一.元素定位
因为使用selenium进行自动化测试,元素定位是必不可少的,所以这篇文章用于自动化测试中的selenium中的元素定位法。
1.根据id属性进行定位(id是唯一的)
id定位要求比较高,要求这个元素的id必须是固定且唯一的。众所周知的百度的输入框的id是唯一的,但是在日常我们自动化测试,尽量不要用id进行定位元素。

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 1.获取浏览器(创建浏览器驱动对象)
driver = webdriver.Chrome()
# 2.输入url,打开web页面
driver.get("http://hmshop-test.itheima.net/home/User/login.html")
# 3.查找操作元素
# 用户名
driver.find_element(By.ID, "username").send_keys("111111")
# 密码
driver.find_element(By.ID, "password").send_keys("000000000")
time.sleep(3)
# 4.关闭浏览器驱动对象
driver.quit()
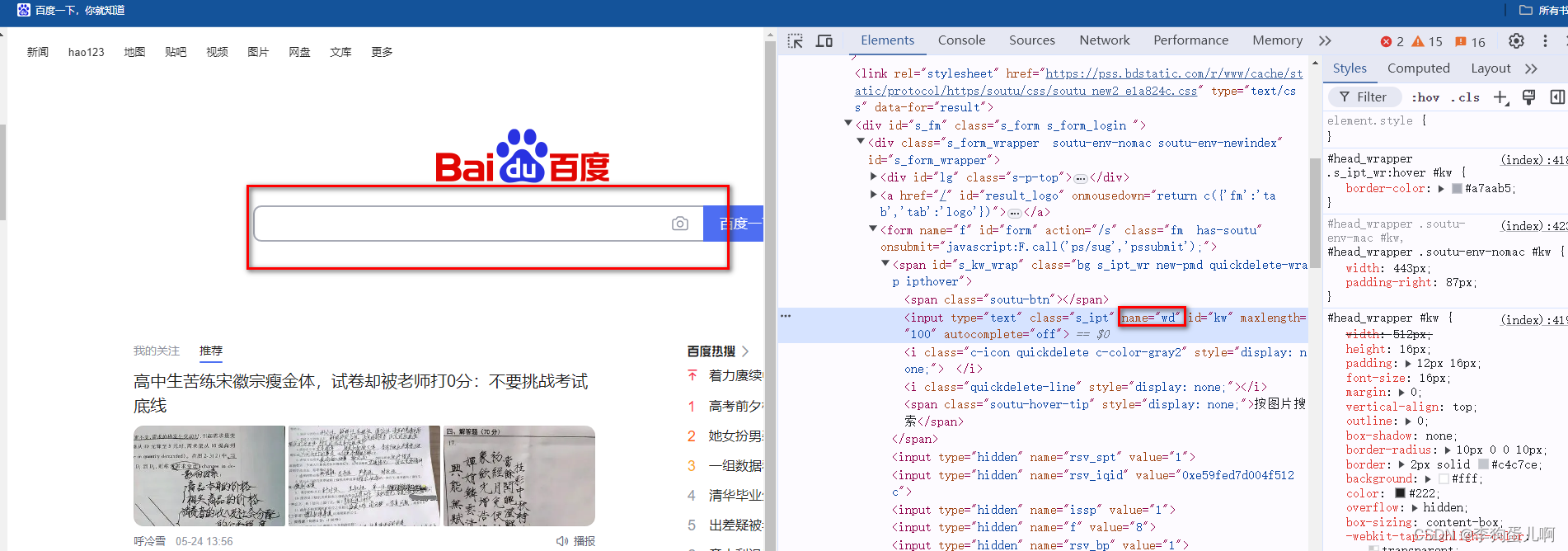
2.name属性进行定位
还是用百度输入框举例,用name的话大概率会出现很多重复的名称,(不是唯一的,默认返回的是第一个元素)这个方法也不建议使用。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过name定位元素的方式
# name方式:1、元素中必须要有name的属性 2、name的属性在页面中如果是唯一的,那么可以准确的定位到元素(不是唯一的,默认返回的是第一个元素)
driver.find_element(By.NAME, "wd").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()3.tag name(标签名) 定位和class name(标签中的class属性)定位
根据Class定位属性,主要是用来元素进行分组,并对这一级元素设置相同的样式。所以class属性在当前html页面当中,也是不能唯一定位到一个元素的。
class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素。
tag_name是通过标签名称来定位的,如<input>标签。
tag_name定位元素:标签名是会重复,默认返回的是第一个符合的元素。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.taobao.com/")
# 定位到百度搜索框通过tag_name定位元素的方式
# tag_name定位元素:1、标签名是会重复,默认返回的是第一个符合的元素
driver.find_element(By.TAG_NAME, "input").send_keys("三体")
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过class定位元素的方式
# class_name定位元素:1、在元素中需要有class的属性;2、class的属性值不是唯一的,那么不能唯一的定位到指定的元素
driver.find_element(By.CLASS_NAME, "s_ipt").send_keys("python")
# 通过id定位到百度一下按钮,点击一下
driver.find_element(By.ID, "su").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()4、link_text元素定位
link_text 只能使用精准的匹配(a标签的全部文本内容)。
link_text定位:必须根据链接上完整的文本内容去进行定位。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度搜索框通过link_text定位元素的方式
# link_text定位元素:1、必须根据链接上完整的文本内容去进行定位。
driver.find_element(By.LINK_TEXT, "新闻").click()
# 延时3秒
sleep(3)
# 退出浏览器
driver.quit()6、partial_link_text元素定位
partial_link_text可以使用精准或模糊匹配,如果使用模糊匹配最好能使用可以唯一的关键字;如果有多个值,默认返回第一个值。
partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个值。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度输入框,搜索热点新闻
driver.find_element(By.ID, "kw").send_keys("热点新闻")
# 定位到百度一下按钮,并且点击
driver.find_element(By.ID, "su").click()
# 停留3秒,加载页面
sleep(3)
# 从返回的结果页面,通过模糊匹配定位到包含了“腾讯网”的超连接
# partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个
# .click()点击的操作
driver.find_element(By.PARTIAL_LINK_TEXT, "腾讯网").click()
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()5、partial_link_text元素定位
partial_link_text可以使用精准或模糊匹配,如果使用模糊匹配最好能使用可以唯一的关键字;如果有多个值,默认返回第一个值。
partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个值。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开百度页面
driver.get("https://www.baidu.com/")
# 定位到百度输入框,搜索热点新闻
driver.find_element(By.ID, "kw").send_keys("热点新闻")
# 定位到百度一下按钮,并且点击
driver.find_element(By.ID, "su").click()
# 停留3秒,加载页面
sleep(3)
# 从返回的结果页面,通过模糊匹配定位到包含了“腾讯网”的超连接
# partial_link_text定位:定位的链接文本内容在整个页面当中唯一的出现一次,那么可以准确定位到元素,否则默认返回第一个
# .click()点击的操作
driver.find_element(By.PARTIAL_LINK_TEXT, "腾讯网").click()
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()6、xpath元素定位(最重要的来了,也是日常使用比较多的定位方式)
6-1、xpath简介
xpath即是XML Path的简称,它是一门在XML文档中查找元素信息的语言。
6-2、使用xpath目的
在前面写的定位方式不能实现的时候使用。
id、name、class_name定位前提是要有这个属性,否则不能定位。
tag_name方式如果有很多相同的标签名,定位不方便。
link的定位方式只是针对超链接的。
6-3、xpath语法
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
表达式 |
描述 |
nodename |
选取此节点的所有子节点。 |
/ |
从根节点选取。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选取当前节点。 |
.. |
选取当前节点的父节点。 |
@ |
选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 |
结果 |
bookstore |
选取 bookstore 元素的所有子节点。 |
/bookstore |
选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
bookstore/book |
选取属于 bookstore 的子元素的所有 book 元素。 |
//book |
选取所有 book 子元素,而不管它们在文档中的位置。 |
bookstore//book |
选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
//@lang |
选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 |
结果 |
/bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
/bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
/bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
/bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
//title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
//title[@lang='eng'] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
/bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
/bookstore/book[price>35.00]//title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 |
描述 |
* |
匹配任何元素节点。 |
@* |
匹配任何属性节点。 |
node() |
匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 |
结果 |
/bookstore/* |
选取 bookstore 元素的所有子元素。 |
//* |
选取文档中的所有元素。 |
//title[@*] |
选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 |
结果 |
//book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
//title | //price |
选取文档中的所有 title 和 price 元素。 |
/bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
6.4、xpath定位方式一(绝对路径)
语法:以单斜杠开头逐级开始编写,不能跳级。如:("html/body/div/div/form/input")。
- 以/html开头, 元素的层级之间通过 / 分隔
- 针对同一层级的相同元素可以使用下标,下标是从1开始
- 针对要查找的元素,所有经过的层级元素都需要列出来
- 例子:/html/body/div/fieldset/form/p/input
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到姓名输入框
# xpath定位方式一:绝对路径
driver.find_element(By.XPATH, "html/body/div/form/fieldset/table/tbody/tr/td/input").send_keys("admin")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()6.5、xpath定位方式二(相对路径)
相对路径是只给出元素路径的部分信息,在 html 的任意层次中寻找符合条件的元素。(元素名不知道,可用*)语法:以双斜杠开头,双斜杠后边跟元素名称。如://input。
- 以//* 或者 //tag_name开对[tag_name是元素的标签名称
- 可以使用下标,下标是从1开始。
- 匹配的是任意层级的元素
- 例子://p[1]/input
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到多行文本输入框(简介)
# xpath定位方式二:相对路径
driver.find_element(By.XPATH, "//textarea").send_keys("这是一个简介。")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()6.6、xpath定位方式3(属性)
- 通过元素的属性及属性值进行元素定位
- 以//*或者//tag_name开头
- 表达式: //*[@attribute='value'] attribute表示的是属性名,value表示的属性值
- 例子://*[@id='userA']
6.7、xpath定位方式三(路径结合属性)
语法://input[@id='id值']。
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# 定位到密码输入框
# xpath定位方式三:路径结合属性的形式(定位到密码输入框)
driver.find_element(By.XPATH, "//input[@id='Password1']").send_keys("123456789")
# 延时3秒
sleep(5)
# 退出浏览器
driver.quit()6.8、xpath定位方式四(文本内容匹配)
语法://a[text()="新闻"],标签为a文本信息为"新闻"。
//*[text()='value']---通过元素的全部文本内容来定位元素
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式四:文本内容匹配(定位到hao123当中的京东链接)
driver.find_element(By.XPATH, "//a[text()='京东']").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()6.9、xpath定位方式五(部分文本信息包含匹配)
语法://a[contains(text(),"新")] 或者 //a[contains(text(),"闻")]
//*[contains(@attriubte, 'value')]-------
- attribute表示的是属性名
- value表示的是查找的内容
- 定位元素时,匹配attribute属性值当中包含value值的元素
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get("https://www.hao123.com/")
# 延时3秒
sleep(3)
# xpath定位方式五:部分文本内容进行匹配(定位到hao123当中的哔哩哔哩链接)
driver.find_element(By.XPATH, "//a[contains(text(), '哔哩')]").click()
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()6.10、xpath定位方式六(路径结合逻辑)
语法://标签名[@属性名='属性值' and @属性名='属性值']
- 解决多个元素的属性值重复的问题
- 以//*或者//tag_name开头
- 表达式://*[@attriubte1='value1' and @attribute2='value2']
- 例子://*[@id='userA' and @name='userA']
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式六:通过多个属性定位到姓名2输入框
driver.find_element(By.XPATH, "//input[@name='Name' and @id='t2']").send_keys("第二个姓名")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()6.11、xpath定位方式七(通过父级定位子级元素)
语法://标签名(或*)[@父级属性名='父级属性值']/input。
例子://li[8]/label[@class='recom_t']/a[@href='/topics/396544990']
//*[starts-with(@attribute, 'value')]
- attribute表示的是属性名
- value表示的是查找的内容
- 定位元素时,匹配attribute属性值是以value值开头的元素
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# xpath定位方式七:通过父级定位子级元素
driver.find_element(By.XPATH, "//td[@id='id1']/input").send_keys("通过父级定位到子级")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()6.12、xpath定位方式八(直接复制法)-不建议
通过手动定位到的标签,点击右击复制xpath元素,直接复制到代码里。如下所示。
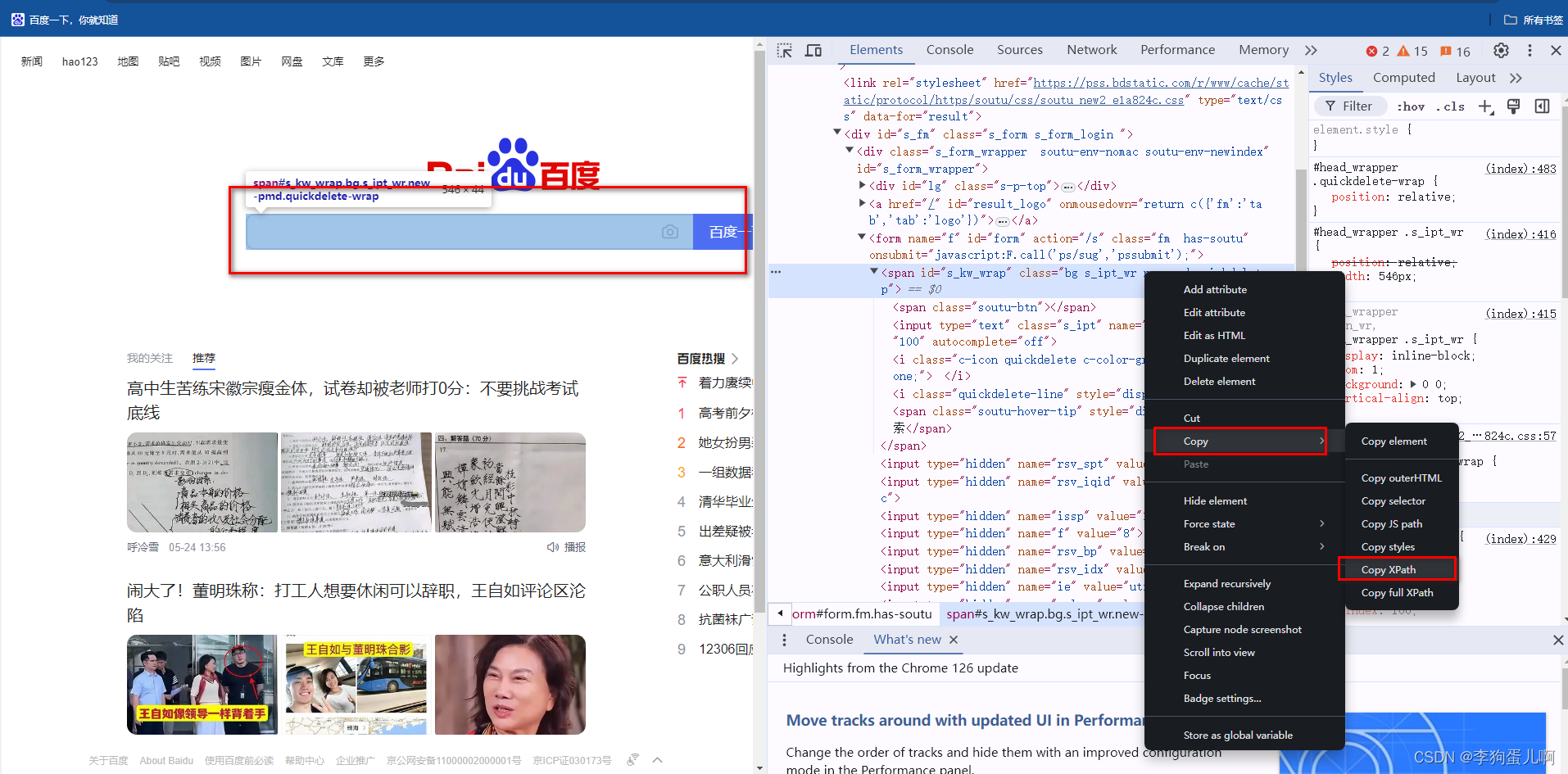
//*[@id="s_kw_wrap"]6.13、SVG标签定位

svg标签定位://div[@class="__flex_main"]//div[@class="__filter_title"]//*[name()="svg"] [@class="arco-icon arco-icon-caret-down __icon—triangle"]
7、CSS选择器定位
7-1、CSS选择器简介
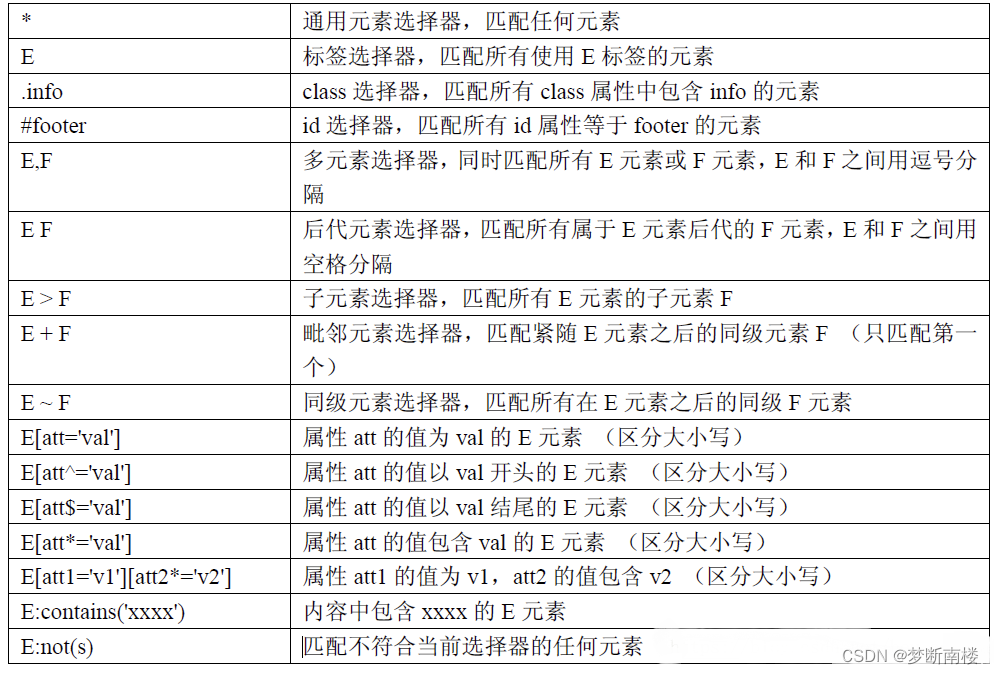
CSS是一种标记语言,在CSS标记语言中找元素使用CSS选择器,极力推荐使用CSS,CSS查找效率高,语法简单。
7-2、CSS选择器定位方式(十四种)
id选择器(语法:#id,如:#a1)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # 定位到姓名输入框 # css定位方式一:id选择器定位 driver.find_element(By.CSS_SELECTOR, "#t1").send_keys("CSS选择器") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()class选择器(语法:.class,如:.cA)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # 定位到密码输入框 # css定位方式二:class选择器定位(密码框) driver.find_element(By.CSS_SELECTOR, ".passwd").send_keys("class") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()元素选择器(语法:element,如:input)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # css定位方式三:元素选择器定位(标签名定位)(定位到简介多行文本框) driver.find_element(By.CSS_SELECTOR, "textarea").send_keys("这是元素选择器定位。") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()通用选择器(语法:*,用于匹配任何元素)
多元素选择器E,F(E,F同时匹配所有E元素或F元素,E和F之间用逗号分隔)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # css定位方式五:多元素选择器(同时定位到姓名和密码输入框) # find_elements(By.CSS_SELECTOR, "元素")返回的是一个列表类型的元素,如果想定位到具体的元素,可以通过索引去拿(索引是从0开始) driver.find_elements(By.CSS_SELECTOR, "#t1,.passwd")[1].send_keys("5201314") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()后代元素选择器E F(匹配所有属于E元素后代的F元素,E和F之间用空格分隔)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # css定位方式六:后代选择器(定位到多行文本输入框,简介) # 后代选择器,可以隔代,可以通过父与子的关系定位,还可以通过爷爷与孙子的关系定位 driver.find_element(By.CSS_SELECTOR, "tr textarea").send_keys("这是后代选择器定位。") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()子元素选择器E>F(匹配所有E元素的子元素F)
from selenium.webdriver.common.by import By from selenium import webdriver from time import sleep # 定义一个谷歌浏览器的对象 driver = webdriver.Chrome() # 打开测试页面 driver.get(r"D:\Python_code\software_test\Class6\test.html") # css定位方式七:子元素选择器(定位到多行文本输入框,简介) # 子元素选择器是必须直接子级才可以定位,隔代则定位不了 driver.find_element(By.CSS_SELECTOR, "td>textarea").send_keys("子元素选择器定位。") # 延时5秒 sleep(5) # 退出浏览器 driver.quit()毗邻元素选择器E+F(匹配紧随E元素之后的同级元素F,只匹配第一个)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class7\test02.html")
# css定位方式八:毗邻元素选择器(定位到表单test里面的input标签)
driver.find_element(By.CSS_SELECTOR, "p+input").send_keys("毗邻元素选择器")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()同级元素器E~F(E~F匹配所有在E元素之后的同级F元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class7\test02.html")
# css定位方式九:同级元素选择器(定位到表单test2里面的input标签)
driver.find_element(By.CSS_SELECTOR, "p~input").send_keys("同级元素选择器")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名='属性值'](指定标签名下的符合[]里面属性条件的元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十:标签结合属性定位元素:标签名[属性名='属性值']
driver.find_element(By.CSS_SELECTOR, "input[id='Password1']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名^='a'](属性值以a开头的标签元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十一:标签名结合属性定位元素:标签名[属性名^='a'](属性值以a开头)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name^='P']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名$='a'](属性的值以a结尾的指定标签名的元素,区分大小写)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十二:标签名结合属性定位元素:标签名[属性名$='a'](属性值以a结尾)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name$='d']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性名*='a'](属性的值包括a 的指定标签的元素)
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十三:标签名结合属性定位元素:标签名[属性名*='a'](属性值包含a)
# 案例:定位到第一个表单注册页面的密码输入框
driver.find_element(By.CSS_SELECTOR, "input[name*='w']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()
标签名[属性1='a'][属性2*='b']
from selenium.webdriver.common.by import By
from selenium import webdriver
from time import sleep
# 定义一个谷歌浏览器的对象
driver = webdriver.Chrome()
# 打开测试页面
driver.get(r"D:\Python_code\software_test\Class6\test.html")
# css定位方式十四:标签名结合多个属性定位:标签名[属性1='a'][属性2*='b']
# 案例:定位到第一个表单注册页面的姓名2输入框
driver.find_element(By.CSS_SELECTOR, "input[name='Name'][id='t2']").send_keys("123456789")
# 延时5秒
sleep(5)
# 退出浏览器
driver.quit()