开篇:探索稀疏多视图图像的3D场景重建与新视角合成的挑战
3D场景重建和新视角合成是计算机视觉领域的一项基础挑战,尤其是当输入图像非常稀疏(例如,只有两张)时。尽管利用神经场景表示,例如场景表示网络(SRN)、神经辐射场(NeRF)和光场网络(LFN)等,取得了显著进展,但这些方法在实际应用中仍然不尽人意,原因包括每个场景的优化成本高昂、内存消耗大以及渲染速度慢。最近,3D高斯投影(3DGS)作为一种高效且表达力强的3D表示方法应运而生,它凭借快速的渲染速度和高质量成为了研究的热点。使用基于光栅化的渲染,3DGS天然避免了NeRF中昂贵的体积采样过程,从而实现了高效且高质量的3D重建和新视角合成。
接下来提出的几种前馈高斯投影方法,如Splatter Image和pixelSplat,尝试从稀疏视图图像进行3D重建。Splatter Image使用U-Net架构从单一视图回归像素对齐的高斯参数,取得了单个对象3D重建的有希望的结果。然而,从单个图像进行3D重建本质上是不适定的和模糊的,这使得它特别难以应用于更一般和更大的场景级别重建。对于一般场景重建,pixelSplat提出从两个输入视图回归高斯参数。尽管pixelSplat学习了具有环视变换器的跨视图感知特征,但仅从图像特征预测可靠的概率深度分布仍然具有挑战性,导致pixelSplat的几何重建质量相对较低且存在噪声伪影。为了改进几何重建结果,需要使用额外的深度正则化损失进行缓慢的深度微调。
为了准确定位3D高斯中心,我们提出通过在3D空间中进行平面扫描来构建代价体积表示。具体来说,代价体积存储了所有潜在深度候选项的跨视图特征相似性,这些相似性可以为3D表面的定位提供有价值的几何线索。通过我们的代价体积表示,任务被表述为学习执行特征匹配以识别高斯中心,而不是像以前的工作那样从图像特征中进行数据驱动的3D回归。这样的表述降低了任务的学习难度,使我们的方法能够以轻量级模型大小和快速速度实现最先进的性能。
我们通过将由我们构建的多视图代价体积估计的多视图一致深度反投影到3D空间中,获得3D高斯中心。此外,我们还并行预测其他高斯属性(协方差、不透明度和球谐系数),从而使用预测的3D高斯和可微分的投影操作渲染新视角图像。我们的完整模型MVSplat是端到端训练的,仅使用渲染和真实图像之间的光度损失进行监督。
在大规模的RealEstate10K和ACID基准测试中,我们基于代价体积的方法MVSplat以最快的前馈推理速度(22 fps)实现了最先进的性能。与最先进的pixelSplat相比,我们的模型使用了更少的参数,并且在提供更高的外观和几何质量以及更好的跨数据集泛化能力的同时,推理速度提高了2倍以上。广泛的消融研究和分析强调了我们基于特征匹配的代价体积设计在实现高效前馈3D高斯投影模型方面的重要性。
论文标题: MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
机构:
1. Monash University
2. ETH Zurich
3. University of Tübingen, Tübingen AI Center
4. University of Oxford
5. Microsoft
6. Nanyang Technological University
论文链接:https://arxiv.org/pdf/2403.14627.pdf
项目地址: https://donydchen.github.io/mvsplat
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
3D高斯投影(3DGS)的介绍与优势
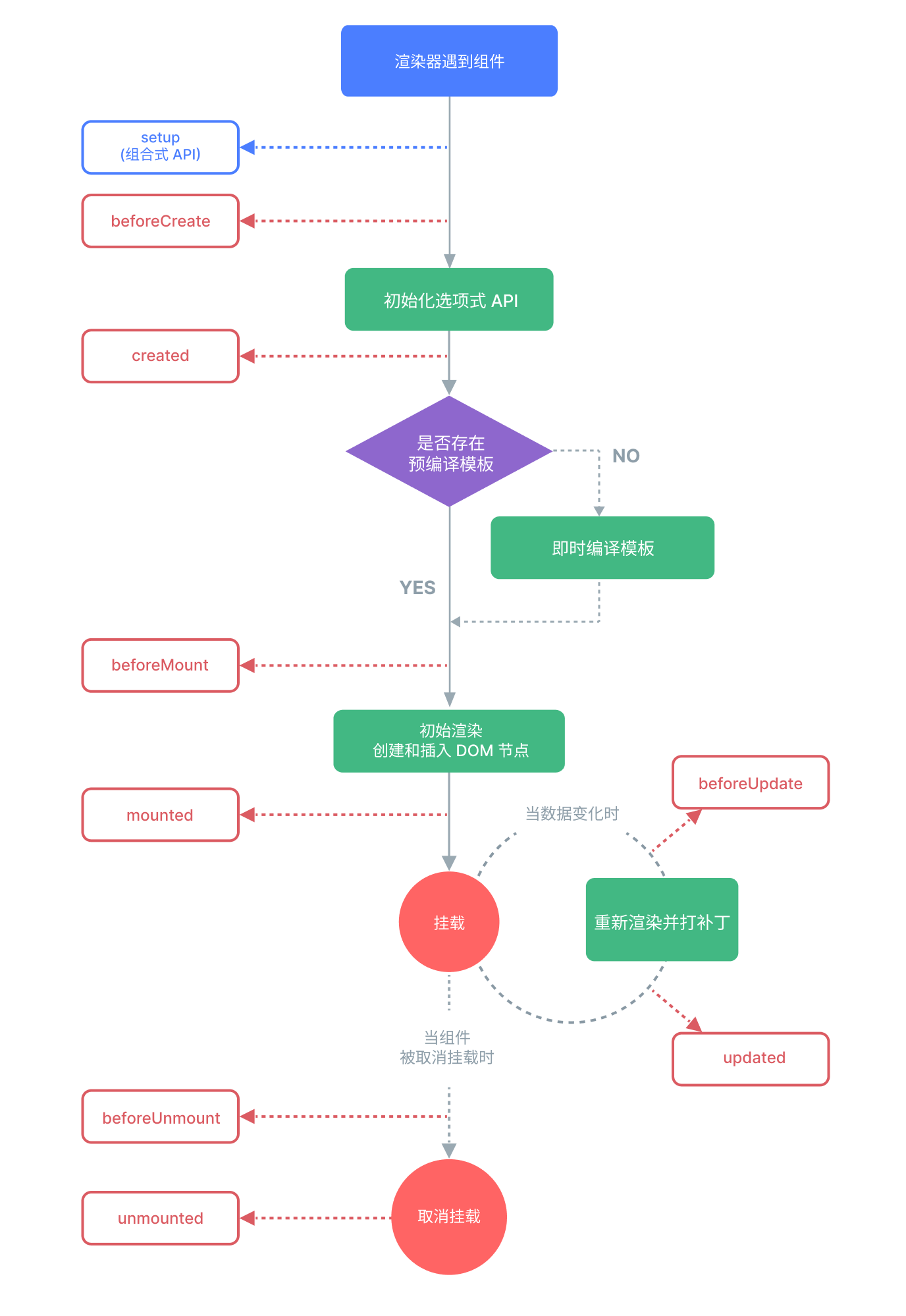
3D高斯投影(3D Gaussian Splatting,简称3DGS)是一种高效且表现力强的三维表示方法,它因其快速的渲染速度和高质量的重建而受到关注。3DGS使用基于光栅化的渲染方法,从而避免了NeRF中昂贵的体积采样过程,实现了高效率和高质量的3D重建及新视角合成。
1. 3DGS的工作原理:3DGS通过将3D高斯(Gaussian primitives)映射到图像平面上,避免了传统NeRF方法中的体积渲染,从而大幅提高了渲染速度。这些高斯原语由中心位置、协方差、不透明度和颜色参数定义,可以高效地用于渲染新视角的图像。
2. 3DGS的优势:与传统的NeRF方法相比,3DGS具有多个显著优势。首先,它的渲染速度快,因为它避免了昂贵的体积采样过程。其次,3DGS在处理稀疏视图输入时表现出色,这对于实际应用中捕获大量视图是不切实际的情况尤为重要。此外,3DGS能够在轻量级模型和快速速度的同时,提供更高的外观和几何质量,以及更好的跨数据集泛化能力。
MVSplat模型的核心设计
MVSplat是一个基于3DGS的前馈模型,它通过构建成本体积(cost volume)来利用多视图的对应信息,从而更好地学习几何结构。与之前依赖于数据驱动设计的方法不同,MVSplat的核心设计在于其有效地利用特征匹配信息来预测3D高斯中心,从而实现了高效的深度估计。
1. 成本体积的构建:MVSplat通过平面扫描技术在3D空间中构建成本体积,存储了所有潜在深度候选项的跨视图特征相似性。这些相似性为3D表面的定位提供了宝贵的几何线索,使得模型能够通过特征匹配来识别3D高斯中心。
2. 多视图深度估计:MVSplat的深度模型基于2D卷积和注意力机制,不使用许多先前MVS和前馈NeRF模型中的3D卷积,这使得模型高效。深度模型包括多视图特征提取、成本体积构建、成本体积细化、深度估计和深度细化等步骤。
3. 3D高斯参数的预测:在获得多视图深度预测后,MVSplat直接将它们投影到3D点云中,并将每个视图的点云转换为对齐的世界坐标系,直接组合为3D高斯的中心。同时,模型还并行预测其他高斯属性(协方差、不透明度和颜色参数),以便使用可微分的投影操作渲染新视角图像。
4. 训练损失:MVSplat使用简单的渲染损失进行端到端训练,通过预测的3D高斯参数渲染图像,并以真实目标RGB图像作为监督,计算训练损失。
MVSplat在大规模RealEstate10K和ACID基准测试中取得了最先进的性能,并以最快的前馈推理速度(22 fps)运行。与最新的pixelSplat模型相比,MVSplat使用了更少的参数,并且推理速度更快,同时提供了更高的外观和几何质量,以及更好的跨数据集泛化能力。
实验设置与数据集描述
1. 数据集
本研究使用了两个大型基准数据集:RealEstate10K [42] 和 ACID [14]。RealEstate10K 数据集包含从 YouTube 下载的房地产视频,分为 67,477 个训练场景和 7,289 个测试场景。ACID 数据集包含由无人机拍摄的自然场景,分为 11,075 个训练场景和 1,972 个测试场景。两个数据集都提供了每个帧的估计相机内参和外参。此外,为了进一步评估跨数据集的泛化能力,还在多视图 DTU [10] 数据集上进行了直接评估,该数据集包含带有相机位姿的以物体为中心的场景,在 DTU 数据集上,我们报告了 16 个验证场景的结果,每个场景有 4 个新视角。
2. 评价指标
量化结果使用标准图像质量指标,包括像素级的 PSNR、补丁级的 SSIM [31] 和特征级的 LPIPS [40]。同时报告了推理时间和模型参数,以便全面比较速度和准确性的权衡。为了公平比较,所有实验都在 256×256 分辨率下进行,以符合现有模型 [1, 27]。
3. 实现细节
MVSplat 使用 PyTorch 实现,并使用 CUDA 中的现成 3DGS 渲染器。多视图 Transformer 包含 6 层堆叠的自注意力和交叉注意力层。构建成本体积时,在所有实验中采样了 128 个深度候选项。所有模型在单个 A100 GPU 上训练了 300,000 次迭代,使用 Adam [13] 优化器。更多细节在补充材料 Appendix C 中提供。代码和模型可在 https://github.com/donydchen/mvsplat 获取。
主要结果与性能分析
1. 图像质量评估
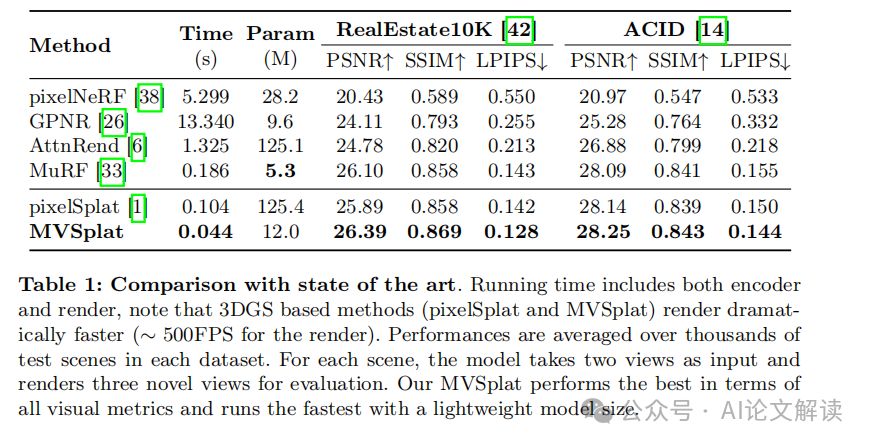
在 RealEstate10K [42] 和 ACID [14] 基准测试中,MVSplat 在所有视觉质量指标上超越了所有先前的最先进模型,并且在 LPIPS 指标上有更明显的改进,该指标更符合人类感知。MVSplat 在具有挑战性的条件下,即使在只有一个输入视图中呈现的区域(例如“楼梯扶手”和“灯罩”)或从远处视点捕获的大型户外物体(例如“桥梁”),也能实现最高质量的新视图结果。
2. 模型效率评估
MVSplat 不仅在图像质量上表现优异,而且在所有比较模型中具有最快的推理时间,并且模型尺寸轻巧,展示了其效率和实用性。MVSplat 使用的参数比 pixelSplat [1] 少 10 倍,并且推理速度快于 2 倍以上。
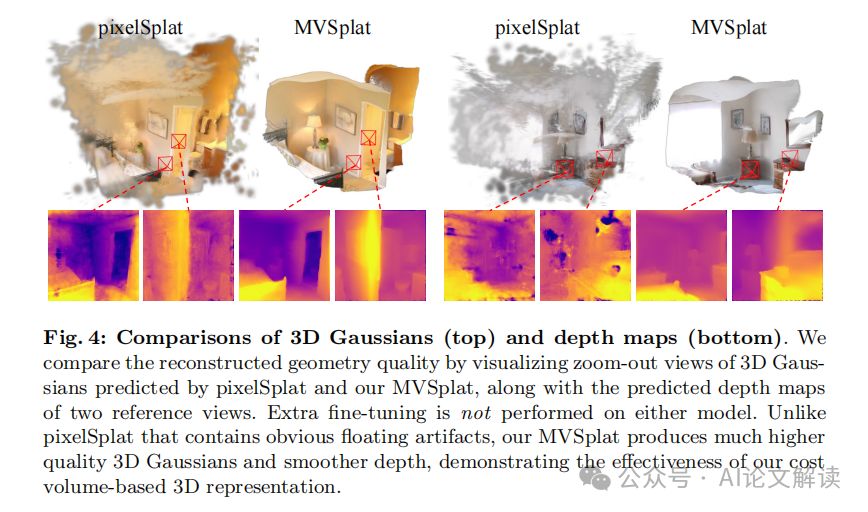
3. 几何重建评估
MVSplat 生成的 3D 高斯原语质量显著高于最新的最先进模型 pixelSplat [1]。pixelSplat 需要额外的 50,000 步微调,使用额外的深度正则化损失来实现合理的几何重建结果。而 MVSplat 仅通过光度监督训练,就能生成高质量的几何结构。
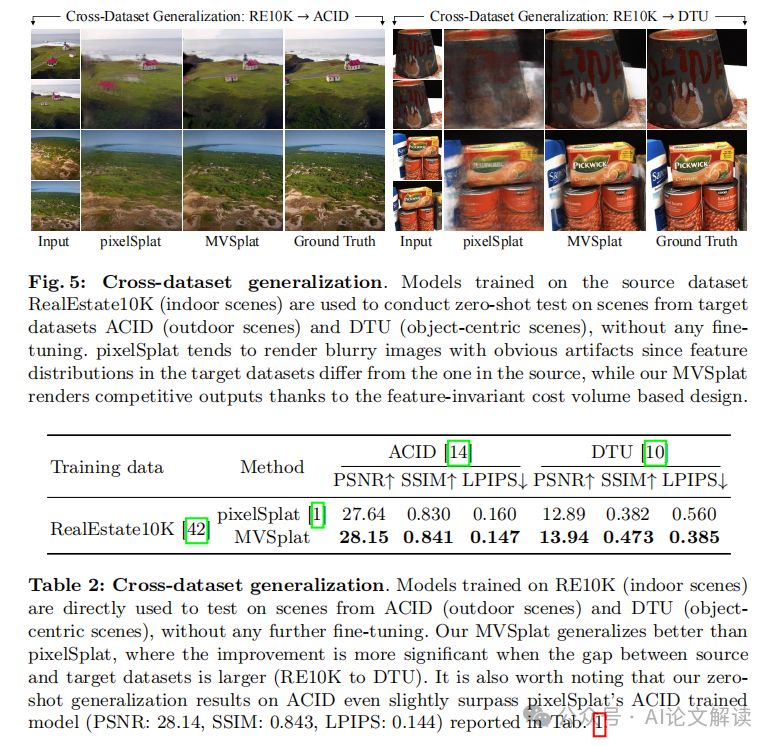
4. 跨数据集泛化评估
MVSplat 在泛化到分布外的新场景方面具有固有的优势,主要是因为成本体积捕获了特征之间的相对相似性,这与特征的绝对尺度相比保持不变。在两个跨数据集评估中,MVSplat 渲染出的新视图具有竞争力,尽管目标数据集的场景包含与源数据集显著不同的相机分布和图像外观。相比之下,pixelSplat 渲染的视图严重退化,这主要是因为 pixelSplat 依赖于与特征值的绝对尺度相关的纯特征聚合,这阻碍了其在接收来自其他数据集的不同图像特征时的性能。
5. 更多视图质量评估
MVSplat 设计为对输入视图的数量不敏感,因此如果在测试阶段有更多输入视图可用,无论在训练中使用了多少输入视图,都可以从中受益。在 DTU 上使用 3 个上下文视图进行测试时,MVSplat 的结果优于使用 2 个视图的结果,这表明 MVSplat 可以利用更多的输入视图来提高性能。
6. 消融研究
通过在 RealEstate10K 上进行详尽的消融研究,分析了 MVSplat 的关键组件。结果表明,成本体积是 MVSplat 成功的关键,它在编码器中发挥着最重要的作用,提供了更好的几何质量。此外,交叉视图注意力在学习多视图几何结构中也非常重要,它通过在输入视图之间融合信息来增强特征表达能力。
跨数据集泛化能力的评估
在计算机视觉领域,从稀疏的图像(例如,仅两张)进行3D场景重建和新视角合成一直是一个基本挑战。虽然使用神经场景表示(如SRN、NeRF和LFN)取得了显著进展,但这些方法在实际应用中仍不尽人意,原因在于每个场景的昂贵优化成本、高内存消耗和慢渲染速度。最近,基于成本体积的方法MVSplat在大规模RealEstate10K和ACID基准测试中实现了最先进的性能,具有最快的前馈推理速度(22 fps),并且在外观和几何质量以及跨数据集泛化方面都优于最新的pixelSplat模型。
1. 跨数据集泛化能力
MVSplat的跨数据集泛化能力得益于其成本体积表示,该表示捕获了特征之间的相对相似性,这种相似性与特征的绝对尺度相比是不变的。为了评估这种泛化能力,研究人员选择了仅在RealEstate10K(室内场景)上训练的模型,并直接在ACID(室外场景)和DTU(以物体为中心的场景)上进行了测试。结果显示,尽管目标数据集的场景与源数据集在相机分布和图像外观上有显著差异,MVSplat仍能渲染出具有竞争力的新视图。相比之下,pixelSplat在渲染质量上明显下降,主要原因是它依赖于与特征值的绝对尺度相关的纯特征聚合,这在接收来自其他数据集的不同图像特征时会影响其性能。
2. 更多视图的质量
MVSplat的设计使其对输入视图的数量不敏感,这意味着如果在测试阶段有更多的输入视图可用,无论在训练中使用了多少输入视图,它都可以从中受益。通过在DTU上使用3个上下文视图进行测试,使用在2视图RealEstate10K数据集上训练的模型,MVSplat的性能得到了提升。然而,pixelSplat在使用更多视图时性能略有下降,即使研究人员已经尽力将其发布的仅支持2视图的模型扩展到支持更多视图的测试。这表明,更多视图的特征分布可能与用于训练pixelSplat的两视图特征分布不同,这种依赖于纯特征聚合的方法缺乏对特征分布变化的鲁棒性。
模型的优化与改进
1. 模型优化
为了提高模型性能,MVSplat采用了多种优化策略。首先,它基于2D卷积和注意力机制,避免了许多以前的MVS和前馈NeRF模型中使用的3D卷积,从而提高了模型效率。其次,MVSplat通过构建成本体积来存储所有潜在深度候选项的跨视图特征相似性,这些相似性为3D表面的定位提供了宝贵的几何线索。此外,MVSplat还使用了一个轻量级的2D U-Net来进一步细化成本体积,并预测每个视图的深度图。这些深度图被投影到3D空间,并与其他高斯属性(协方差、不透明度和球面谐波系数)一起预测,以使用可微分的splatting操作渲染新视图。
2. 模型改进
MVSplat的改进主要体现在以下几个方面:
成本体积表示:通过平面扫描在3D空间中构建成本体积表示,为学习特征匹配以识别高斯中心提供了一个新的公式化方法,与以前的数据驱动3D回归方法不同。
多视图深度估计:MVSplat的深度模型仅基于2D卷积和注意力,不使用其他模型中的3D卷积,提高了模型效率。
高斯参数预测:通过直接从多视图深度预测中投影得到的3D点云作为高斯中心,同时预测不透明度、协方差和颜色参数。
训练损失:模型使用简单的渲染损失进行端到端训练,无需地面真实几何监督。
通过这些优化和改进,MVSplat在两个大规模场景级重建基准测试中树立了新的最先进水平,并且在外观和几何质量以及跨数据集泛化方面都优于最新的pixelSplat模型。
讨论与总结
在本文中,我们探讨了从稀疏多视图图像进行3D场景重建和新视角合成的挑战,并介绍了最近提出的MVSplat模型。MVSplat模型通过构建代价体积(cost volume)来利用多视图间的对应信息,从而更好地学习几何结构。这种方法与现有的数据驱动设计有所不同,使得MVSplat在两个大规模场景级重建基准测试中设定了新的最高标准。与最新的先进方法pixelSplat相比,MVSplat使用的参数少了10倍,推断速度快了2倍以上,同时提供了更高的外观和几何质量,以及更好的跨数据集泛化能力。
1. 成果总结
MVSplat模型在多个方面展现了其优越性。首先,它在RealEstate10K和ACID基准测试中取得了最佳的视觉质量指标,并且具有最快的前馈推断速度(22 fps),这证明了其在实际应用中的高效性和实用性。其次,MVSplat在几何重建方面也展现了显著的优势,能够在没有额外深度微调的情况下,通过光度监督单独训练,生成高质量的3D高斯原语。此外,MVSplat在跨数据集泛化能力方面表现出色,尤其是在源数据集与目标数据集之间存在较大差异时,其性能提升更为显著。
2. 技术细节
MVSplat模型的关键在于其代价体积表示,该表示存储了所有潜在深度候选项的跨视图特征相似性,为3D表面的定位提供了有价值的几何线索。与之前的工作不同,MVSplat的任务被构建为学习执行特征匹配以识别3D高斯中心,这降低了任务的学习难度,并使得模型能够以轻量级的模型大小和快速的速度实现最先进的性能。
3. 实验结果
MVSplat在多个实验中均展现了其优势。在RealEstate10K和ACID数据集上的定量结果表明,MVSplat在所有视觉质量指标上均优于先前的最佳模型。在几何重建质量的可视化比较中,MVSplat产生的3D高斯原语和平滑深度图表现出更高的质量。在跨数据集泛化测试中,MVSplat在未经训练的新数据集上的渲染质量也远超pixelSplat,这进一步证明了其代价体积设计的有效性。
4. 未来方向
尽管MVSplat在多个方面取得了显著的成果,但它在处理反射表面(如玻璃和窗户)时可能产生不可靠的结果,这是现有方法的一个公开挑战。此外,MVSplat目前主要在RealEstate10K数据集上进行训练,尽管其规模较大,但多样性不足以健壮地泛化到野外真实世界场景。未来的一个有趣方向是探索MVSplat模型扩展到更大和更多样化的训练数据集的可能性,例如通过混合现有的几个场景级数据集。
总之,MVSplat模型的提出为稀疏多视图图像的3D场景重建和新视角合成提供了一种高效且有效的解决方案,其优异的性能和泛化能力预示着在实际应用中具有巨大的潜力。





![<span style='color:red;'>微</span><span style='color:red;'>软</span>云<span style='color:red;'>计算</span>[<span style='color:red;'>3</span>]之Windows Azure AppFabric](https://img-blog.csdnimg.cn/direct/fd0cb7b745304beb91bbde6421bc4b93.png)