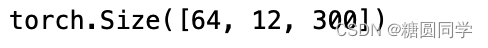TR1
一、文本输入处理
1. 词向量
和常见的NLP 任务一样,首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。
如下图所示,假设我们的输入文本是序列包含了3个词,那么每个词可以通过词嵌入算法得到一个4维向量,于是整个输入被转化成为一个向量序列。在实际应用中,我们通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:如果一个句子达不到这个长度,那么就进行0填充;如果句子超出这个长度,则做截断。最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况进行决定。

2. 位置向量
输入序列每个单词被转换成词向量,还将加上位置向量来得到该词的最终向量表示,如下图所示。Transformer模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征、句子中不同单词之间的距离特征。

依旧假设词向量和位置向量的维度是4,我们在下图中展示一种可能的位置向量+词向量:

二、编码器Encoder
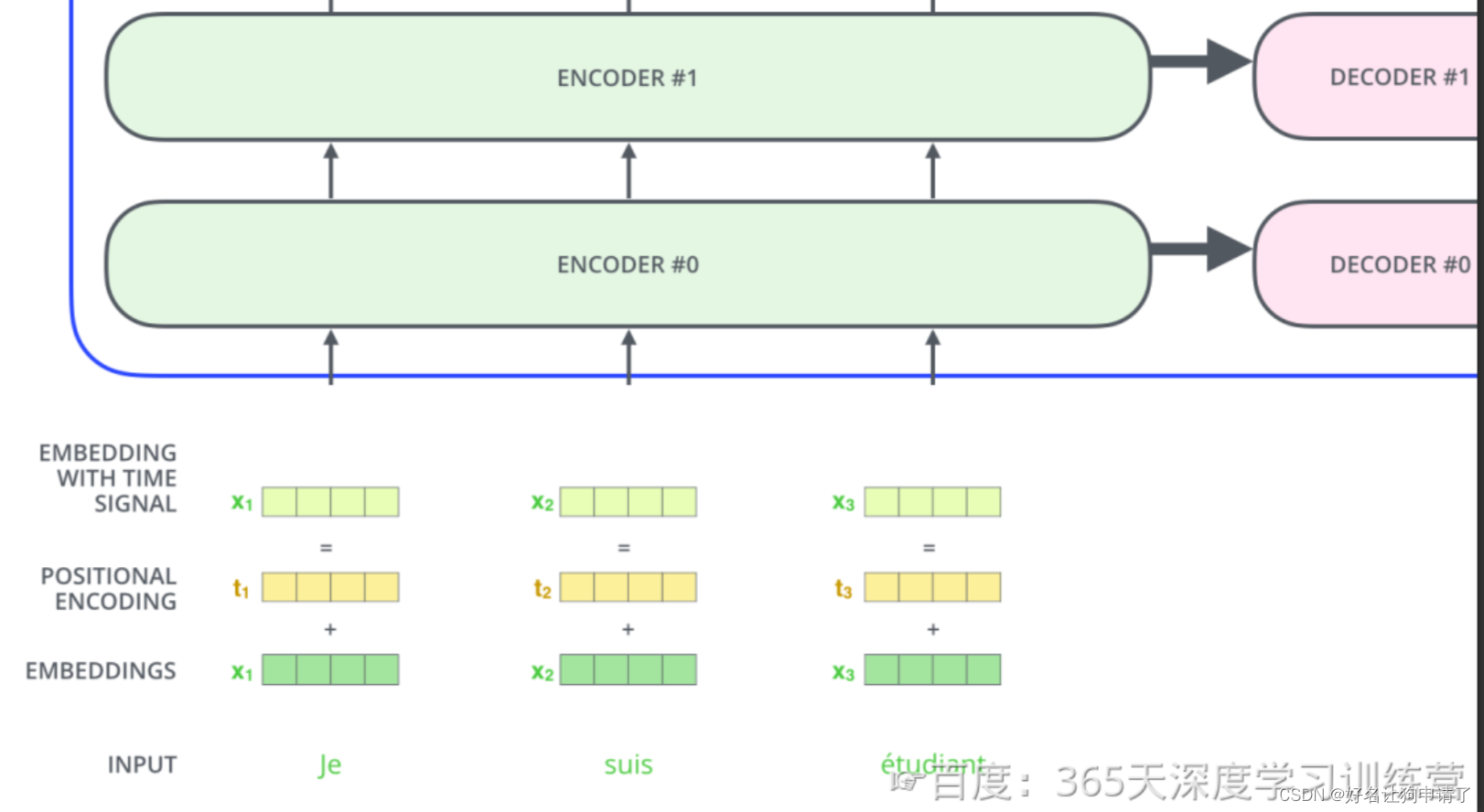
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器。下图展示了向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFN神经网络得到每个位置的新向量。

1. Self-Attention层
假设我们想要翻译的句子是:The animal didn't cross the street because it was too tired.
这个句子中的 it 是一个指代词,那么 it 指的是什么呢?它是指 animal 还是street?这个对模型来说并不是那么容易。但是,如果模型引入了Self---Attention机制之后,便能够让模型把 it 和 animal 关联起来了。同样的,当模型处理句子中其他词时,Self--- Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
2.多头注意力机制
它扩展了模型关注不同位置的能力。例如在上面的例子中,我们翻译句子:The animal didn’t cross the street because it was too tired时,我们不仅希望模型关注到"it"本身,还希望模型关注到"The"和“animal”,甚至关注到"tired"。
多头注意力机制赋予Attention层多个“子表示空间”。
3. 残差连接
模型计算得到了self-attention的输出向量后。而单层encoder里后续还有两个重要的操作:残差链接、标准化。编码器的每个子层(Self-Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization),如下图所示。

编码器和和解码器的子层里面都有层标准化(layer-normalization)。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,将全部内部细节展示起来如下图所示。

三、解码器Decoder
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,如下图所示。

四、线性层和softmax层
解码器最终的输出是一个向量,其中每个元素是浮点数。通过线性层和 softmax层这个向量转换为单词对应概率。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量:假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
五、损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。这里,以把“merci”翻译为“thanks”为例说明loss的计算。
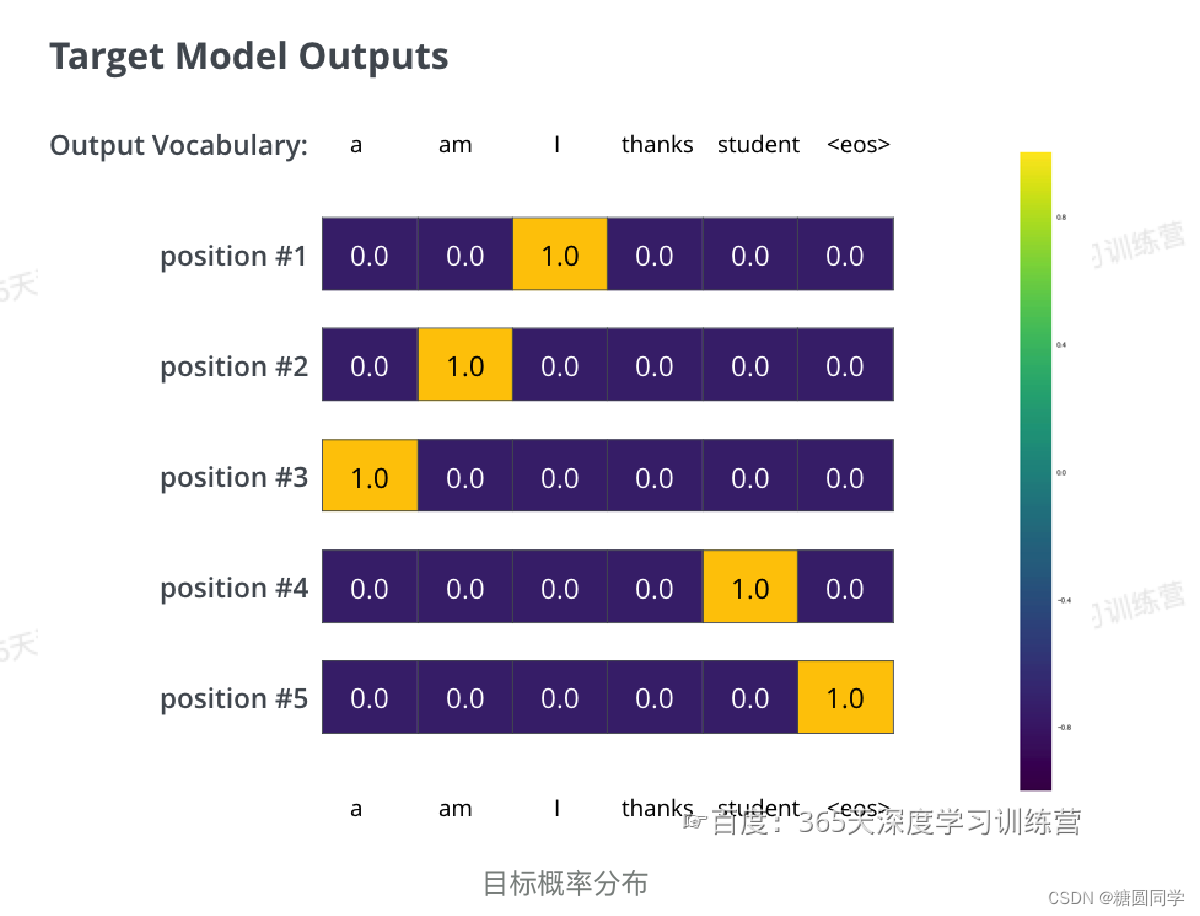
我们希望模型解码器最终输出的概率分布,会指向单词 “thanks”(在“thanks”这个词的概率最高)。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远,如下图所示。正确的概率分布应该是“thanks”单词的概率最大。但是,由于模型的参数都是随机初始化的,所示一开始模型预测所有词的概率几乎都是随机的。

只要 Transformer 解码器预测了组概率,我们就可以把这组概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
再看一个复杂一点的句子。句子输入是:“je suis étudiant” ,输出是:“i am a student”。我们的transformer模型解码器将多次输出概率分布向量:
每次输出的概率分布都是一个向量,长度是 vocab_size(前面约定最大vocab_size,也就是向量长度是 6,但实际中的vocab_size更可能是 30000 或者 50000)
第1次输出的概率分布中,最高概率对应的单词是 “i”
第2次输出的概率分布中,最高概率对应的单词是 “am”
以此类推,直到第 5 个概率分布中,最高概率对应的单词是 “<eos>”,表示没有下一个单词了。
于是我们目标的概率分布长下面这个样子:

我们用例子中的句子训练模型,希望产生图中所示的概率分布。我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示:
 TR2
TR2
一.自注意力机制(Self-Attention)
Self Attention可以捕获同一个句子中词与词之间的一些句法特征。很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。

下面来分析一下上图中 Self-Attention 层的具体机制。假设我们想要翻译的句子是:The animal didn't cross the street because it was too tired
这个句子中的 it 是一个指代词,那么 it 指的是什么呢?它是指 animal 还是street?这个对模型来说并不是那么容易。但是,如果模型引入了Self Attention机制之后,便能够让模型把 it 和 animal 关联起来了。同样的,当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
TR3 Pytorch复现Transformer
一.论文摘要
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder.主要序列转导模型基于复杂的循环或卷积神经网络,包括编码器和解码器。
The best performing models also connect the encoder and decoder through an attention
mechanism.性能最好的模型还通过注意力机制连接编码器和解码器。
We propose a new simple network architecture, the Transformer,based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
我们提出了一种新的简单网络架构——Transformer,它完全基于注意力机制,完全不需要递归和卷积。
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
对两个机器翻译任务的实验表明,这些模型具有卓越的质量,同时具有更高的并行性,并且需要的训练时间显着减少。
Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU.
我们的模型在 WMT 2014 英德翻译任务中获得了 28.4 BLEU,比现有的最佳结果(包括集成)提高了 2 BLEU 以上。(BLEU 是Bilingual Evaluation Understudy的缩写,最早由IBM 在2002 年提出。通过采用n-gram匹配的方式评定机器翻译结果和参考译文之间的相似度,即机器翻译的结果越接近人工参考译文就认定它的质量越高。)
On the WMT 2014 English-to-French translation task,our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature.
在 WMT 2014 英法翻译任务中,我们的模型在 8 个 GPU 上训练 3.5 天后,建立了新的单模型,最先进 BLEU 分数达到 41.8,这只是最佳模型训练成本的一小部分文献中的模型。
We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
我们通过将Transformer成功地应用于具有大量和有限训练数据的英语选区解析,证明了它可以很好地推广到其他任务。
与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
下图便是Transformer整体结构图,与seq2seq模型类似,Transformer模型结构中的左半部分为编码器,右半部分为解码器,下面我们来一步步拆解Transformer。

二、Transformer宏观结构
Transformer可以看作是seq2seq模型的一种,因此,先从seq2seq的角度对Transformer进行宏观结构的学习。以机器翻译任务为例,先将Transformer看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列。

将上图中的中间部分“THE TRANSFORMER”拆开成seq2seq标准结构,得到下图:左边是编码器部分encoders,右边是解码部分decoders。

下面,再将上图中的编码器和解码器细节绘出,得到下图。我们可以看到,编码部分由多层编码器(Encoder)组成。解码部分也是由多层的解码器(Decoder)组成。每层编码器、解码器网络结构是一样的,但是不同层编码器、解码器网络结构不共享参数。

其中,单层编码器主要由自注意力层(Self-Attention Layer)和全连接前馈网络(Feed Forward Neural Network, FFNN)与组成,如下图所示:

其中,解码器在编码器的自注意力层和全连接前馈网络中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分。

Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由自注意力层和全连接前馈网络组成,每个解码层由自注意力层、全连接前馈网络和encoder-decoder attention组成。
三、复现Transformer
1. 多头注意力机制
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
# n_heads:多头注意力的数量
# hid_dim:每个词输出的向量维度
def __init__(self, hid_dim, n_heads):
super(MultiHeadAttention, self).__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
# 强制 hid_dim 必须整除 h
assert hid_dim % n_heads == 0
# 定义 W_q 矩阵
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定义 W_k 矩阵
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定义 W_v 矩阵
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
# 缩放
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))
def forward(self, query, key, value, mask=None):
# 注意 Q,K,V的在句子长度这一个维度的数值可以一样,可以不一样。
# K: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# V: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# Q: [64,12,300], 假设batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 这里把 K Q V 矩阵拆分为多组注意力
# 最后一维就是是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度, 每个 head 的向量长度是:300/6=50
# 64 表示 batch size,6 表示有 6组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度
# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 -> [64,6,12,50]
# 转置是为了把注意力的数量 6 放到前面,把 10 和 50 放到后面,方便下面计算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# 第 1 步:Q 乘以 K的转置,除以scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention:[64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 如果 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10,这里用“0”来指示哪些位置的词向量不能被attention到,比如padding位置,当然也可以用“1”或者其他数字来指示,主要设计下面2行代码的改动。
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# 第 2 步:计算上一步结果的 softmax,再经过 dropout,得到 attention。
# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax
# attention: [64,6,12,10]
attention = torch.softmax(attention, dim=-1)
# 第三步,attention结果与V相乘,得到多头注意力的结果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# x: [64,6,12,50]
x = torch.matmul(attention, V)
# 因为 query 有 12 个词,所以把 12 放到前面,把 50 和 6 放到后面,方便下面拼接多组的结果
# x: [64,6,12,50] 转置-> [64,12,6,50]
x = x.permute(0, 2, 1, 3).contiguous()
# 这里的矩阵转换就是:把多组注意力的结果拼接起来
# 最终结果就是 [64,12,300]
# x: [64,12,6,50] -> [64,12,300]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x2.前馈传播
class Feedforward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(Feedforward, self).__init__()
# 两层线性映射和激活函数ReLU
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = torch.nn.functional.relu(self.linear1(x))
x = self.dropout(x)
x = self.linear2(x)
return x3.位置编码
class PositionalEncoding(nn.Module):
"实现位置编码"
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化Shape为(max_len, d_model)的PE (positional encoding)
pe = torch.zeros(max_len, d_model).to(device)
# 初始化一个tensor [[0, 1, 2, 3, ...]]
position = torch.arange(0, max_len).unsqueeze(1)
# 这里就是sin和cos括号中的内容,通过e和ln进行了变换
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 计算PE(pos, 2i)
pe[:, 1::2] = torch.cos(position * div_term) # 计算PE(pos, 2i+1)
pe = pe.unsqueeze(0) # 为了方便计算,在最外面在unsqueeze出一个batch
# 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来
# 这个时候就可以用register_buffer
self.register_buffer("pe", pe)
def forward(self, x):
"""
x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128
"""
# 将x和positional encoding相加。
x = x + self.pe[:, :x.size(1)].requires_grad_(False)
return self.dropout(x)4.编码层
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
# 编码器层包含自注意力机制和前馈神经网络
self.self_attn = MultiHeadAttention(d_model, n_heads)
self.feedforward = Feedforward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 前馈神经网络
ff_output = self.feedforward(x)
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x5.解码层
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
# 解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络
self.self_attn = MultiHeadAttention(d_model, n_heads)
self.enc_attn = MultiHeadAttention(d_model, n_heads)
self.feedforward = Feedforward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, self_mask, context_mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, self_mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 编码器-解码器注意力机制
attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)
x = x + self.dropout(attn_output)
x = self.norm2(x)
# 前馈神经网络
ff_output = self.feedforward(x)
x = x + self.dropout(ff_output)
x = self.norm3(x)
return x6.Transformer模型
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):
super(Transformer, self).__init__()
# Transformer 模型包含词嵌入、位置编码、编码器和解码器
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])
self.fc_out = nn.Linear(d_model, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, src, trg, src_mask, trg_mask):
# 词嵌入和位置编码
src = self.embedding(src)
src = self.positional_encoding(src)
trg = self.embedding(trg)
trg = self.positional_encoding(trg)
# 编码器
for layer in self.encoder_layers:
src = layer(src, src_mask)
# 解码器
for layer in self.decoder_layers:
trg = layer(trg, src, trg_mask, src_mask)
# 输出层
output = self.fc_out(trg)
return outputvocab_size = 10000 # 假设词汇表大小为10000
d_model = 128
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1
device = torch.device('cpu')
transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)
# 定义输入,这里的输入是假设的,需要根据实际情况修改
src = torch.randint(0, vocab_size, (32, 10)) # 源语言句子
trg = torch.randint(0, vocab_size, (32, 20)) # 目标语言句子
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置
# 模型前向传播
output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape)