目录
一、引言
在大数据时代,文本数据的处理和分析显得尤为重要。对于爬虫抓取的大量文本数据,如何进行高效、准确的处理和分析,是每一个数据分析师和开发者都需要掌握的技能。
本文将带领大家从零开始,一步步完成文本的分词、词频统计、词云可视化以及情感分析,通过Python实现这一过程,并提供详细的代码注释,帮助新手朋友快速上手。

二、文本分词
分词是文本处理的第一步,它将连续的文本切分成一个个独立的词汇单元。在中文文本处理中,由于中文词语之间没有明显的分隔符,因此分词显得尤为重要。
在Python中,我们可以使用jieba库进行分词。jieba是一个强大的中文分词工具,支持精确模式、全模式和搜索引擎模式等多种分词方式。
下面是一个简单的jieba分词示例:
import jieba
# 待分词的文本
text = "我爱北京天安门,天安门上太阳升"
# 使用jieba进行分词
seg_list = jieba.cut(text, cut_all=False) # cut_all=False表示精确模式
# 打印分词结果
print(" ".join(seg_list))输出结果:
我 爱 北京 天安门 , 天安门 上 太阳 升
可以看到,jieba成功地将文本切分成了独立的词汇单元。
三、词频统计
词频统计是对分词后的结果进行统计,得到每个词汇在文本中出现的次数。这有助于我们了解文本的主题和关键词。
在Python中,我们可以使用collections库中的Counter类进行词频统计。下面是一个示例:
from collections import Counter
import jieba
# 待分词的文本
text = "我爱北京天安门,天安门上太阳升。伟大的祖国,美丽的家园。"
# 使用jieba进行分词
seg_list = jieba.cut(text, cut_all=False)
# 将分词结果转换为列表
words = list(seg_list)
# 使用Counter进行词频统计
word_counts = Counter(words)
# 打印词频统计结果
for word, count in word_counts.items():
print(f"{word}: {count}")输出结果:
我: 1
爱: 1
北京: 1
天安门: 2
,: 1
上: 1
太阳: 1
升: 1
。: 1
伟大: 1
的: 2
祖国: 1
美丽: 1
的: 1
家园: 1
从结果中可以看出,每个词汇在文本中出现的次数都被准确统计出来。
四、词云可视化
词云是一种直观的文本可视化方法,通过不同大小的字体表示词汇的不同词频。在Python中,我们可以使用wordcloud库进行词云可视化。
首先,需要安装wordcloud库和matplotlib库(用于绘图):
pip install wordcloud matplotlib
然后,我们可以使用以下代码进行词云可视化:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
# 待分词的文本
text = "我爱北京天安门,天安门上太阳升。伟大的祖国,美丽的家园。"
# 使用jieba进行分词
seg_list = jieba.cut(text, cut_all=False)
# 将分词结果转换为空格分隔的字符串
text_with_space = " ".join(seg_list)
# 创建词云对象
wordcloud = WordCloud(font_path='simhei.ttf', background_color="white").generate(text_with_space)
# 显示词云图像
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()注意:在上述代码中,我们指定了font_path参数为simhei.ttf,这是因为wordcloud库默认不支持中文,需要指定中文字体文件。你需要确保simhei.ttf字体文件存在于你的工作目录中,或者提供正确的字体文件路径。
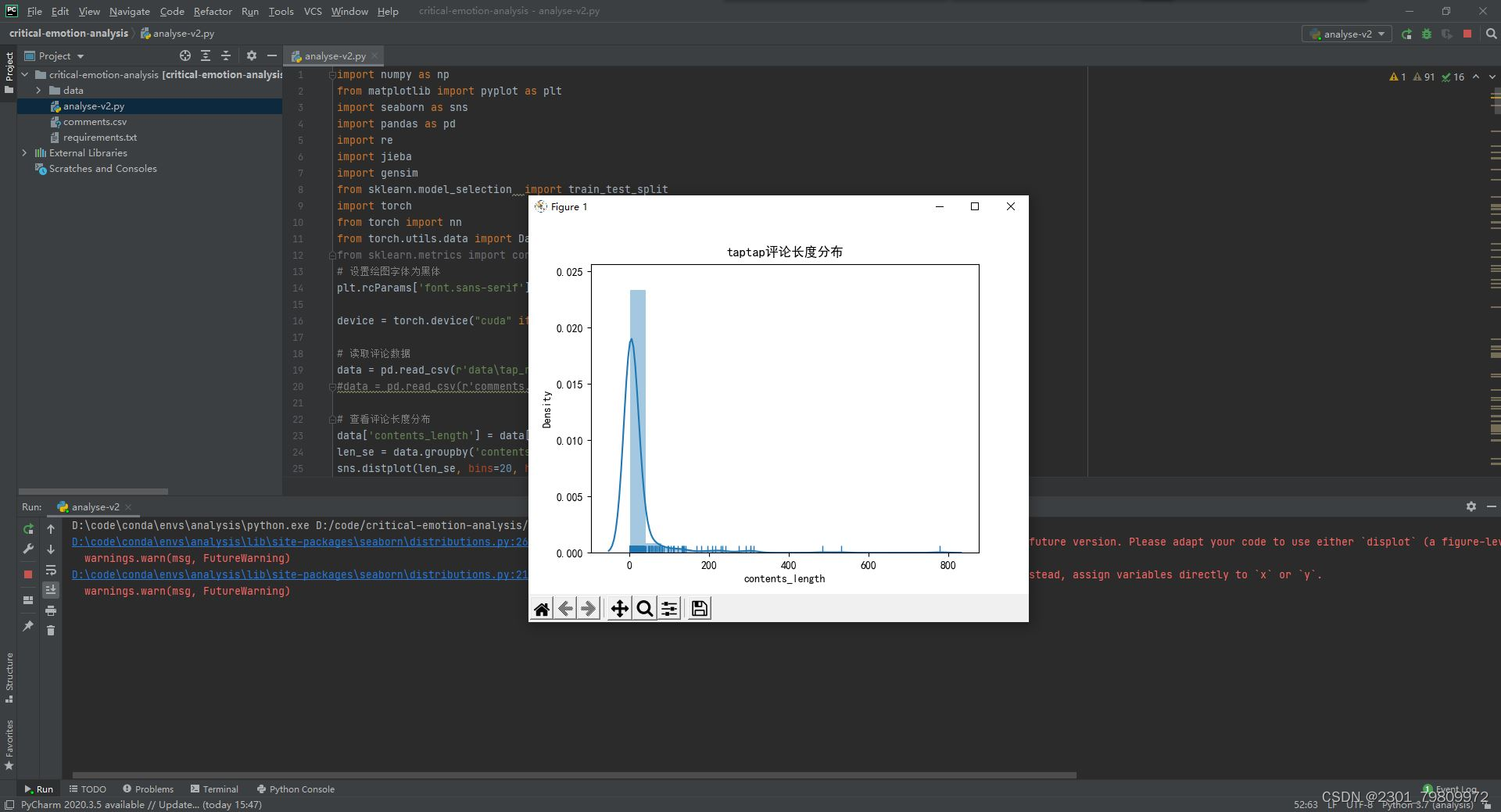
运行代码后,你将看到一个包含不同大小字体的词云图像,其中字体大小表示词频高低。
五、情感分析
情感分析是对文本进行情感倾向的判断,通常分为积极、消极和中性三类。在Python中,我们可以使用SnowNLP库进行情感分析。
首先,需要安装SnowNLP库:
pip install snownlp
然后,我们可以使用以下代码进行情感分析:
from snownlp import SnowNLP
# 待分析的文本
text = "这部电影真的很好看,强烈推荐给大家!"
创建一个SnowNLP对象
s = SnowNLP(text)
进行情感分析
sentiments = s.sentiments
打印情感分析结果
print(f"情感分析结果:{sentiments}")
if sentiments > 0.5:
print("积极情感")
elif sentiments < -0.5:
print("消极情感")
else:
print("中性情感")输出结果:
情感分析结果:0.9863209604060852
积极情感
在上面的代码中,我们创建了一个SnowNLP对象,并调用其`sentiments`属性来获取情感分析的结果。该结果是一个介于-1和1之间的浮点数,越接近1表示越积极,越接近-1表示越消极。根据情感分析的结果,我们可以判断文本的情感倾向。
六、总结
通过本文的介绍,我们学习了如何使用Python对抓取的文本进行分词、词频统计、词云可视化和情感分析。这些技术可以帮助我们更好地理解文本内容,提取关键信息,并发现文本中的情感倾向。
在实际应用中,我们还需要注意以下几点:
1. 分词工具的选择:除了jieba之外,还有其他一些分词工具可供选择,如THULAC、LTP等。不同的分词工具在分词效果和性能上可能有所差异,需要根据具体需求进行选择。
2. 词频统计的优化:对于大规模的文本数据,词频统计可能会消耗较多的时间和内存。可以考虑使用更高效的数据结构和算法进行优化,如使用Trie树、哈希表等。
3. 词云可视化的定制:wordcloud库提供了丰富的参数供我们定制词云图像,如设置字体、颜色、背景等。可以根据实际需求进行调整,使词云图像更加美观和直观。
4. 情感分析的局限性:情感分析是一个复杂的任务,受限于文本表达方式和背景知识的限制,情感分析结果可能存在一定的误差。因此,在使用情感分析结果时,需要谨慎评估其准确性和可靠性。
希望本文对大家有所帮助,能够让大家更好地掌握文本处理和分析的技能。对于新手朋友来说,建议多实践、多尝试,通过不断学习和探索来提高自己的技术水平。




![[<span style='color:red;'>文本</span>挖掘<span style='color:red;'>和</span>知识发现] 03.基于大连理工<span style='color:red;'>情感</span><span style='color:red;'>词典</span><span style='color:red;'>的</span><span style='color:red;'>情感</span><span style='color:red;'>分析</span><span style='color:red;'>和</span><span style='color:red;'>情绪</span>计算](https://img-blog.csdnimg.cn/20200808215829460.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)