Transformer 论文逐段精读【论文精读】
参考跟李沐学AI: 精读transformer
📝摘要
- 主流的序列转录模型包括一个 encoder 和一个 decoder 的 RNN 或者 CNN 架构。
sequence transduction: 序列转录,序列到序列的生成。input 一个序列,output 一个序列。e.g. 机器翻译:输入一句中文,输出一句英文。
- 表现好的序列转录模型:用了 attention,本文提出仅仅基于 attention 的 Transformer。
- 实验总结 - 并行化、更少时间训练。2 个机器翻译任务的实验结果达到 SOTA。并且能很好的泛化到其他任务。
📜结论
- 介绍了 Transformer 模型,第一个仅仅使用注意力、做序列转录的模型,把之前在 encoder-decoder 的结构换成了 multi-headed self-attention。
- 纯注意力的模型其他任务的应用。
📌引言
2017年常用方法是 RNN, LSTM, GRU。语言模型、编码器-解码器架构。
RNN (Recurrent neural networks)
RNN 特点:从左往右一步一步计算,对第 t 个状态 h t h_t ht ,由 h t − 1 h_{t-1} ht−1(历史信息)和当前词 t t t 计算。
- 难以并行。e.g. 100 个词要算 100 步
- 过早的历史信息可能被丢掉。时序信息是一步一步往后传递的,e.g. 时序长的时候
- 每一个计算步都需要存储,内存开销大。
本文 Transformer 网络不再使用循环结构、纯 attention、并行度高、较短时间达到很好的效果(8 P100 GPU 12 hours)。
⏱️相关工作
CNN(局部像素–>全部像素;多通道 --> multi-head)
CNN 替换 RNN 来减少时序的计算,但 CNN 对较长的序列难以建模。Transformer 的 attention mechanism 每一次看到所有的像素,一层能够看到整个序列。
多个输出通道,每个通道可以识别不同的模式。Transformer 的 multi-head self-attention 模拟 CNNs 多通道输出的效果。
Transformer 仅依赖 self-attention 计算输入输出的表征,没有使用 sequence-aligned RNNs or convolution.
⭐模型
Overview
encoder 将 ( x 1 , x 2 , . . . , x n ) (x1, x2, ... , xn) (x1,x2,...,xn)(原始输入) 映射成 ( z 1 , z 2 , . . . , z n ) (z1, z2, ..., zn) (z1,z2,...,zn)(机器学习可以理解的向量)i.e., 一个句子有 n 个词,xt 是第 t 个词,zt 是第 t 个词的向量表示。
decoder 拿到 encoder 的输出,会生成一个长为 m 的序列 ( y 1 , y 2 , . . . , y m ) (y1, y2, ... , ym) (y1,y2,...,ym),n 和 m 可以一样长、可以不一样长。decoder 在解码的时候,只能一个一个的生成。
自回归 auto-regressive:过去时刻的输出会作为你当前时刻的输入。
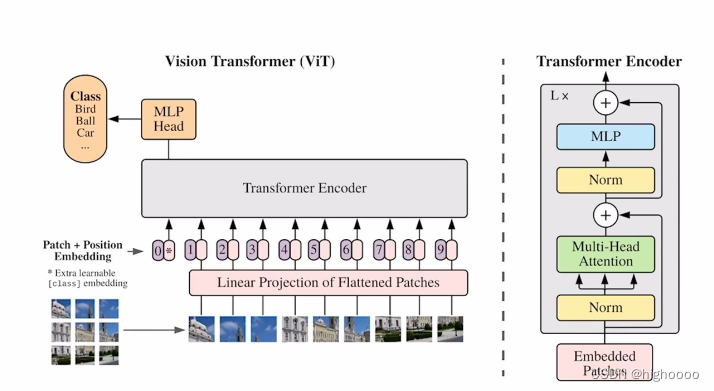
Transformer 使用堆叠的 stacked self-attention and point-wise, fully-connected layers,展示在图1。
![![[The Transformer - model architecture..png]]](https://img-blog.csdnimg.cn/direct/81f799658d7b466e876dab969da6fe08.png)
框架图左边为 encoder,右边为 decoder。
Outputs: decoder 在做预测的时候是没有输入的。Shifted right 指的是 decoder 在之前时刻的一些输出,作为此时的输入。一个一个往右移。
Inputs ---- Input Embedding
输入经过一个 Embedding 层, i.e., 一个词进来之后表示成一个向量。得到的向量值和 Positional Encoding (3.5)相加。
核心架构
N 个 Transformer 的 block 叠在一起。
- Multi-Head attention
- Add & Norm: 残差连接 + Layernorm
- Feed Forward: 前馈神经网络 MLP
- decoder 多了一个 Masked Multi-Head attention
- decoder 的输出进入一个 Linear 层,做一个 softmax,得到输出。Linear + softmax: 一个标准的神经网络的做法
总结:Transformer 是一个比较标准的 encoder - decoder 架构。区别:encoder、decoder 内部结构不同,encoder 的输出如何作为 decoder 的输入有一些不一样。
3.1 Encoder and Decoder Stacks
Encoder 结构:重复 6 个图中左侧的 layer
每个 layer 有 2 个 sub-layers:
- 第一个 sub-layer 是
multi-head self-attention - 第二个 sub-layer 是
simple, position-wise fully connected feed-forward network, 简称 MLP
每个 sub-layer 的输出做残差连接和 LayerNorm
公式:LayerNorm ( x + Sublayer (x) )
residual connections 需要输入输出维度一致,不一致需要做投影。简单起见,固定每一层的输出维度为 512。简单设计:只需调 2 个参数:每层维度有多大和 N 多少层,影响后续一系列网络的设计。
BatchNorm 和 LayerNorm 的区别
LayerNorm 为什么用的多?因为时序数据中样本长度可能不一样。LayerNorm 每个样本自己算均值和方差,不需要存全局的均值和方差。LayerNorm 更稳定,不管样本长还是短,均值和方差是在每个样本内计算。
BatchNorm:n 本书,每本书的第一页拿出来,根据 n 本书的第一页的字数均值做 Norm
LayerNorm:针对某一本书,这本书的每一页拿出来,根据次数每页的字数均值,自己做 Norm
Decoder 架构
decoder 和 encoder 很像,6 个相同 layer 的堆叠、每个 sub-layer 的 residual connections、layer normalization。每个 layer 里有 2个 encoder 中的 sub-layers, decoder 有第 3 个 sub-layer,对 encoder 的输出做 multi-head attention。
做预测时,decoder 不能看到之后时刻的输出。attention mechanism 每一次能看完完整的输入,要避免这个情况的发生。
在 decoder 训练的时候,在预测第 t 个时刻的输出的时候,decoder 不应该看到 t 时刻以后的那些输入。它的做法是通过一个带掩码 masked 的注意力机制。–> 保证训练和预测时行为一致。
3.2 Attention
注意力函数是一个将一个 query 和一些 key - value 对映射成一个输出的函数,其中所有的 query、key、value 和 output 都是一些向量。
output 是 value 的一个加权和 --> 输出的维度 == value 的维度。
output 中 value 的权重 = 查询 query 和对应的 key 的相似度
虽然 key-value 并没有变,但是随着 query 的改变,因为权重的分配不一样,导致输出会有不一样,这就是注意力机制。
3.2.1 Scaled Dot-Product Attention
query 和 key 的长度是等长的,都等于 dk。value 的维度是 dv,输出也是 dv。
注意力的具体计算是:对每一个 query 和 key 做内积,然后把它作为相似度。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
把 softmax 得到的权重值与 value 矩阵 V 相乘得到 attention 输出。
![![[Scaled Dot-Product Attention.png]]](https://img-blog.csdnimg.cn/direct/24241342259149568b13284b1c789ac5.png)
Scaled Dot-Product Attention 和别的注意力机制的区别:
2 种常见的注意力机制:加性的注意力机制(它可以处理你的 query 和 key 不等长的情况),点积 dot-product 的注意力机制 (本文采用 scaled,➗ sqrt(dk) ),所以你可以看到它的名字它叫做 scale 的。选用 dot-product 原因:两种注意力机制其实都差不多,点乘实现简单、高效,两次矩阵乘法计算。
scale dot-product 原因 ➗ sqrt (dk) :防止 softmax 函数的梯度消失。
当你的值比较大的时候,相对的差距会变大,导致最大值 softmax 会更加靠近于 1,剩下那些值就会更加靠近于 0。值就会更加向两端靠拢,算梯度的时候,梯度比较小。
在 trasformer 里面一般用的 dk 比较大 (本文 512),所以➗ sqrt (dk) 是一个不错的选择。
怎么做 mask ?
避免在 t 时刻,看到 t 时刻以后的输入。
在计算权重的时候,t 时刻只用了 v 1, …, vt-1 的结果,不要用到 t 时刻以后的内容。
把 t 时刻以后 Qt 和 Kt 的值换成一个很大的负数,如 1 ^ (-10),进入 softmax 后,权重为 0。 --> 和 V 矩阵做矩阵乘法时,没看到 t 时刻以后的内容,只看 t 时刻之前的 key - value pair。理解:mask是个 0 1矩阵,和attention(scale QK)size一样,t 时刻以后 mask 为 0。
3.3.2 Multi-head attention
进入一个线形层,线形层把 value、key、query 投影到比较低的维度。然后再做一个 scaled dot product 。
执行 h 次会得到 h 个输出,再把 h 个 输出向量全部合并 concat 在一起,最后做一次线性的投影 Linear,会回到我们的 multi-head attention。
![![[Multi-Head Attention.png]]](https://img-blog.csdnimg.cn/direct/18aa08a6009a4c8c8ebcdb8f5b063bc2.png)
为什么要做多头注意力机制呢?一个 dot product 的注意力里面,没有什么可以学的参数。具体函数就是内积,为了识别不一样的模式,希望有不一样的计算相似度的办法。
本文的 dot-product attention,先投影到低维,投影的 w 是可以学习的。
本文采用 h h h = 8 个 heads。因为有残差连接的存在使得输入和输出的维度至少是一样的。
投影维度 dv = dmodel / h = 512 / 8 = 64,每个 head 得到 64 维度,concat,再投影回 dmodel。
3.2.3 Applications of attentions in our model
3 种不一样的注意力层
encoder 的注意力层:
i.e., 句子长度是 n,encoder 的输入是一个 n 个长为 d 的向量。
一根线过来,它复制成了三下:同样一个东西,既 key 也作为 value 也作为 query,所以叫做自注意力机制。key、value 和 query 其实就是一个东西,就是自己本身。输入了 n 个 query,每个 query 会得到一个输出,那么会有 n 个输出。
输出是 value 加权和(权重是 query 和 key 的相似度),输出的维度 == d – > 输入维度 == 输出维度。
multi-head 和有投影的情况:学习 h 个不一样的距离空间,使得输出变化。decoder 的 masked multi-head attention
和编码器一样
masked 体现在,看不到 t 时刻以后的输入decoder 的 multi-head attention
不再是 self-attention。key - value 来自 encoder 的输出
query 是来自 decoder 里 masked multi-head attention 的输出。
第 3 个 attention 层,根据 query 去有效的提取 encoder 层输出
attention:query 注意到当前的 query 感兴趣的东西,对当前的 query 的不感兴趣的内容,可以忽略掉。 --> attention 作用:在 encoder 和 decoder 之间传递信息
3.3 Position-wise Feed-Forward Networks
作用在最后一个维度的 MLP
Point-wise: 把一个 MLP 对每一个词 (position)作用一次,对每个词作用的是同样的 MLP
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=\max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
单隐藏层的 MLP,中间 W1 扩维到4倍 2048,最后 W2 投影回到 512 维度大小,便于残差连接。
pytorch 实现:2个线性层。pytorch 在输入是3d 的时候,默认在最后一个维度做计算。
RNN 跟 transformer
RNN 跟 transformer 异:如何传递序列的信息
RNN 是把上一个时刻的信息输出传入下一个时候做输入。Transformer 通过一个 attention 层,去全局的拿到整个序列里面信息,再用 MLP 做语义的转换。RNN 跟 transformer 同:语义空间的转换 + 关注点
用一个线性层 or 一个 MLP 来做语义空间的转换。
关注点:怎么有效的去使用序列的信息。
3.4 Embeddings and Softmax
embedding:将输入的一个词、词语 token 映射成 为一个长为 d 的向量。学习到的长为 d 的向量 来表示整个词、词语 token。
权重 * d m o d e l = 512 \sqrt{d_{model} = 512} dmodel=512,学 embedding 的时候,会把每一个向量的 L2 Norm 学的比较小。
3.5 Positional Encoding
Why? attention 不会有时序信息。
output 是 value 的 加权和(权重是 query 和 key 之间的距离,和 序列信息 无关)。
根本不看 key - value 对在序列哪些地方。一句话把顺序任意打乱之后,attention 出来,结果都是一样的。
顺序会变,但是值不会变,有问题!
How:RNN 把上一时刻的输出作为下一个时刻的输入,来传递时序信息。
How:attention 在输入里面加入时序信息 --> positional encoding
一个词在嵌入层表示成一个 512 维的向量,用另一个 512 维的向量来表示一个数字,位置信息 1 2 3 4 5 6 7 8…。
表示一个位置数字信息的值,怎么计算?
周期不一样的 sin 和 cos 函数计算 --> 任何一个值可以用一个长为 512 的向量来表示。
这个长为 512 、记录了时序信息的一个 positional encoding,+ 嵌入层相加 --> 完成把时序信息加进数据。
详细解释:输入进来进入 embedding 层之后,那么对每个词都会拿到那个向量长为 512 的一个向量。positional encodding (这个词在句子中的位置),返回一个长为 512 的向量,表示这个位置,然后把 embeding 和 positional encodding 加起来就行了。
positional encodding 是 cos 和 sin 的一个函数,在 [-1, +1] 之间抖动的。所以 input embedding * d \sqrt{d} d ,使得乘积后的每个数字也是在差不多的 [-1, +1] 数值区间。相加完成 --> 在输入里面添加时序信息。
完成与 positional encoding 相加之后的部分是顺序不变的。不管怎么打乱输入序列的顺序,进入 layer 之后,输出那些值是不变的,最多是顺序发生了相应的变化。所以就直接把顺序信息直接加在数据值里。
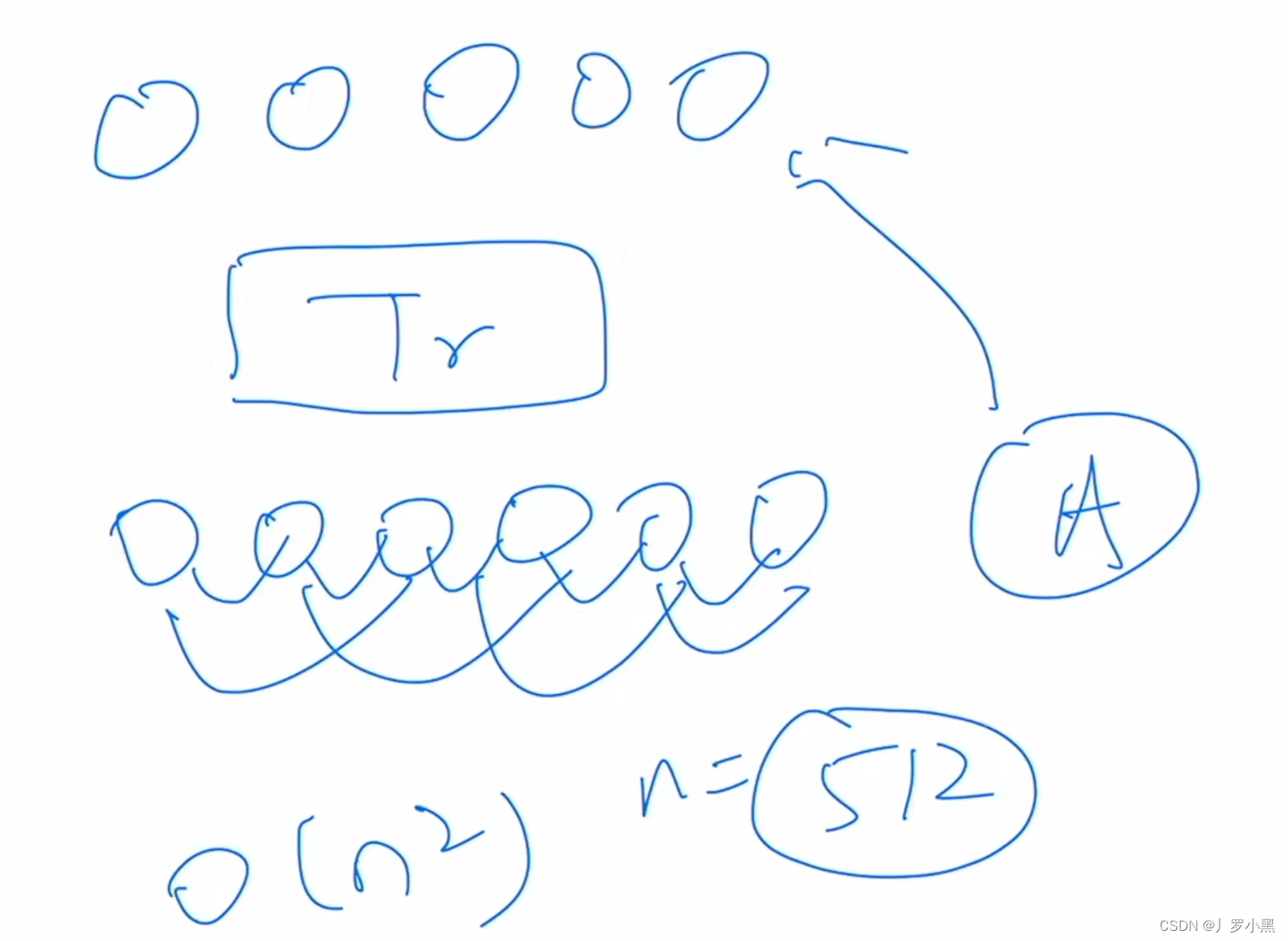
Why Self-attention
![![[Pasted image 20240229174540.png]]](https://img-blog.csdnimg.cn/direct/f4c2cdd299c44475a40513eeae76b786.png)
评价
Transformer 模型出圈 --> 多模态:像 CNN 对 CV 的作用,不仅仅应用在 NLP,在 CV、Video 上也有很好的应用。
对 Transformer 中 attention 的理解:attention只是起到 把整个序列的信息聚合起来 的作用,后面的 MLP 和 残差连接 是缺一不可的。去掉 MLP 和 残差连接,只有 attention,也什么都训练不出来。

![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]CT3D——<span style='color:red;'>逐</span>通道<span style='color:red;'>transformer</span>改进3D目标检测](https://img-blog.csdnimg.cn/9395d0a654f74185b4c2a32b01b7f0c1.png)
![[nlp入门<span style='color:red;'>论文</span><span style='color:red;'>精读</span>] | <span style='color:red;'>Transformer</span>](https://img-blog.csdnimg.cn/direct/904fe7047f8c4faebc1d4f329695681e.png)