1.SegmentAnything导出Onnx模型分割图片
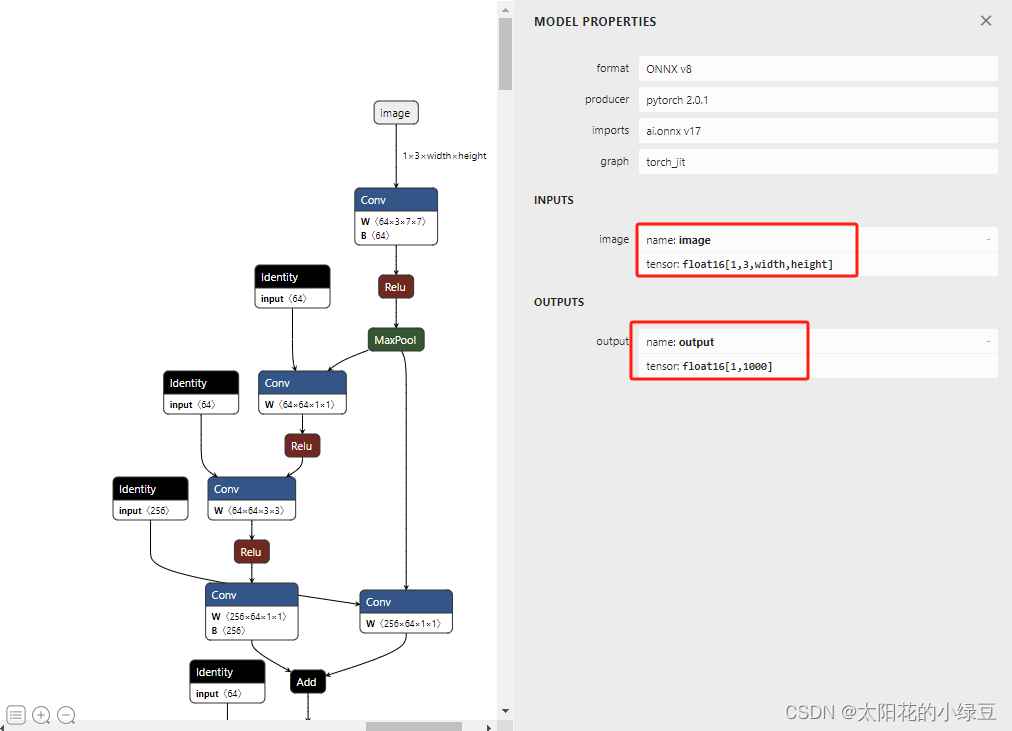
2.官方SegmentAnything导出Onnx模型,不全面。官方只提供了mask的decoder模型,还缺失image的encoder模型
3.b站视频地址 添加链接描述
4.导出模型的核心代码
#导出onnx
def ExportOnnx(self):
# Export masks decoder from SAM model to ONNX
onnx_model = SamOnnxModel(self.Model, return_single_mask=True)
embed_dim = self.Model.prompt_encoder.embed_dim
embed_size = self.Model.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),
"has_mask_input": torch.tensor([1], dtype=torch.float),
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
torch.onnx.export(
f="vit_b_decoder.onnx",
model=onnx_model,
args=tuple(dummy_inputs.values()),
input_names=list(dummy_inputs.keys()),
output_names=output_names,
dynamic_axes={
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"}
},
export_params=True,
opset_version=17,
do_constant_folding=True
)
# Export images encoder from SAM model to ONNX
torch.onnx.export(
f="vit_b_encoder.onnx",
model=self.Model.image_encoder,
args=torch.randn(1, 3, 1024, 1024),
input_names=["images"],
output_names=["embeddings"],
export_params=True)
pass