缓存更新策略
再解决redis三大问题时(缓存穿透,缓存雪崩,缓存击穿),我们先来了解其他几个问题.
问题一: 采用何种策略更新?
- 低一致需求: 基于redis的内存淘汰机制
- 高一致需求: 手动进行缓存的更新,并以超时剔除作为兜底方案
问题二 : 那我们到底是删除缓存还是更新对应的缓存?
1. 删除缓存还是更新缓存
- 更新缓存 : 每次更新数据库都更新缓存,无效写操作较多(不推荐)
- 弊端: 每次操作数据库都对缓存进行更新操作, 万一是一个写多读少的场景,更新的缓存没有意义
- 删除缓存: 更新数据库时,让缓存失效,查询时再更新缓存(推荐)
- 这样可以避免更新缓存的弊端
问题三:先操作数据库还是缓存?
2. 先删缓存还是操作数据库
- 先删缓存再删数据库
场景分析:
假设这时有两个线程,第一个线程需要将一个字段值改为20,原有的值为10,删除缓存,然后准备去更新数据库,而在这中间过程中,第二个线程来了,查询缓存没有命中,去查询数据库将数据缓存到了redis当中,而此时第一个线程才把数据库更新完.此时造成了数据库与缓存中的数据不一致.且此事件发生的概率并不低.更新数据库的操作会比较慢,查询缓存一下子就完成了,之后查询数据库数据再进行缓存.

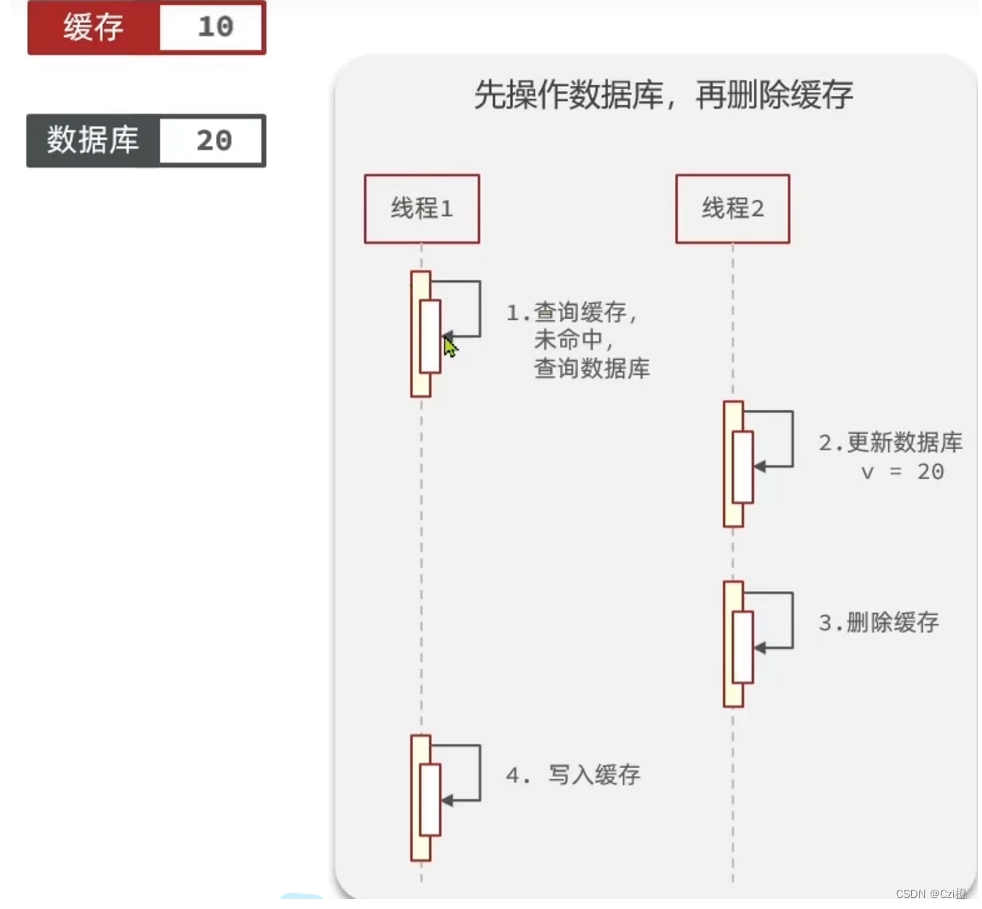
- 先操作数据库再删缓存
场景分析:
同样假设两个线程,第一个线程查询缓存未命中,所以去查询数据库,准备将数据缓存到redis,而突然在这个过程中,第二个线程更新数据库表字段信息,从10置为20,再删除缓存.而此时第一个线程才把数据库的进行缓存.此时导致缓存的是老数据,出现了缓存和数据库数据不一致的现象.但此事件发生的概率低,因为写入缓存的速度比较快,而更新数据库的操作比较慢,所以基本概率会很小,而我们也可做一个兜底方案,给缓存数据设置超时时间,也就仅仅在短时间内会出现数据不一致现象
一.缓存穿透
概念: 当用户查询一条缓存和数据库都不存在的数据时发生的现象. 此时存在一定的安全隐患, 恶意的人员如果开启多个线程访问一条数据库和缓存都不存在的数据,将会对数据库造成极大的压力,导致服务器卡死的重大问题.
解决方案:
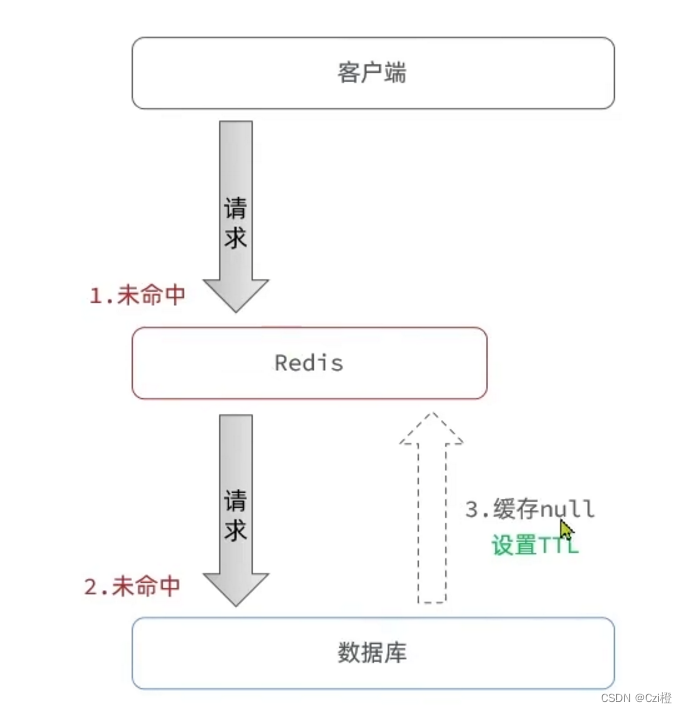
- 缓存空对象
概念: 将访问这条数据库和缓存的数据缓存起来,当下次访问的时候,将会在redis当中命中.以此来缓解数据库的压力,避免缓存穿透的现象的产生.
缺点:
- 造成内存的浪费,因为缓存了大量的空对象,与实际业务无关的数据
- 造成数据的短期的不一致.当用户查询一条数据不存在时,此时将此空id缓存到redis,而此时又插入了一条这样的数据,用户查询这条数据的时候返回的却是redis里面缓存的空对象,造成了数据的不一致
解决方案:
- 设置过期时间,大概不超过5分钟,通常为几十秒左右的时间.这样在这期间对数据库的压力减小,并且可以避免大量的内存浪费
- 在数据插入的时候,也将这条数据缓存到redis当中,也就是覆盖原来缓存的空对象,这样就能保证数据的一致性.
- 布隆过滤器
概念: 在用户访问redis时,中间加一层布隆过滤器,以来提前判断数据是否存在.
何为布隆过滤器呢?
布隆过滤器是一种数据结构,比较巧妙的概率型的数据结构,特点是高效地插入和查询,可以用来告诉你"某样东西一定不存在或者可能存在"
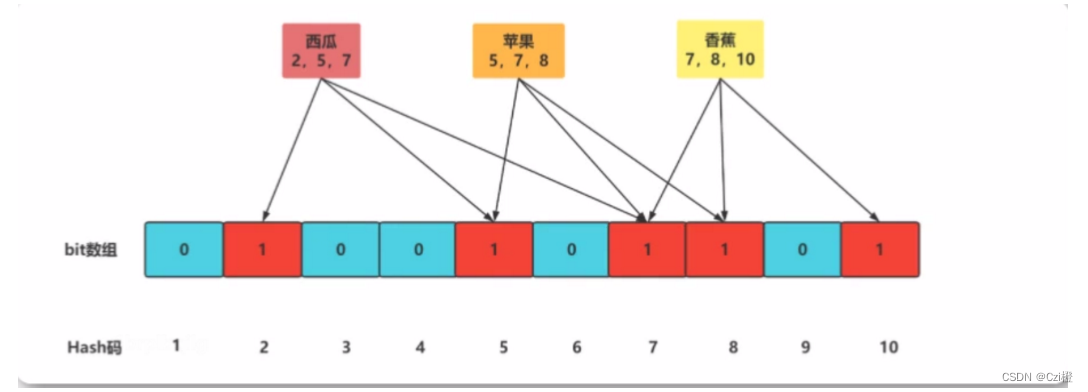
原理: 首先将所有的数据,通过不同的哈希函数,对字段数据进行哈希运算, 然后在一个Bit数组当中所属位置置为1.通常这个bit数组会很长.以来降低误判的可能性.而对于内存的消耗也比较小,假设有1000万个数据,3个哈希函数,那么对应3000万个bit位,我们假设每一个都不重复,那么消耗的内存为 30000000/8(字节)/1024(kb)/1024(mb) = 3.58(mb).所以对内存的消耗较小,且效率高.
那为什么会误判呢?
由于进行的哈希运算,有可能计算的一个字段数据恰好分散的命中到bit数组为1的位置上,布隆过滤器误以为这条数据存在,就产生了误判.
布隆过滤器存在误判现象,所以当布隆过滤器说不存在时,一定不存在.而当存在时,不一定存在.由于概率比较低,能够访问到数据库的量比较少,是可以接受的情况,所以并没有大碍.
显而易见,布隆过滤器的缺点为
- 存在误判现象
- 实现复杂
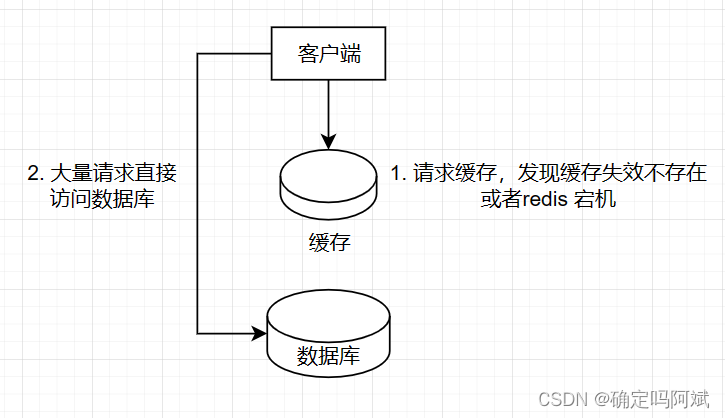
二 . 缓存雪崩
问题产生原因: 大量的key同时失效或者redis服务器宕机,大量的请求打到数据库造成数据库压力过大.
解决方案
1. 给key设置随机的ttl(针对大量key失效)
- 出现大量的key同时失效,基本是在做缓存预热时,设置了同样的过期时间,造成了雪崩场景的出现.基于这种原因,我们可以设置随机的ttl这样就可以一定程度避免雪崩现象的产生
2. 部署redis集群(针对服务器宕机)
- 当服务器宕机时,此时所有的key全部失效,且大量的请求打到数据库,压力急剧上升.我们可以部署多台redis服务器,利用主从复制和哨兵机制,当一个服务器出现宕机时,利用哨兵机制检测异常服务器,可以立马进行主从的切换,来保证整个服务的可用性.
3. 多级缓存
- 我们可以不仅仅在redis设置缓存,jvm也可以设置缓存,同样数据库也能进行缓存,进行这种多种缓存,哪怕redis挂了也能基于这些多级缓存来应对
4. 降级保护
- 当redis服务器发生异常,将访问的服务器请求熔断,拒绝所有的请求,以来保护服务器.
三缓存击穿
问题产生的原因: 热点key突然失效,大量的请求打到数据库,造成数据库压力过大
解决方案
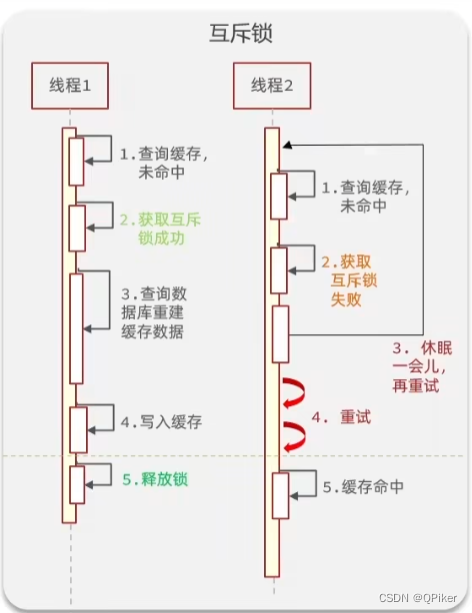
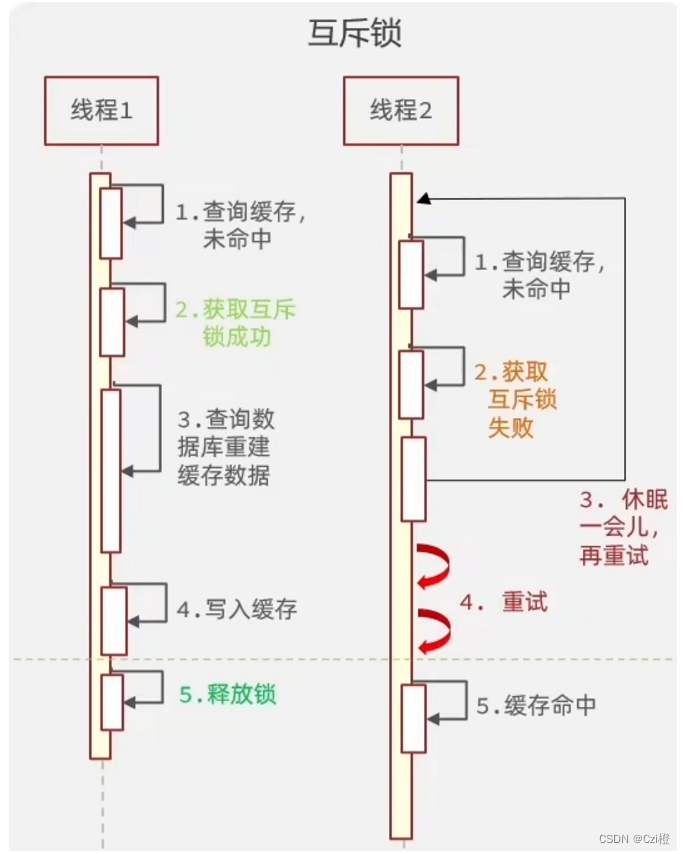
1. 互斥锁
- 查询缓存未命中时,在去查数据库更新缓存时,在这个操作上上锁
- 这样多个请求当中只有一个线程再去进行缓存重建.数据性一致强
- 实现简单
缺点:
- 性能受到影响,在重建缓存的过程种多个线程处于等待状态
- 有死锁的风险
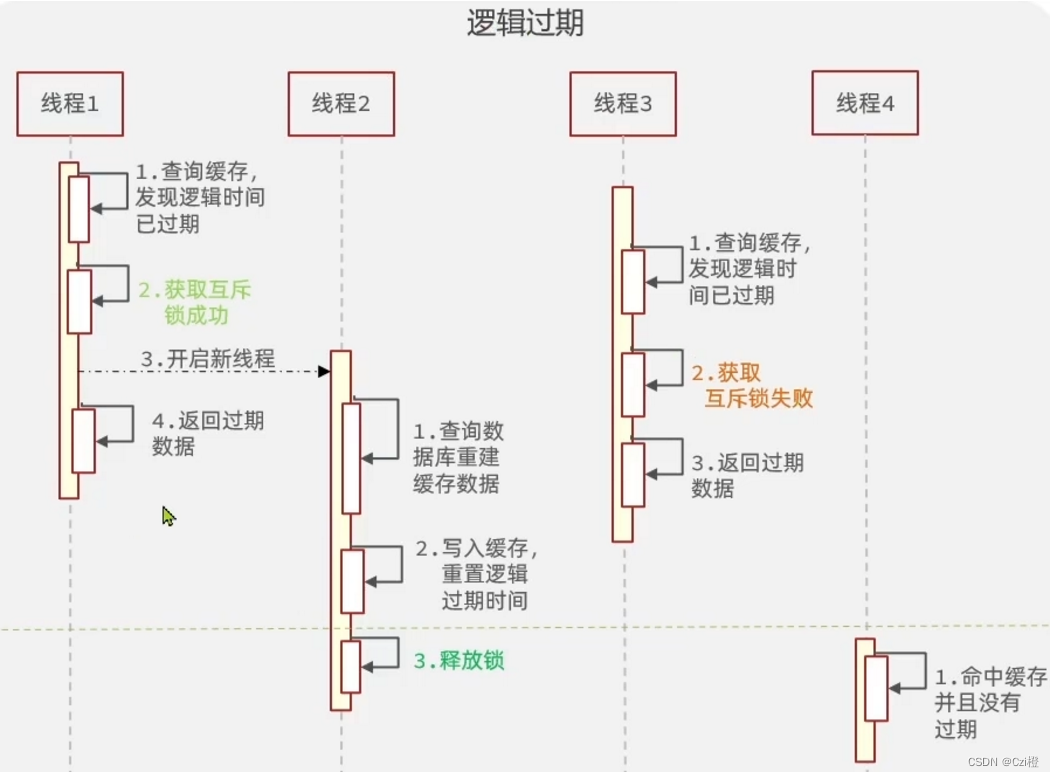
2. 逻辑过期
- 将过期时间存进redis需要存储的数据里面当中,查询缓存时,获取到这个ttl与当前的时间做对比,如果在当前时间之后,说明已经过期,我们需要重新构建缓存
- 重构过程我们开启一个线程去完成这件事.首先获取互斥锁,获取到的线程去完成这件事.其余的请求返回旧数据.
那么缺点同样也暴露出来了
- 会损失一定的数据一致性,因为在缓存重构未完成之前,都是将旧的数据返回
- 实现起来比较复杂
优点当然就是性能上的优化啦,其余的请求也能快速的得到响应不过只是旧的数据,也就是保证可用性牺牲一定的数据一致性.
注意: 无论是互斥锁解决方案还是逻辑过期解决方案.在获取锁之后都需要进行Double check.即还需要去查询缓存.
原因: 在查询热点缓存过期或者不存在后,而在获取锁之前这一过程,万一有一个线程已经完成了缓存的更新,此时如果再去重构缓存,是重复构建的,是多余的.所以避免这个事件的发生我们需要进Double check,即再查一次