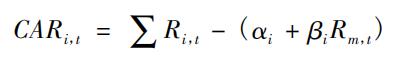华为OD – C++面经(全)
公众号:阿Q技术站
文章目录
来源:https://www.nowcoder.com/feed/main/detail/dada74012ebd4d789b63e518b44899d1
一面
1、C++结构体和类的区别,类默认的访问权限,结构体可以定义成员函数吗?
默认访问权限
结构体(struct):成员变量和成员函数默认是
public访问权限。类(class):成员变量和成员函数默认是
private访问权限。
struct MyStruct {
int x; // 默认是 public
void foo() {} // 默认是 public
};
class MyClass {
int y; // 默认是 private
void bar() {} // 默认是 private
};
语法上和使用上的区别
定义方式:虽然
struct和class可以用来定义数据成员和成员函数,但使用class更常见于表示具有行为和状态的对象,而struct更常用于表示纯粹的数据结构。继承:在继承时,
class的继承默认是private,而struct的继承默认是public。
struct Base1 {};
class Base2 {};
// 继承默认权限不同
struct Derived1 : Base1 {}; // public 继承
class Derived2 : Base2 {}; // private 继承
- 结构体是否可以定义成员函数
C++ 的 struct 可以定义成员函数。实际上,struct 和 class 除了默认访问权限不同外,语法上几乎是一样的。
struct MyStruct {
int x;
void setX(int val) {
x = val;
}
int getX() {
return x;
}
};
2、多态的意义?
多态指的是同一个接口可以有不同的实现方式。多态通过允许不同类型的对象以相同的方式进行处理,极大地提高了代码的灵活性和可扩展性。多态主要通过继承和接口实现,并且可以分为编译时多态和运行时多态。
多态的意义
提高代码重用性和可维护性: 多态允许你编写更加通用的代码。例如,可以编写一个函数来处理不同类型的对象,而不需要了解这些对象的具体类型。这样,当需要增加新的类型时,只需要新增类的实现,而不需要修改已经存在的代码。
// 基类 class Animal { public: virtual void makeSound() = 0; // 纯虚函数 }; // 派生类 class Dog : public Animal { public: void makeSound() override { cout << "Woof" << endl; } }; class Cat : public Animal { public: void makeSound() override { cout << "Meow" << endl; } }; void makeAnimalSound(Animal* animal) { animal->makeSound(); } int main() { Dog dog; Cat cat; makeAnimalSound(&dog); // 输出 Woof makeAnimalSound(&cat); // 输出 Meow }简化代码: 多态可以用统一的接口来操作不同类型的对象,简化了代码的复杂度和可读性。例如,在上面的代码中,无论是
Dog还是Cat,你都可以通过调用makeSound来发出声音,而不需要分别为每种类型写不同的处理逻辑。增强系统的扩展性: 多态使得系统更容易扩展。当需要添加新的功能时,只需要新增实现类,而不需要修改现有的代码。例如,如果需要新增一个
Bird类,只需要继承Animal并实现makeSound方法。实现动态绑定: 通过多态,程序在运行时可以根据对象的实际类型进行方法调用,而不是在编译时确定调用哪个方法。这种动态绑定使得程序更加灵活和动态。
多态的实现方式
- 继承:通过继承基类的接口并重写其方法,子类可以表现出不同的行为。
- 虚函数:在基类中定义虚函数(virtual functions),并在子类中重写这些虚函数。通过基类指针或引用调用虚函数时,会调用实际对象的实现。
- 接口:在某些语言(如 Java 和 C#)中,通过实现接口(interface)来实现多态。接口定义了方法的签名,具体的实现由类提供。
3、重载和重写的区别?
重载(Overloading)
重载是指在同一个类中定义多个同名方法,但这些方法具有不同的参数列表(参数类型或参数个数)。编译器根据方法的参数列表来区分这些方法。在C++中,构造函数也可以被重载。
特点
- 方法名相同:重载的方法必须具有相同的名称。
- 参数列表不同:重载的方法必须具有不同的参数列表(参数类型或参数个数)。
- 返回类型可以不同:虽然返回类型可以不同,但返回类型不是区分重载方法的依据。
- 同一个类中:重载的方法必须定义在同一个类中。
例子
class Print {
public:
void display(int i) {
cout << "整数: " << i << endl;
}
void display(double f) {
cout << "浮点数: " << f << endl;
}
void display(string s) {
cout << "字符串: " << s << endl;
}
};
int main() {
Print obj;
obj.display(5); // 调用 display(int)
obj.display(3.14); // 调用 display(double)
obj.display("Hello");// 调用 display(string)
return 0;
}
重写(Overriding)
重写是指子类重新定义从基类继承的方法,目的是提供子类自己的实现版本。重写的方法必须具有相同的名称、参数列表和返回类型。重写通常与多态(Polymorphism)结合使用。
特点
- 方法名相同:重写的方法必须具有与基类方法相同的名称。
- 参数列表相同:重写的方法必须具有与基类方法相同的参数列表。
- 返回类型相同:重写的方法必须具有与基类方法相同的返回类型。
- 基类和子类之间:重写的方法在基类中声明,在子类中实现。
- 虚函数:在C++中,基类方法通常需要声明为虚函数(
virtual)以允许子类重写。
例子
class Animal {
public:
virtual void makeSound() {
cout << "Animal sound" << endl;
}
};
class Dog : public Animal {
public:
void makeSound() override { // 重写基类的 makeSound 方法
cout << "Woof" << endl;
}
};
int main() {
Animal* animal = new Dog();
animal->makeSound(); // 调用的是 Dog 类的 makeSound 方法
delete animal;
return 0;
}
4、TCP/IP 三次握手的过程,为什么要3次?
三次握手

在建立连接之前,Client处于CLOSED状态,而Server处于LISTEN的状态。
- 第一次握手(SYN-1):
- 客户端发送一个带有 SYN 标志的 TCP 报文段给服务器,表示客户端请求建立连接。
- 客户端选择一个初始序列号(ISN)并将其放入报文段中,进入 SYN_SENT 状态。
- 第二次握手(SYN + ACK):
- 服务器收到客户端发送的 SYN 报文段后,如果同意建立连接,会发送一个带有 SYN 和 ACK 标志的报文段给客户端,表示服务器接受了客户端的请求,并带上自己的 ISN。
- 服务器进入 SYN_RCVD 状态。
- 第三次握手(ACK):
- 客户端收到服务器发送的 SYN+ACK 报文段后,会发送一个带有 ACK 标志的报文段给服务器,表示客户端确认了服务器的响应。
- 客户端和服务器都进入 ESTABLISHED 状态,连接建立成功,可以开始进行数据传输。
为什么需要三次握手?
- 确保双方都能发送和接收数据:
- 第一次握手确认客户端的发送能力和服务器的接收能力。
- 第二次握手确认服务器的发送能力和客户端的接收能力。
- 第三次握手确认客户端的发送能力和服务器的接收能力。
- 防止旧的连接请求误导双方:
- 通过三次握手,双方都能确认对方的状态是最新的,有效避免了网络中的旧的、延迟的SYN包造成的错误连接。
- 防止重复数据包干扰:
- 三次握手确保双方都能有效处理重复的数据包,并建立一个唯一的连接。
5、进程和线程的区别?
定义
- 进程(Process):
- 进程是操作系统分配资源的基本单位。每个进程有自己独立的内存空间,包括代码段、数据段、堆、和栈。
- 进程之间相互独立,进程的创建、执行和销毁都是由操作系统管理的。
- 线程(Thread):
- 线程是进程的一个执行单元,是CPU调度的基本单位。一个进程可以包含多个线程,这些线程共享进程的资源(如内存和文件描述符)。
- 线程之间的切换比进程切换更轻量,因为线程共享进程的资源,不需要频繁的资源分配和回收。
区别
- 内存和资源:
- 进程:每个进程都有自己独立的地址空间和资源,相互之间不会直接干涉。进程之间的通信需要通过进程间通信(IPC)机制,如管道、消息队列、共享内存等。
- 线程:线程共享同一个进程的地址空间和资源,所以线程之间的通信更加直接、快速,但也带来了一些同步和互斥的问题。
- 创建和销毁:
- 进程:创建和销毁进程的开销较大,因为操作系统需要为进程分配和回收大量的资源。
- 线程:创建和销毁线程的开销较小,因为线程共享进程的资源,不需要重新分配内存。
- 切换开销:
- 进程:进程切换需要上下文切换,包括保存和恢复寄存器、内存映射等,开销较大。
- 线程:线程切换开销较小,因为线程共享同一进程的上下文,只需要保存和恢复少量的状态信息。
- 独立性和安全性:
- 进程:由于进程独立,进程间的错误不会相互影响,一个进程崩溃不会影响其他进程。
- 线程:由于线程共享资源,一个线程的错误(如内存泄漏、死锁)可能影响整个进程中的其他线程。
使用场景
- 进程:适用于需要高独立性和安全性的任务,比如不同用户的程序、服务和应用之间的隔离。
- 线程:适用于需要高效并发的任务,如多线程服务器、并行计算等,需要在同一进程内执行多个任务。
6、进程和CPU的关系?
进程是程序在计算机中的一次执行过程,它是CPU分配资源和执行指令的基本单位。CPU通过不断地切换执行不同的进程,实现了多任务同时执行的效果。当一个进程被CPU执行时,它会占用CPU的运行时间,执行其中的指令。当CPU需要执行其他任务时,会将当前进程的状态保存起来,并切换到其他进程执行,这样不断地在不同进程之间切换,就实现了多任务的效果。
7、多进程通讯方法,什么是消息队列?
- 管道(Pipe):管道是一种半双工的通信方式,可以在父进程和子进程之间传递数据。
- 命名管道(Named Pipe):类似于管道,但可以允许无亲缘关系进程之间通信。
- 消息队列(Message Queue):消息队列是一种进程间通信的方式,可以实现不同进程之间的数据传递。
- 共享内存(Shared Memory):共享内存是一种进程间通信的方式,允许多个进程访问同一块内存区域。
- 信号量(Semaphore):信号量是一种计数器,用于控制对共享资源的访问。
- 套接字(Socket):套接字是一种通信机制,可以在不同主机或同一主机的不同进程之间进行通信。
- 信号(Signal):信号是一种异步通信方式,用于通知进程发生了某种事件。
8、设计模式,什么时候用单例模式?
- 资源共享:当多个对象需要共享同一个资源时,可以使用单例模式来管理该资源,确保只有一个实例存在,避免资源被多次创建或重复使用。
- 全局访问点:某些对象在系统中需要被广泛访问,但又不希望通过传递对象的方式来访问,可以使用单例模式提供一个全局的访问点。
- 惰性初始化:某些资源或对象只在需要时才被初始化,可以使用单例模式延迟初始化对象,节省资源消耗。
- 线程池、缓存、日志对象等:在需要管理共享资源或全局状态的情况下,单例模式可以提供一种简单且有效的解决方案。
9、Linux常见命令?
10、反转head打头的单链表
思路
- 如果链表为空或者只有一个节点,直接返回头结点head。
- 初始化 pre 为 nullptr,cur 为头结点 head,node 为 cur 的下一个节点。
- 在循环中,不断更新 pre、cur 和 node 的值,使得 cur 的 next 指向 pre,然后将 pre、cur 和 node 分别向后移动一位。
- 当 cur 移动到链表末尾时,pre 就是反转后的新头结点。
参考代码
C++
#include <iostream>
struct ListNode {
int val;
ListNode* next;
ListNode(int x) : val(x), next(nullptr) {}
};
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return head; // 如果链表为空或者只有一个节点,直接返回头结点
}
ListNode* pre = nullptr; // 初始化 pre 为 nullptr
ListNode* cur = head; // 初始化 cur 为头结点
ListNode* node = nullptr; // 初始化 node 为 nullptr
while (cur != nullptr) {
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转
pre = cur; // 更新 pre
cur = node; // 更新 cur
}
return pre; // pre 就是反转后的新头结点
}
};
int main() {
ListNode* head = new ListNode(1);
head->next = new ListNode(2);
head->next->next = new ListNode(3);
Solution solution;
ListNode* newHead = solution.reverseList(head);
while (newHead != nullptr) {
std::cout << newHead->val << " ";
newHead = newHead->next;
}
return 0;
}
二面
1、进程和线程的区别?
详见一面
2、C++ 指针和引用的区别,为什么需要引用?
定义:
指针: 指针是一个包含变量地址的变量。通过指针,可以访问或修改存储在该地址上的值。
引用: 引用是一个别名,它为一个已存在的变量提供了另一个名字。引用在创建时必须初始化,并且一旦初始化后,它将一直引用相同的对象。
语法:
- 指针: 使用
*符号来声明指针,以及通过*来访问指针指向的值。
int x = 10; int *ptr = &x; // 指针的声明和初始化int value = *ptr; // 使用指针访问值- 引用: 使用
&符号来声明引用,没有类似*的解引用符号。
int x = 10; int &ref = x; // 引用的声明和初始化int value = ref; // 直接使用引用访问值- 指针: 使用
空值(NULL 或 nullptr):
- 指针: 可以是空值(nullptr 或 NULL),表示指针不指向任何有效的地址。
- 引用: 引用必须在创建时初始化,并且不能为 null。
地址操作:
- 指针: 可以通过指针进行地址的算术操作,比如指针加法和减法。
- 引用: 引用一旦初始化,不能改变引用的目标。
多级间接引用:
- 指针: 可以通过多级指针实现多级间接引用。
- 引用: 引用本身不支持多级引用。
数组:
- 指针: 可以通过指针对数组进行遍历和操作。
- 引用: 引用不直接支持数组的遍历,但可以通过指针和引用的结合来实现。
传递给函数:
- 指针: 通过指针可以实现函数的参数传递和返回。
- 引用: 通过引用也可以实现函数的参数传递和返回,但语法上更简洁。
使用场景:
- 指针: 通常用于动态内存分配、数组操作、实现数据结构等。
- 引用: 通常用于函数参数传递、返回引用值、以及在某些情况下取代指针使用。
3、什么是多态,是否可以把一个父类的对象赋给一个子类的指针?
多态指的是通过子类对象或子类类型的对象来调用父类中定义的方法,实现不同子类对象对同一消息的不同响应。
在C++中,可以通过继承和虚函数实现多态性。当父类的函数被声明为虚函数时,子类可以重写(覆盖)该函数,并且在运行时,会根据实际对象的类型来调用对应的函数。这就是多态的体现。
可以将一个父类的指针或引用指向一个子类的对象,这样就可以通过父类的指针或引用来访问子类的成员变量和方法。这种行为是安全的,因为子类对象也是一个父类对象,它继承了父类的属性和方法,所以可以将子类对象看作是父类对象的一种特殊形式。
4、计算机组成原理内容?
5、补码计算方法?
确定数的位数和符号位:假设我们要计算一个8位二进制数的补码,其中最高位为符号位(0表示正数,1表示负数)。
如果是正数:正数的补码就是其原码。例如,+3的8位原码是00000011,那么它的补码也是00000011。
如果是负数:
取反:先将负数的绝对值转换为二进制形式,然后对每一位取反(0变为1,1变为0)。例如,-3的绝对值是3,其二进制形式是00000011,取反后为11111100。
加1:将取反后的结果加1。例如,11111100加1得到11111101。
得到补码:将上述步骤得到的结果作为负数的补码。例如,-3的补码为11111101。
6、二进制补码?
二进制补码是用来表示有符号整数的一种方式,常用于计算机中。它解决了原码和反码表示法中0的符号位不统一的问题。在二进制补码表示法中,正数的补码与其二进制原码相同,而负数的补码是其二进制原码取反后加1。
下面是一些常见的二进制补码示例:
- 正数的二进制补码:正数的二进制补码与其二进制原码相同。例如,+5的二进制原码是00000101,那么它的二进制补码也是00000101。
- 负数的二进制补码:
- 计算绝对值的二进制原码:先将负数的绝对值转换为二进制形式。例如,-5的绝对值是5,其二进制原码是00000101。
- 取反:对绝对值的二进制原码的每一位取反。即,00000101的取反是11111010。
- 加1:将取反后的结果加1。即,11111010加1得到11111011。
- 得到补码:将上述步骤得到的结果作为负数的二进制补码。例如,-5的二进制补码是11111011。
二进制补码的一个重要性质是,对于任意一个整数,其补码加上其相反数的补码等于全1的二进制数。例如,5的补码是00000101,-5的补码是11111011,它们相加得到11111111,即全1的二进制数。
7、问题:最长回文子串
思路:
以字符串"babad"为例。
- 初始化状态:
- 首先创建一个二维数组
dp,其大小为n x n(n为字符串长度),并初始化所有元素为false。 - 对于长度为 1 的子串,即
dp[i][i],将对应位置的元素设为true,因为单个字符肯定是回文串。
- 首先创建一个二维数组
- 状态转移:
- 接下来从长度为 2 的子串开始,逐步扩展到长度为
n的子串,计算dp[i][j]的值。 - 对于每个长度为
len的子串,枚举起始位置i,计算结束位置j = i + len - 1。 - 如果
s[i] == s[j]且dp[i+1][j-1]为true,则说明去掉头尾两个字符后的子串是回文串,即dp[i][j] = true。
- 接下来从长度为 2 的子串开始,逐步扩展到长度为
- 记录最长回文子串:
- 在状态转移的过程中,记录下最长的回文子串的起始位置和长度。
- 每次更新
dp[i][j]为true时,更新起始位置start = i和最大长度maxLen = len。
- 返回结果:
- 最后根据记录的起始位置
start和最大长度maxLen,使用substr方法从原始字符串中取出最长回文子串并返回。
- 最后根据记录的起始位置
参考代码
C++
#include <iostream>
#include <vector>
#include <string>
using namespace std;
string longestPalindrome(string s) {
if (s.empty()) return "";
int n = s.length();
vector<vector<bool>> dp(n, vector<bool>(n, false)); // 定义二维动态规划数组
int start = 0, maxLen = 1; // 记录最长回文子串的起始位置和长度
for (int i = 0; i < n; ++i) {
dp[i][i] = true; // 单个字符肯定是回文串
if (i < n - 1 && s[i] == s[i + 1]) {
dp[i][i + 1] = true; // 相邻字符相同则是回文串
start = i;
maxLen = 2;
}
}
for (int len = 3; len <= n; ++len) { // 枚举子串长度
for (int i = 0; i + len - 1 < n; ++i) { // 枚举子串起始位置
int j = i + len - 1; // 子串结束位置
if (s[i] == s[j] && dp[i + 1][j - 1]) {
dp[i][j] = true; // 根据状态转移方程计算 dp[i][j]
start = i;
maxLen = len;
}
}
}
return s.substr(start, maxLen); // 返回最长回文子串
}
int main() {
string s = " ";
std::cout << "输入字符串:";
std::cin >> s;
std::cout << longestPalindrome(s) << std::endl; // 输出最长回文子串
return 0;
}
主管面
1、什么是动态规划,它常用的算法,他和贪心算法的区别?
这里直接给大家看一个维基百科给的解释:

动态规划常用的算法包括:
- 斐波那契数列问题:使用动态规划可以有效地计算斐波那契数列的第n项,避免了重复计算子问题。
- 背包问题:如0-1背包问题、完全背包问题等,动态规划可以用来解决这类问题,找到最优的物品组合。
- 最长递增子序列:动态规划可以用来解决寻找数组中最长递增子序列的问题。
- 最短路径问题:如最短路径算法中的Floyd-Warshall算法和Dijkstra算法等,动态规划可以用来计算最短路径。
动态规划和贪心算法的区别:
- 最优子结构:动态规划问题具有最优子结构性质,即问题的最优解可以通过子问题的最优解得到。而贪心算法则通常通过局部最优解来构建全局最优解,没有最优子结构的要求。
- 子问题重叠:动态规划问题的子问题通常是重叠的,即在求解过程中会多次遇到相同的子问题。而贪心算法不考虑子问题之间的关联性,只关注当前局部最优解。
- 选择方式:动态规划在求解过程中会考虑多种选择,并综合考虑它们的影响来得到最优解;而贪心算法每次只考虑局部最优解,不会回溯或者重新考虑之前的选择。
2、C++ 和 c 的区别?
- C是面向过程的语言,而C++是面向对象的语言。
- C和C++动态管理内存的方法不一样,C是使用malloc/free函数,而C++除此之外还使用new/delete关键字。
- C++的类是C里没有的,但是C中的struct是可以在C++中正常使用的,并且C++对struct进行了进一步的扩展,使得struct在C++中可以和class有一样的作用。而唯一和class不同的地方在于struct成员默认访问修饰符是public,而class默认的是private。
- C++支持重载,而C语言不支持。
- C++有引用,C没有。
- C++全部变量的默认链接属性是外链接,而C是内链接。
- C 中用const修饰的变量不可以用在定义数组时的大小,但是C++用const修饰的变量可以。
3、数据库什么情况使用索引?
- 频繁的查询操作:如果某个字段经常被用于查询操作,那么为该字段创建索引可以显著提高查询效率。
- 数据唯一性要求:对于要求数据唯一性的字段(如主键),应该为其创建索引,以确保数据的唯一性和快速查找。
- 连接查询:在连接查询中,连接的字段应该被索引,以提高连接查询的速度。
- 排序和分组:如果某个字段经常用于排序或分组操作,为该字段创建索引可以加快排序和分组的速度。
- 范围查询:对于范围查询(如 BETWEEN、>、<)经常用到的字段,应该创建索引以提高查询速度。
- 大数据表:对于数据量较大的表,应该根据查询需求创建索引,以提高查询效率。