Transformer 的基本概念
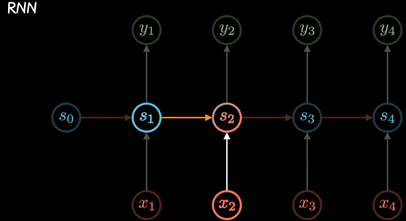
1.什么是 Transformer?:Transformer 是一种基于 Attention 机制的深度学习模型,用于机器翻译、文本分类、机器阅读等任务。
2.Transformer 的结构:Transformer 的结构包括输入 Embedding、Encoder、Decoder、Output Layer 等。
Attention 机制
1.什么是 Attention 机制?:Attention 机制是 Transformer 的核心组件,用于关注输入序列中的某个部分,以便更好地捕捉该部分的信息。
2.Attention 机制的工作原理:Attention 机制的工作原理是计算输入序列中的每个元素对其他元素的权重,然后将权重与元素的Embedding相乘,以获得最终的输出。
Encoder-Decoder 模型
1.什么是 Encoder-Decoder 模型?:Encoder-Decoder 模型是 Transformer 的基本结构,用于将输入序列编码为固定长度的向量,然后将该向量解码为输出序列。
2.Encoder-Decoder 模型的工作原理:Encoder-Decoder 模型的工作原理是将输入序列输入 Encoder,得到固定长度的向量,然后将该向量输入 Decoder,输出最终的输出序列。
Sequence-to-Sequence 任务
1.什么是 Sequence-to-Sequence 任务?:Sequence-to-Sequence 任务是指将输入序列翻译为输出序列的任务,例如机器翻译、文本生成等。
2.Sequence-to-Sequence 任务的实现:Sequence-to-Sequence 任务的实现可以使用 Transformer 模型, encoder 将输入序列编码为固定长度的向量,然后将该向量输入 Decoder,输出最终的输出序列。
案例代码
以下是一个使用 Transformer 进行机器翻译的案例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# 加载数据
train_data = ...
test_data = ...
# 创建数据集
class TranslationDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.tokenizer = tokenizer
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
src_text = self.data[idx][0]
tgt_text = self.data[idx][1]
src_encoding = self.tokenizer.encode(src_text, return_tensors='pt')
tgt_encoding = self.tokenizer.encode(tgt_text, return_tensors='pt')
return {
'src_encoding': src_encoding,
'tgt_encoding': tgt_encoding
}
# 创建数据加载器
train_dataset = TranslationDataset(train_data, tokenizer)
test_dataset = TranslationDataset(test_data, tokenizer)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 创建Transformer 模型
model = AutoModelForSeq2SeqLM.from_pretrained('t5-base')
# 训练模型
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(5):
model.train()
total_loss = 0
for batch in train_loader:
src_encoding = batch['src_encoding'].to(device)
tgt_encoding = batch['tgt_encoding'].to(device)
optimizer.zero_grad()
output = model(src_encoding, tgt_encoding)
loss = criterion(output, tgt_encoding)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss / len(train_loader)}')
# 评估模型
model.eval()
test_loss = 0
with torch.no_grad():
for batch in test_loader:
src_encoding = batch['src_encoding'].to(device)
tgt_encoding = batch['tgt_encoding'].to(device)
output = model(src_encoding, tgt_encoding)
loss = criterion(output, tgt_encoding)
test_loss += loss.item()
print(f'Test Loss: {test_loss / len(test_loader)}')