情况下,为每一行数据提供上下文信息。
2. 简述Hive存储数据吗 ?
是的,Hive 设计用于存储和处理大规模数据集。作为 Hadoop 生态系统的一部分,Hive 主要负责数据的存储、查询和管理。以下是 Hive 存储数据的一些关键点:
数据存储位置:
- Hive 表中的数据通常存储在 Hadoop 分布式文件系统(HDFS)上,这是 Hadoop 的默认文件系统。
数据模型:
- Hive 使用表格模型,其中数据以行和列的形式组织。
数据类型:
- Hive 支持多种数据类型,包括数值型、字符串型、二进制型以及复杂的数据类型如数组、映射和结构。
分区:
- Hive 支持表的分区,这意味着数据可以根据某些列(通常是时间戳或地区代码)被分割成不同的分区。
桶(Bucketing):
- 除了分区,Hive 还支持桶的概念,它允许数据在物理上进一步细分,以优化查询性能。
存储格式:
- Hive 支持多种存储格式,包括文本文件、SequenceFile、ORC(Optimized Row Columnar)、Parquet 和 Avro 等。
数据导入:
- 数据可以通过多种方式导入到 Hive 表中,包括使用
LOAD DATA、INSERT INTO语句,或者通过 Hive 的数据导入工具。
- 数据可以通过多种方式导入到 Hive 表中,包括使用
数据导出:
- Hive 支持将数据导出到 HDFS、其他 Hive 表或外部系统。
数据压缩:
- Hive 支持数据压缩,可以减少存储空间的使用并提高 I/O 性能。
数据版本控制:
- 通过 ACID(原子性、一致性、隔离性、持久性)特性,Hive 支持事务和数据版本控制。
数据安全:
- Hive 提供了数据安全机制,如授权和加密,以保护存储的数据。
元数据管理:
- Hive 使用自己的元数据存储(Metastore),它是一个关系数据库,用于存储有关 Hive 表的元数据信息。
Hive 的设计目标是提供一个可扩展、高效和灵活的数据存储和查询解决方案,适用于大规模数据集的处理和分析。通过 Hive,用户可以执行复杂的数据分析任务,而无需编写复杂的 MapReduce 程序。
3. 简述row_number,rank,dense_rank的区别 ?
ROW_NUMBER()、RANK()和DENSE_RANK()都是开窗函数,用于在有序的数据集上为每一行分配一个序号或排名。它们的主要区别在于如何处理具有相同值的行:
ROW_NUMBER():
ROW_NUMBER()为每一行分配一个唯一的序号,序号从1开始连续递增,即使有相同的值也不会跳过数字。- 它不考虑行之间的值是否相同,每行都会得到一个唯一的连续编号。
RANK():
RANK()为每一行分配一个排名,如果有两行具有相同的值,它们会获得相同的排名,并且后续的排名会跳过。- 例如,如果第一和第二行并列第一(即RANK为1),则下一行的排名会直接是3(而不是2)。
DENSE_RANK():
DENSE_RANK()同样为每一行分配一个排名,但是与RANK()不同,它不会在排名中跳过数字。- 如果有并列排名,后续的排名仍然是连续的。例如,如果第一和第二行并列第一(即DENSE_RANK为1),则下一行的排名会是2。
示例说明:
假设有一个按工资降序排列的员工表:
| 员工ID | 工资 |
|---|---|
| A | 5000 |
| B | 5000 |
| C | 4000 |
| D | 3000 |
| E | 3000 |
应用不同的开窗函数:
使用
ROW_NUMBER():- 序号:1, 2, 3, 4, 5
使用
RANK():- 排名:1, 1, 3, 4, 4
使用
DENSE_RANK():- 排名:1, 1, 2, 3, 3
总结来说,ROW_NUMBER()用于分配连续的序号,不考虑值的相同性;RANK()和DENSE_RANK()用于分配排名,考虑值的相同性,但RANK()会在排名中跳过数字,而DENSE_RANK()则保持排名数字的连续性。
4. 简述Hive count(distinct)有几个reduce,海量数据会有什么问题 ?
在 Hive 中,COUNT(DISTINCT column) 用于计算某一列中不同值的数量。这个操作涉及到两个主要的 MapReduce 阶段:
Map 阶段:
- 在 Map 阶段,每个 Mapper 会处理输入数据的一部分,并为
COUNT(DISTINCT)操作收集不同的值。
- 在 Map 阶段,每个 Mapper 会处理输入数据的一部分,并为
Reduce 阶段:
- 在 Reduce 阶段,所有 Mapper 的输出会被发送到 Reducer。Reducer 负责合并来自不同 Mapper 的结果,并计算最终的不同值数量。
Reducer 的数量:
COUNT(DISTINCT column)操作通常只需要一个 Reducer,因为它的目的是计算全局的不同值数量。然而,实际的 Reducer 数量可能受到多个因素的影响,包括:mapreduce.job.reduces配置参数:这个参数可以显式设置 Reducer 的数量。- 数据倾斜:如果数据分布不均匀,可能会导致某些 Reducer 处理的数据量远大于其他 Reducer。
海量数据的问题:
在处理海量数据时,使用 COUNT(DISTINCT column) 可能会遇到以下问题:
性能问题:
- 如果数据量非常大,
COUNT(DISTINCT)操作可能会非常慢,因为它需要在所有数据中进行去重。
- 如果数据量非常大,
资源消耗:
- 大量的数据处理可能会导致内存和 CPU 使用率飙升,从而影响集群的性能。
数据倾斜:
- 如果某些值非常普遍,可能会导致某些 Reducer 处理的数据远多于其他 Reducer,造成数据倾斜。
网络传输瓶颈:
- 在 Shuffle 阶段,大量的中间数据需要在网络中传输,可能会成为性能瓶颈。
内存溢出:
- Reducer 可能会因为处理的数据量过大而导致内存溢出。
磁盘 I/O:
- Reducer 写入和读取中间数据到磁盘可能会引起 I/O 瓶颈。
优化策略:
为了优化 COUNT(DISTINCT column) 操作,可以考虑以下策略:
- 增加 Reducer 数量:通过调整
mapreduce.job.reduces参数增加 Reducer 数量,可以分散负载。 - 使用近似算法:对于不需要精确结果的场景,可以使用近似算法如 HyperLogLog 来估算不同值的数量。
- 采样:在执行全局去重前,先对数据进行采样,以估计不同值的数量。
- 索引:为列创建索引,加快查找速度。
- 物化视图:如果查询是常见的,可以考虑使用物化视图来存储预先计算的结果。
- 分区和分桶:使用分区和分桶来减少需要处理的数据量。
通过这些优化措施,可以提高 COUNT(DISTINCT column) 操作的性能,并减少在处理海量数据时可能遇到的问题。
5. 简述一条HQL从代码到执行的过程 ?
一条HiveQL(Hive Query Language)从编写到执行的过程涉及多个步骤,这些步骤大致如下:
编写HQL:
- 用户使用HiveQL编写查询,HiveQL是一种类似于SQL的语言,用于对存储在Hadoop上的大数据进行查询和分析。
提交HQL:
- 用户通过Hive CLI(命令行界面)、Hive Web界面、编程接口(如JDBC或ODBC)或其他集成开发环境(IDE)提交HQL查询。
解析:
- Hive对提交的HQL进行解析,将其转换成抽象语法树(AST),这一步主要进行语法检查。
语义分析:
- 语义分析器检查AST的正确性,包括验证表和列的存在性、权限检查等。
逻辑计划生成:
- 经过语义分析后,Hive将AST转换成逻辑执行计划,这是一个高层次的查询表示,包含了操作的逻辑顺序。
逻辑计划优化:
- 逻辑计划通过一系列优化规则进行优化,以减少资源消耗和提高查询效率。
物理计划生成:
- 优化后的逻辑计划被转换成物理执行计划,这一步涉及到将逻辑操作转换为可以由Hadoop执行的具体操作。
编译成MapReduce作业:
- 物理计划通常被编译成MapReduce作业或其他执行引擎(如Tez、Spark)的作业。
提交作业到YARN:
- 编译后的作业被提交到YARN(Yet Another Resource Negotiator),YARN负责资源管理和作业调度。
执行MapReduce作业:
- MapReduce作业在Hadoop集群上执行,包括Map任务的并行处理和Reduce任务的汇总。
结果处理:
- 作业执行完成后,结果被处理并返回给用户。
作业监控:
- 用户可以通过Hive Web界面或其他监控工具来监控作业的执行状态和进度。
结果返回:
- 查询结果最终返回给用户,用户可以在提交查询的界面上查看结果。
整个过程是Hive将高级的、类似SQL的查询语言转换成可以在Hadoop集群上分布式执行的作业。随着Hive的发展,除了MapReduce,还支持其他执行引擎如Tez和Spark,这些引擎提供了更高效的数据处理能力。此外,Hive还提供了一些高级特性,如向量化查询、LLAP(Live Long and Process)等,进一步提高查询性能。
6. 简述前后函数 lag(expr,n,defval)、lead(expr,n,defval) ?
LAG 和 LEAD 函数是 Hive 中用于访问窗口函数中前一行或后一行数据的函数。这些函数通常用于分析类型操作,允许你访问一组相关行中相对于当前行的其他行的数据。
LAG函数:
LAG(expr, n, defval) 函数用于访问当前行的前 n 行的数据。如果 n 是 1,它将访问当前行的前一行。如果当前行是第一行或之前的行没有足够的行,则返回默认值 defval。
- 参数:
expr:要访问的表达式或列。n:从当前行向上数的行数。defval:如果没有足够的行,则返回的默认值。
LEAD函数:
LEAD(expr, n, defval) 函数用于访问当前行的后 n 行的数据。如果 n 是 1,它将访问当前行的后一行。如果当前行是最后一行或之后没有足够的行,则返回默认值 defval。
- 参数:
expr:要访问的表达式或列。n:从当前行向下数的行数。defval:如果没有足够的行,则返回的默认值。
示例:
假设有一个名为 sales 的表,包含以下列:date, product, amount。你可以使用 LAG 和 LEAD 函数来比较相邻日期的销售情况:
SELECT
date,
product,
amount,
LAG(amount, 1, 0) OVER (PARTITION BY product ORDER BY date) AS prev_amount,
LEAD(amount, 1, 0) OVER (PARTITION BY product ORDER BY date) AS next_amount
FROM
sales;
在这个查询中:
LAG(amount, 1, 0)返回每个产品的前一天的销售量,如果没有前一天的销售数据,则返回 0。LEAD(amount, 1, 0)返回每个产品的后一天的销售量,如果没有后一天的销售数据,则返回 0。
这些函数非常有用,因为它们允许你在不进行复杂的自连接或子查询的情况下,轻松地访问和比较行之间的数据。
7. 简述头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr) ?
FIRST_VALUE 和 LAST_VALUE 是Hive中的开窗函数,它们用于在查询结果集中对每一行返回特定列的第一个或最后一个值。这些函数通常与 OVER() 子句结合使用,以定义函数操作的窗口范围。
FIRST_VALUE(expr)
FIRST_VALUE 函数返回指定列在每个窗口内的第一个值。窗口可以基于某个排序顺序或分区来定义。
使用示例:
SELECT
column1,
column2,
FIRST_VALUE(column2) OVER (PARTITION BY column1 ORDER BY column3) AS first_value_of_column2
FROM
table_name;
在这个例子中,FIRST_VALUE 函数将为 column1 相同的每一组返回 column2 的第一个值。结果集按 column1 分区,并按 column3 排序。
LAST_VALUE(expr)
LAST_VALUE 函数返回指定列在每个窗口内的最后一个值。与 FIRST_VALUE 类似,窗口也可以基于排序顺序或分区来定义。
使用示例:
SELECT
column1,
column2,
LAST_VALUE(column2) OVER (PARTITION BY column1 ORDER BY column3) AS last_value_of_column2
FROM
table_name;
在这个例子中,LAST_VALUE 函数将为 column1 相同的每一组返回 column2 的最后一个值。
特点:
FIRST_VALUE和LAST_VALUE函数可以用于时间序列分析、趋势分析等场景,允许用户查看数据集中的起始和结束值。- 这些函数返回的值依赖于
OVER()子句定义的窗口。如果不指定排序列,则结果可能不符合预期。 - 这些函数对于处理有序数据集非常有用,例如,获取某个时间段内的第一个和最后一个数据点。
注意:
- 使用这些函数时,需要确保
OVER()子句正确定义了窗口的排序和分区,以便函数能够正确地识别每个窗口的范围。 FIRST_VALUE和LAST_VALUE是Hive 0.14及以上版本支持的函数。在旧版本中可能不可用或具有不同的行为。






























![【已解决】FileNotFoundError: [Errno 3] No such file or directory: ‘xxx‘](https://img-blog.csdnimg.cn/direct/54dbfb4788b847e282fbdbe2a8715db7.png)