Hahoop分布式文件系统支持DataNode节点的大规模扩展,本文主要描述DataNode集群版的安装部署。
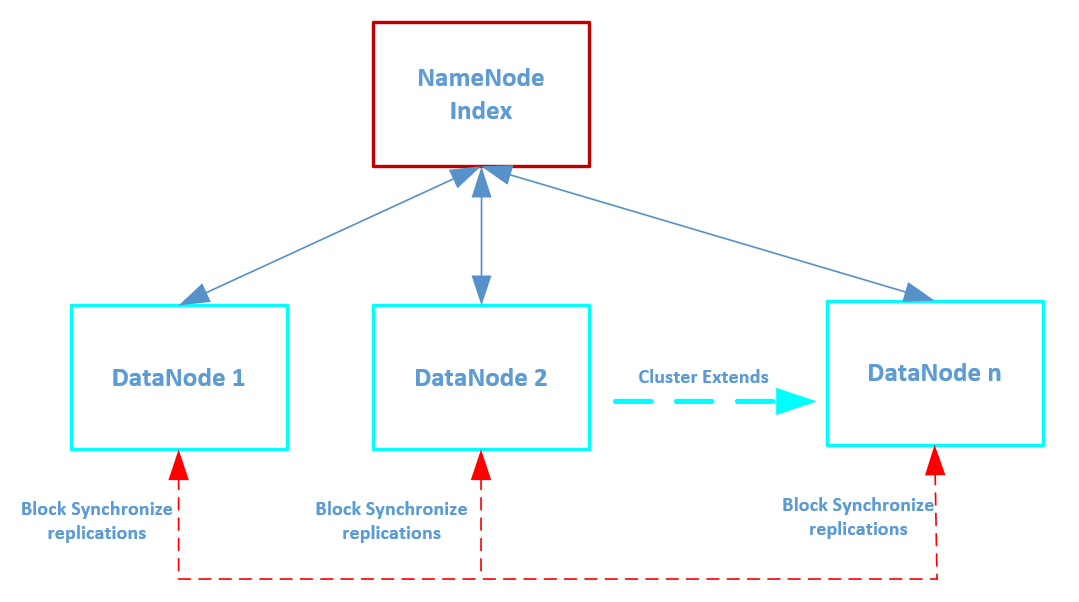
如上所示,Hadoop分布式文件系统中每个文件是以数据块的方式存储在不同的DataNode中,每个数据块都支持高可用性,当其中一个数据块对应的DataNode节点发生故障变得不可用时,Hadoop分布式文件系统则根据备份复制规则在其他可用的DataNode节点中重新同步复制一份新的数据块,以保证每个数据块的副本数符合高可用性的规则
NameNode1 |
192.168.0.136 |
DataNode 1 |
192.168.0.137 |
DataNode 2 |
192.168.0.138 |
如上所示,Hadoop分布式文件系统的NameNode以及DataNode对应的IP地址

如上所示,在Hadoop分布式文件系统集群的所有节点中,设置主机名称与IP地址之间的对应关系
![]()
![]()


如上所示,设置NameNode索引节点可免密登录DataNode数据存储节点,NameNode索引节点可以远程免密登录DataNode节点执行操作命令

如上所示,在Hadoop分布式文件系统的NameNode索引节点中,设置集群包括的DataNode数据存储节点
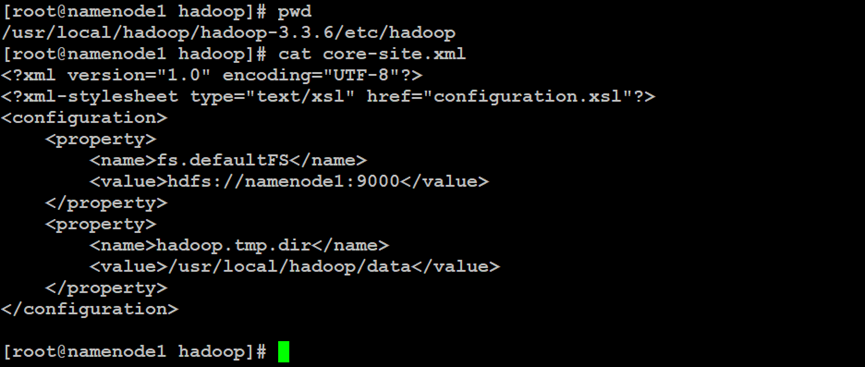
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,设置集群核心侧的属性
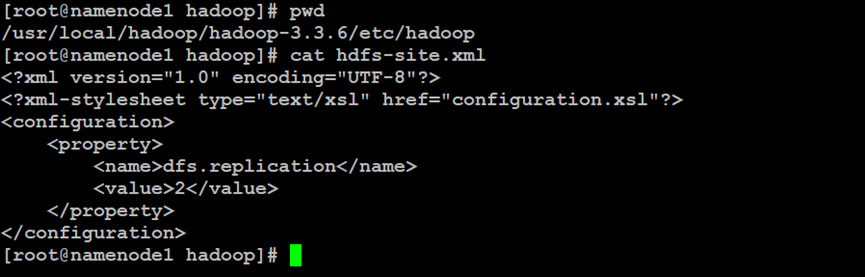
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,设置分布式文件系统侧的属性
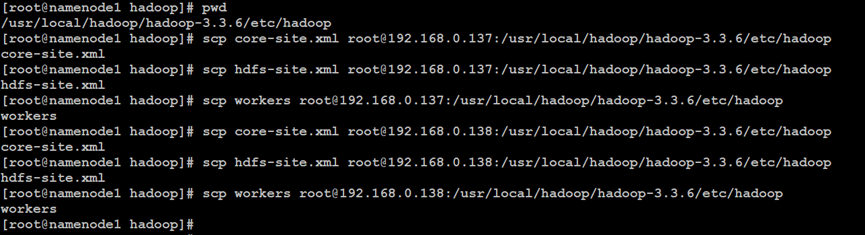
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,同步属性配置文件到其他的DataNode数据存储节点
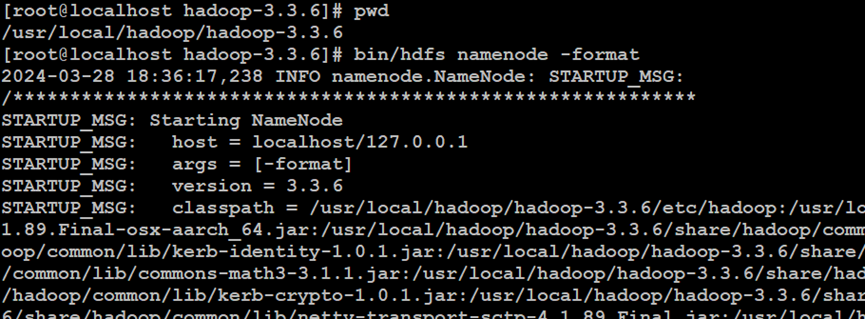
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,格式化文件系统
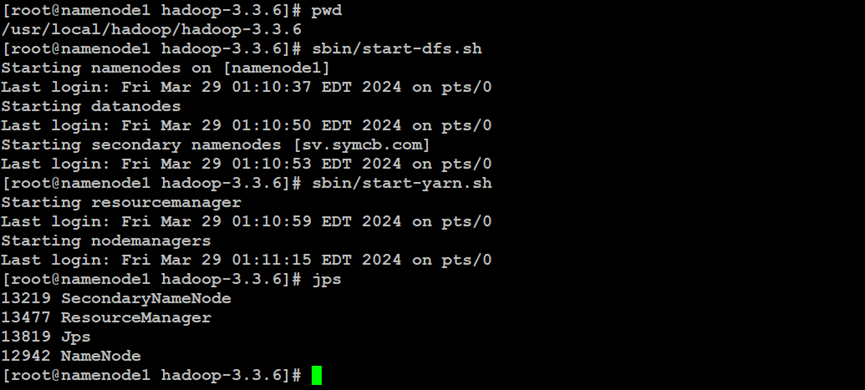
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,启动集群

如上所示,在Hadoop分布式文件系统的DataNode数据存储节点中,显示集群启动信息
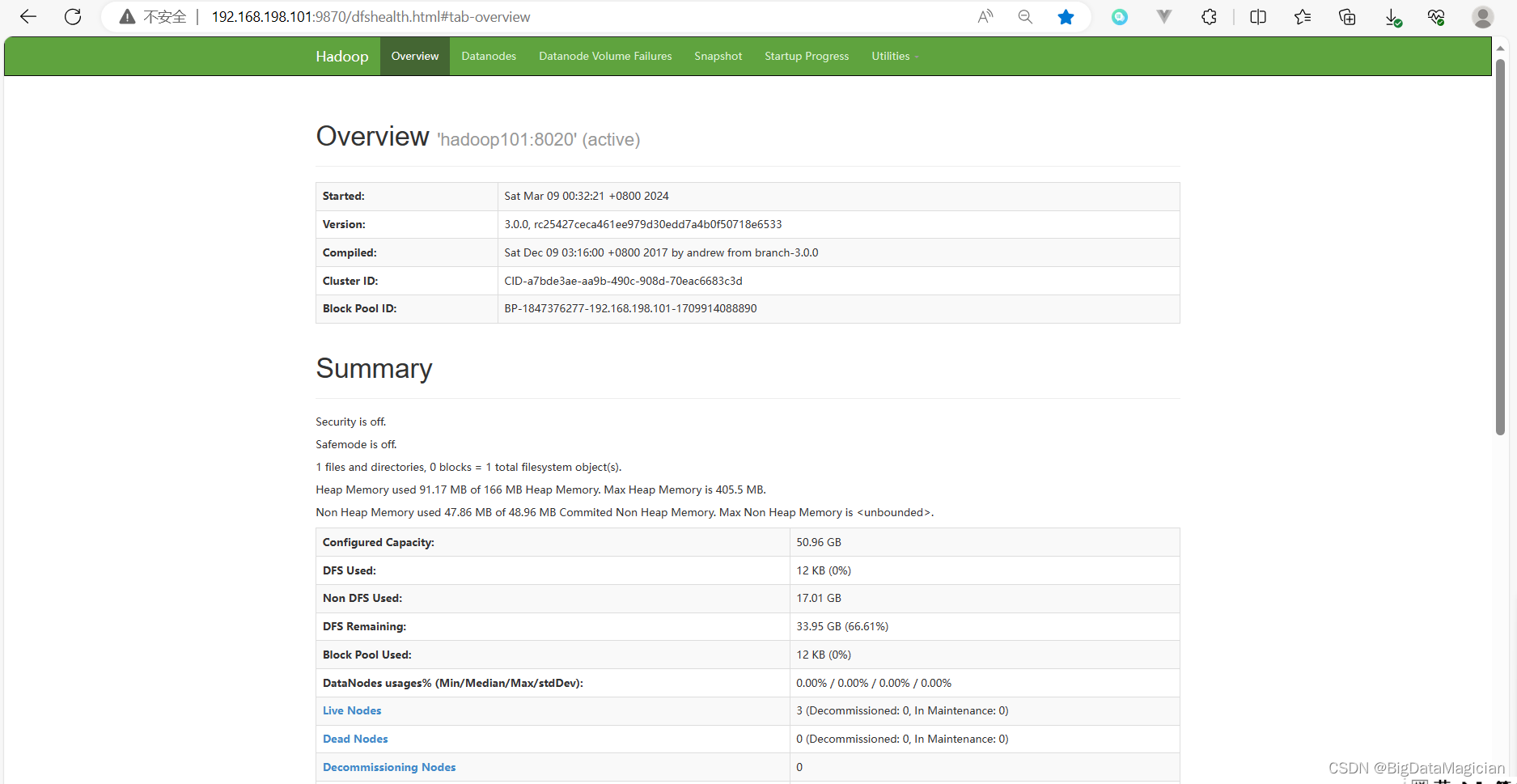
http://192.168.0.136:9870/ |
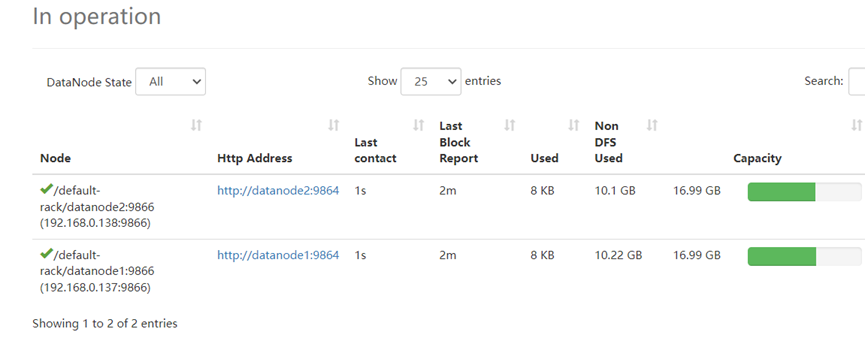
如上所示,在浏览器中访问Hadoop分布式文件系统的web统计信息页面,显示DataNode数据存储节点的使用情况

































![[leetcode]28. 找出字符串中第一个匹配项的下标](https://img-blog.csdnimg.cn/img_convert/dd4216e108db3b8c7812764bc37eac73.png)