1.transformer的优化策略
1)GQA,减少推理过程中的KV缓存大小,增加上下文长度(KV 缓存(即 Key-Value 缓存)用于加速 Transformer 模型在推理过程中处理长序列时的计算。要减少 KV 缓存的大小)
2)投机采样(小马拉大车):小模型推理,大模型进行验证
3)RWKV,对attention进行魔改,通过将Q,K,V之间的耦合关系转换为K,V之间的关联,从而实现快速计算;引入RNN的结果,通过将当前时刻和前一时刻进行甲醛,形成一个类似于RNN的结构,从而实现速度的提升
4)infini-transformer:谷歌提出的infini-transformer框架,该框架在分段的基础上引入了历史信息,以提高上下文支持。同时,视频还介绍了硬件加速技术RAIN attention,通过分组和改进注意力计算方式,实现了更高的并行度和效率。最后,视频提到了将长序列拆分成块并自己计算注意力的方法,以进一步提高效率
5)flash attention :和RAIN attention差不多,但用的是硬件结构进行计算和减少存储量
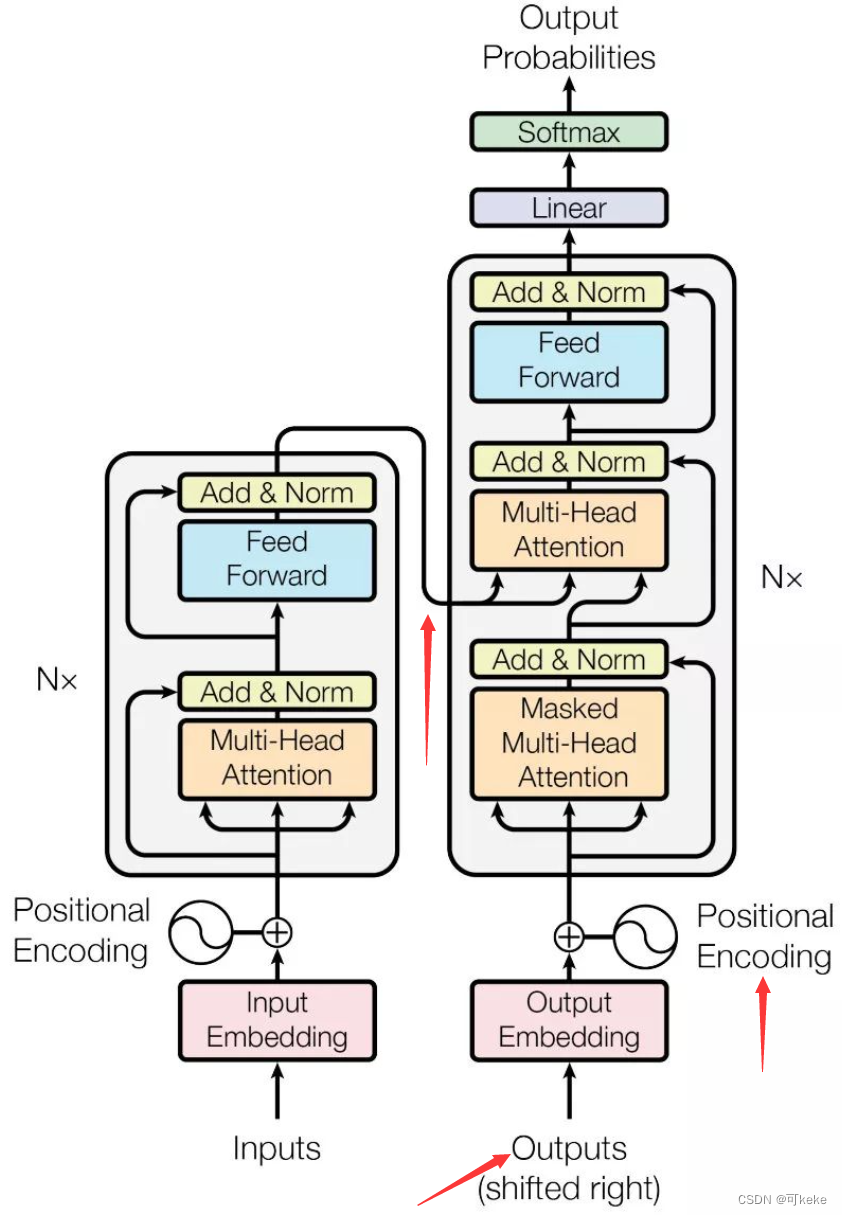
2.transformer模型的基本原理:
1)由多注意力机制(attention的作用是获取上下文信息)和一个FNN前馈神经网络组成(FNN位于每个Transformer层中的多头自注意力机制之后。FNN通常由两个全连接层(也称为线性层)和一个激活函数(通常是ReLU)组成),用来存储知识)
2)利用了resnet的模式(是一种深度神经网络结构,用于解决深层网络中的梯度消失和梯度爆炸问题。其核心思想是引入残差连接(residual connections),允许信息绕过一个或多个层的直接路径,从而促进梯度的反向传播。具体来说,ResNet中的每一层输出不是简单的层输出,而是层输出加上输入的和:),解决了快速收敛和梯度问题;
3)有encode和decode两种模式,前者可以看到去拿不信息,后者可以看到部分信息(Transformer模型由编码器(Encoder)和解码器(Decoder)组成,两者共同用于序列到序列的任务(如机器翻译)。每个编码器和解码器都包含多个层,结构相似但功能不同。)(输入序列 -> 编码器 -> 编码表示)(编码表示, 目标序列的一部分 -> 解码器 -> 输出序列
)
4)红色模块用于信息融合(非必须),广泛用于多模态,机器翻译等场景
3.transformer模型BN和LN的区别
1)都是对数据进行正规化,将输入数据归一至正态分布,加速收敛,提高训练的稳定性
2)BN:一个batch的向量,同一纬度的数据做正规化,缺点是变长数据无法处理,语义数据无法处理,所以有了LN
3)LN:序列向量中,不同时刻的向量做正规化
4.preNorm和postNorm的区别
1)位置不同:
Pre-Norm:Layer Normalization在子层之前。
Post-Norm:Layer Normalization在子层之后。
2)训练稳定性:
Pre-Norm:在训练早期更稳定,因为规范化在每个子层之前进行,防止梯度爆炸或消失问题。
Post-Norm:在训练早期可能不如pre-norm稳定,但在训练中后期,模型性能通常更好。
3)性能差异:
Pre-Norm:由于规范化在子层之前进行,可能导致信息在层与层之间传播得更有效,收敛更快。
Post-Norm:虽然在训练早期可能收敛较慢,但在模型训练后期,通常能达到更好的性能。
4)应用场景:
Pre-Norm:在一些更深的网络或初期训练更困难的模型中,预规范化可以提供更稳定的梯度,防止训练过程中的数值问题。
Post-Norm:在更浅的网络或训练过程较为平稳的模型中,后规范化通常能够取得更好的最终性能。
5.多抽头、self-attention中使用QKV三个不同矩阵的原因,以及其原理和作用
1)使用Q、K、V三个不同矩阵的主要原因包括:
丰富表达能力:通过不同的线性变换,可以捕捉输入序列中的不同特征和关系,从而使模型具有更丰富的表达能力。
提高注意力计算的灵活性:将输入映射到不同的空间,可以更灵活地计算注意力权重,从而提高模型对上下文的理解能力。
多头机制的实现:通过多个头(多个不同的Q、K、V矩阵),可以并行地处理输入数据,从不同角度进行注意力计算,从而增强模型的稳定性和泛化能力。
2)自注意力机制通过计算序列中每个位置与其他位置之间的相关性(注意力权重)来捕捉输入序列中的依赖关系。
3)多头注意力机制通过并行地计算多个自注意力
具体步骤
输入嵌入:输入序列通过嵌入层(Embedding Layer)得到向量表示
线性变换:使用三个线性变换矩阵 Q,K,V将输入序列转换为查询、键和值矩阵 Q、K 和V。
计算注意力权重:通过点积计算查询和键之间的相似度,然后使用Softmax函数归一化,得到注意力权重。
加权求和:使用注意力权重对值矩阵进行加权求和,得到输出表示。
多头注意力:并行计算多个自注意力,然后将它们的输出拼接起来,通过线性变换得到最终的输出。
AI学习必备【transformer模型优化策略】 如何解决transformer模型时间复杂度过高问题?面试中如何回答transformer原理?大模型开发_哔哩哔哩_bilibili

深入了解Transformer:从编码器到解码器的神经网络之旅
2024-07-09 22:06:03 35 阅读



























![AGI 之 【Hugging Face】 的【文本分类】的[数据集][文本转换成词元]的简单整理](https://img-blog.csdnimg.cn/direct/d35548882c924612aadf3dab23f14c7a.jpeg)





![[图解]SysML和EA建模住宅安全系统-11-接口块](https://i-blog.csdnimg.cn/direct/207edd63f2af4292a3d15d2a35534363.png)