分类问题的loss
- MSE
- Cross Entropy Loss
- Hinge Loss (SVN用的比较多)
- ∑ i m a x ( 0 , 1 − y i ∗ h θ ( x i ) ) \sum_imax(0,1-y_i*h_\theta(x_i)) ∑imax(0,1−yi∗hθ(xi))
Entropy(熵)
- Uncertainty(也叫不确定性)
- measure of surprise(惊喜度)
- higher entropy = less info
- E n t r o p y = − ∑ i P ( i ) log P ( i ) Entropy=-\sum_iP(i)\log P(i) Entropy=−∑iP(i)logP(i)
Entropy就是熵,也叫做不确定性,从某种程度上讲是惊喜度
比如你长得很帅,我说你很帅,这句话的内容就比较少,uncertainty就比较低,entropy比较高
比如某个人能力很差,但是有一天中了大奖,这个消息的Uncertainty就比较高,信息量就比较大,就是说没有能力但是却突然很有钱了,意味着这句话很惊喜,Uncertainty比较高,entropy比较低
entropy定义为每个i的probability再乘以log probability
具体的例子

熵稳定效应是指在信息论中,熵越高的系统越不稳定,而熵越低的系统越稳定。
每个数字的中奖概率相同时,这个分布的熵比较高,因为不确定性大(不知道哪个数字会中奖)
a为[0.1,0.1,0.1,0.7]的时候,4这个数字的中奖率比较高,其他数字的中奖率只有0.1。此时的熵是比较低的。这是因为熵是衡量随机变量不确定性的度量,而在这个分布中,数字4的中奖概率远高于其他数字,这意味着结果的不确定性较低,因为数字4的中奖几乎是确定的。
a为[0.001,0.001,0.001,0.999]的时候,非常极端的情况,前面都不可能中奖,这个熵非常低,因为几乎可以确定第四个结果会发生
Cross Entropy (交叉熵)
Entropy:指的是一个分布,比如说p本身的一个稳定性
Cross Entropy (交叉熵):一般指的是两个分布,衡量两个分布的稳定性

第一步可以推导为第二步 H ( p ) H(p) H(p)再加上 D k l ( p ∣ q ) D_{kl}(p|q) Dkl(p∣q), D k l ( p ∣ q ) D_{kl}(p|q) Dkl(p∣q)这一部分是kl divergence,也叫KL散度,是真正衡量两个概率分布差异的方法
举例,两个高斯分布

重叠部分比较少,因此它的kl散度比较高,假设是2
完全重合,kl散度就接近于0了
根据定义如果P和Q相等,cross Entropy = Entropy
如果采用01编码比如说[0,1,0,0]只有第二项是1,所以是1log1,所以entropy是0 ,一般分类问题都是01编码,对于01编码来说,这个H§的entropy就等于0,然后根据H(p,q)推导之后的式子,如果H( p )等于0的话,H(p,q)就等于 D k l ( p ∣ q ) D_{kl}(p|q) Dkl(p∣q),也就意味着当我们去优化P和Q的交叉熵的时候,如果是01编码相当于直接优化P和Q的KL散度,KL散度刚好衡量的是两个分布重叠的情况,如果用网络预测出θ条件的分布,还有一个真实的分布,这两个分布的kl散度接近于0的话,意味着P=Q,恰好是我们需要的情况
cross entropy 对于01编码来说就是kl散度,而kl散度又说明了,如果交叉熵接近于0那kl散度就接近于0,意味着p和q的分布越来越近,恰好是我们要优化的目标
二分类问题
二分类问题的交叉熵如何运算

首先H(P,Q)是P乘以log Q再求和的问题

只有cat和dog两种分类,所以只有两种求和,但是由于P(dog)=1-P(cat),也就是说非猫即狗,这里假设P(cat)是y,Q(cat)是p,那式子就可以改写为y和p的式子,因为PQ分布使用的是01编码,所以y就是实际的值,p就是模型预测出的概率分布,由于二分类问题,非猫即狗,最后就会得出上图中y和p的表达式
如何解释这个y和p的表达式
如果y等于1的话,式子等于H(P,Q)=-log p,要最小化这个式子,有负号所以要最大化log p,即最大化p,最大化输入x,y=1的概率
如果y等于0的话,式子等于H(P,Q)=-log(1-p),要最小化这个式子,有负号所以要最大化log(1-p),就是要最小化p,最小化输入x,y=1的概率,即最大化输入x,y=0的概率(切记这里是二分类,不是0就是1)
例子:

当前的实例时一只小狗,P值就是真实分布,Q值就是模型预测分布,经过softmax预测是对的,但是可能性不高,看一下交叉熵约等于0.9
如果变成图右下角的情况就非常理想,狗的概率就非常高,这时交叉熵是0.02,也就是说变好了,交叉熵也从0.9下降到了0.02,说明了 p θ p_{θ} pθ越来越逼近 p r p_{r} pr
可以看出与MSE一样,都能够很好的迫使我们的预测朝着我们想要的方向去进行
总结

为什么分类问题不适用MSE,而使用Cross Entropy?
- 如果使用sigmoid和mse搭配的话,很容易出现sigmoid饱和的情况,会出现梯度弥散
- cross entropy概率的梯度信息更大,更容易收敛的更快,比如说当前label趋近于1,如果q的分布没有靠近1的话,例如在左端,就会发现loss会非常大,所以梯度会很大,会收敛的很快,当接近于1的时候,梯度就开始慢慢变小
- 如果发现cross entropy不行也可以试mse,因为mse的梯度求导更加简单

神经网络的结构,最后一层(可以横着看)叫logit,后面经过softmax层再经过cross entropy做计算,对于pytorch来说灰色部分是由一个现成的网络结构的,如果把softmax和cross entropy分开的话会出现一个数据不稳定的情况,所以一般不建议大家直接自己用softmax来处理,最好直接得到logit的输出以后,用pytorch一次完成不要自己去处理,因为会出现数据不稳定的情况
实例

F.cross_entropy函数中必须使用logits,因为pytorch中已经把softmax和log打包再一起了,如果传入pred_log就意味着再做一遍softmax,会导致数据非常小
如果一定要自己计算的话用F.nll_loss就行,但是这里就必须传入softmax之后的数据
F.cross_entropy函数等于softmax操作+log操作+F.nll_loss操作




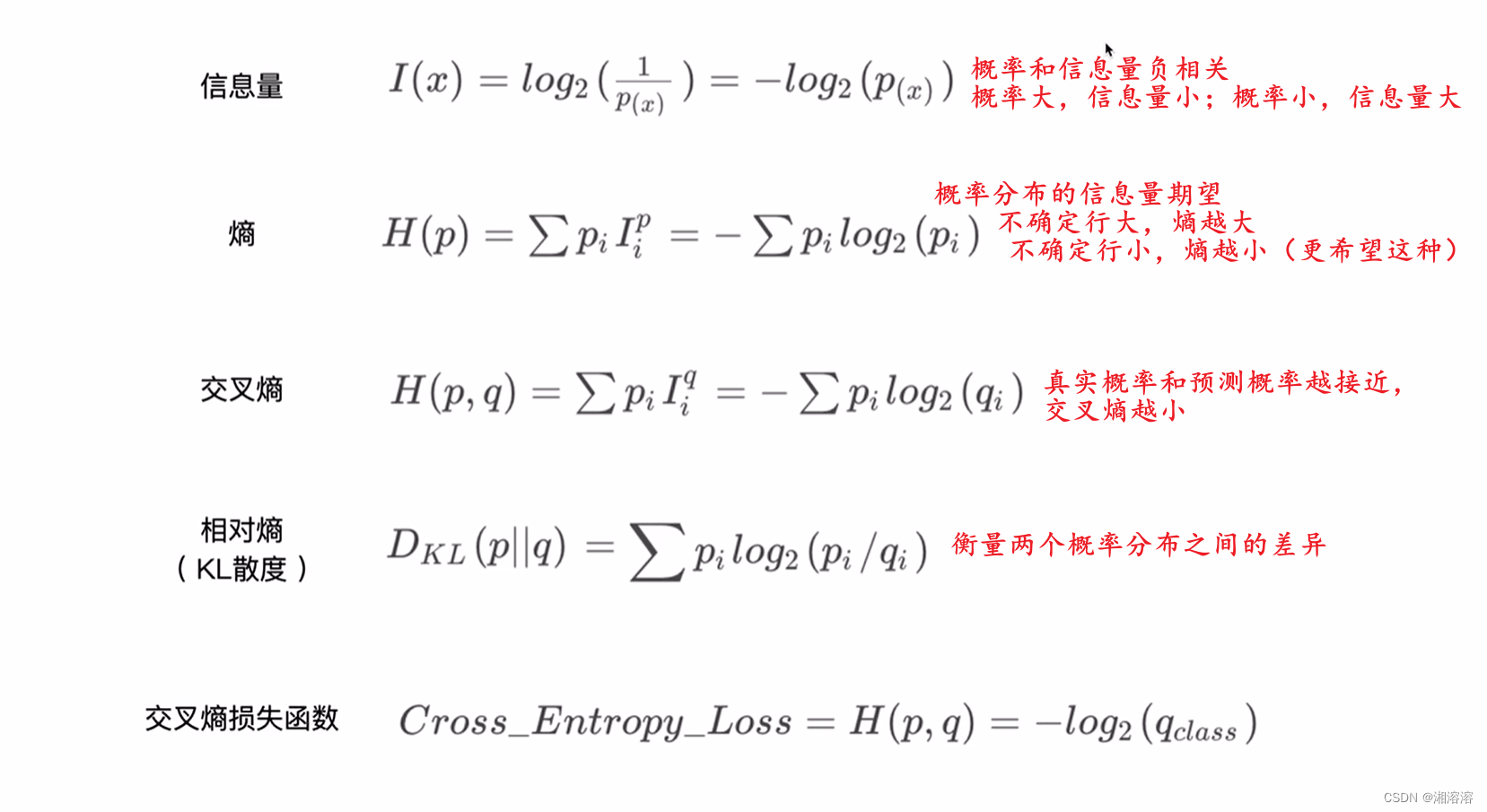



























![【代码随想录】【算法训练营】【第64天】 [卡码117]软件构建 [卡码47]参加科学大会](https://i-blog.csdnimg.cn/direct/c8ea8db58bfc4c51a78c159549330323.png)