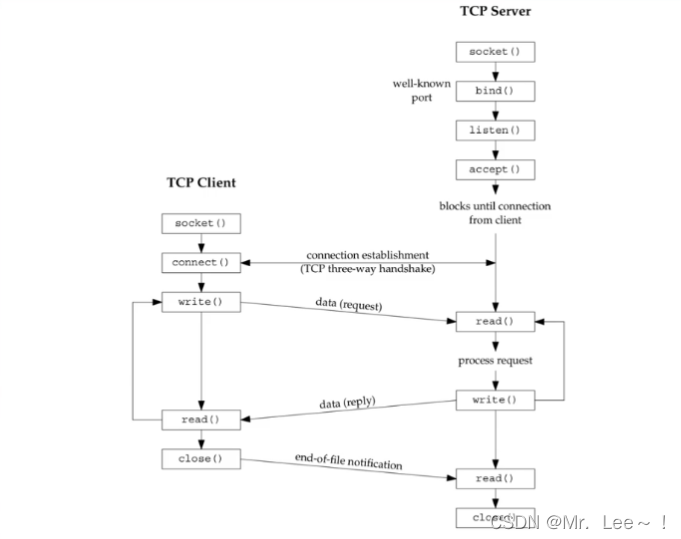
OpenMMLab多GPU训练
1、单机单GPU训练
python tools/train.py ${CONFIG_FILE}
举例:
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
如需指定工作目录,后接参数:--work_dir${WORK_DIR}
2、单机多GPU训练
使用tools文件夹下的dist_train.sh脚本来实现
#!/usr/bin/env bash
CONFIG=$1
GPUS=$2
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--seed 0 \
--launcher pytorch ${@:3}
CONFIG=$1:这行代码将脚本的第一个参数(即$1)赋值给变量CONFIG。这个参数应该是一个配置文件的路径,用于指定训练的配置。GPUS=$2:这行代码将脚本的第二个参数(即$2)赋值给变量GPUS。这个参数用于指定使用的GPU数量。NNODES=${NNODES:-1}:这行代码将环境变量NNODES的值赋给变量NNODES,如果NNODES没有设置,则将其默认值设置为1。NNODES用于指定分布式训练的节点数量。NODE_RANK=${NODE_RANK:-0}:这行代码将环境变量NODE_RANK的值赋给变量NODE_RANK,如果NODE_RANK没有设置,则将其默认值设置为0。NODE_RANK用于指定当前节点的排名。PORT=${PORT:-29500}:这行代码将环境变量PORT的值赋给变量PORT,如果PORT没有设置,则将其默认值设置为29500。PORT用于指定主节点(master node)的通信端口。MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}:这行代码将环境变量MASTER_ADDR的值赋给变量MASTER_ADDR,如果MASTER_ADDR没有设置,则将其默认值设置为"127.0.0.1"。MASTER_ADDR用于指定主节点的地址。PYTHONPATH="$(dirname $0)/..":$PYTHONPATH:这行代码将Python模块的搜索路径(PYTHONPATH)设置为脚本所在目录的父目录加上原来的PYTHONPATH值。这样做是为了确保Python可以找到所需的模块。python -m torch.distributed.launch:这行代码使用Python的torch.distributed.launch模块来启动分布式训练。--nnodes=$NNODES:这个选项指定了分布式训练的节点数量。--node_rank=$NODE_RANK:这个选项指定了当前节点的排名。--master_addr=$MASTER_ADDR:这个选项指定了主节点的地址。--nproc_per_node=$GPUS:这个选项指定了每个节点使用的GPU数量。--master_port=$PORT:这个选项指定了主节点的通信端口。$(dirname "$0")/train.py:这部分指定了要运行的Python脚本的路径,即train.py。$(dirname "$0")表示脚本所在的目录。$CONFIG:这个部分指定了配置文件的路径,它是通过脚本的第一个参数传递进来的。--seed 0:这个选项指定了随机数生成器的种子,用于可重复的训练。--launcher pytorch:这个选项指定了使用PyTorch作为分布式训练的启动器。${@:3}:这部分将脚本的第三个及之后的所有参数传递给Python脚本。
配置很多,但是实际上常用训练命令如下所示:
./tools/dist_train.sh ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py 4
4是GPU数量
可选参数:
--validate:训练过程中,每隔k代执行一次评估(默认为1)
--work_dir ${WOR_DIR}:指定工作目录
--resume_from ${CHECKPOINT_FILE}:从先前的检查点文件恢复
3、多机多GPU训练
使用slurm集群管理:
./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [${GPUS}]
举例:16GPU,test分区,训练faster R-CNN
./tools/slurm_train.sh test Faster_r50_1x configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py /home/xxx/faster_rcnn_r50_fpn_1x 16





















![攻防世界:mfw[WriteUP]](https://img-blog.csdnimg.cn/direct/6acc906fa7fc4d61a4cfe854fd5788db.png)