Kafka 面试题指南
本文档提供了一份详细的 Kafka 面试题指南,涵盖了 Kafka 的核心概念、架构、配置、操作和实际应用场景等方面的内容。希望通过这份指南能够帮助你在 Kafka 面试中取得成功。
目录
Kafka 基础知识
什么是 Kafka?
Kafka 是一个分布式流处理平台,最初由 LinkedIn 开发,后捐赠给 Apache 软件基金会,并成为其顶级项目。Kafka 主要用于构建实时数据管道和流应用程序。它具有高吞吐量、低延迟、容错性强等特点,能够处理海量数据流的实时处理和分析。
Kafka 的主要特点是什么?
- 高吞吐量:Kafka 能够在低硬件配置下处理大量的数据流。
- 扩展性:Kafka 采用分布式架构,易于扩展。
- 持久性:Kafka 提供消息的持久化存储,保障数据不丢失。
- 容错性:通过复制机制,Kafka 确保了系统的高可用性和容错性。
- 高可靠性:消息确认机制确保数据准确传递。
Kafka 架构
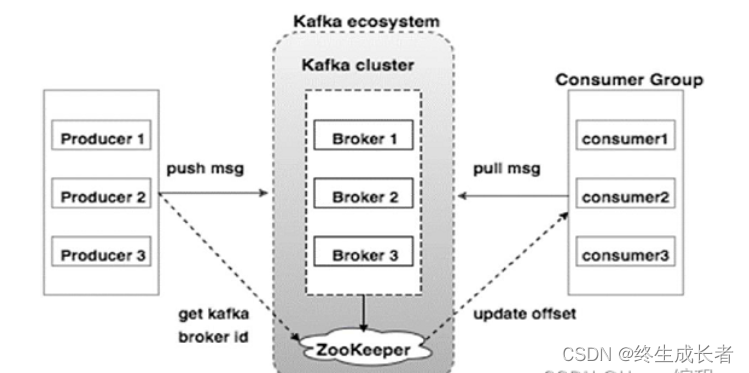
Kafka 的基本架构组件有哪些?
- Producer(生产者):发送消息到 Kafka 主题的客户端。
- Consumer(消费者):从 Kafka 主题中读取消息的客户端。
- Broker:Kafka 集群中的服务器节点,负责消息的存储和转发。
- Topic(主题):消息的类别或分类。
- Partition(分区):主题的物理分割,允许并行处理。
- Replica(副本):分区的备份,保障数据的高可用性。
- Zookeeper:用于协调和管理 Kafka 集群。
Kafka 的工作原理是什么?
Kafka 的工作原理基于发布-订阅模型。生产者将消息发送到指定的主题,主题又分为多个分区。消费者订阅主题,从分区中读取消息。每个分区都有多个副本,确保数据的可靠性。Zookeeper 用于管理集群的元数据和协调操作。
Kafka 配置与管理
Kafka 的配置文件有哪些?
Kafka 的主要配置文件包括:
server.properties:配置 Kafka broker 的属性。producer.properties:配置 Kafka 生产者的属性。consumer.properties:配置 Kafka 消费者的属性。zookeeper.properties:配置 Zookeeper 的属性。
如何配置 Kafka 的生产者和消费者?
生产者配置示例:
bootstrap.servers=localhost:9092
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
acks=all
retries=0
batch.size=16384
linger.ms=1
buffer.memory=33554432
消费者配置示例:
bootstrap.servers=localhost:9092
group.id=test-consumer-group
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
enable.auto.commit=true
auto.commit.interval.ms=1000
session.timeout.ms=30000
Kafka 操作
如何创建和删除 Kafka 主题?
创建主题:
bin/kafka-topics.sh --create --topic <topic-name> --partitions <number-of-partitions> --replication-factor <replication-factor> --bootstrap-server <broker-list>
删除主题:
bin/kafka-topics.sh --delete --topic <topic-name> --bootstrap-server <broker-list>
如何管理 Kafka 主题的分区?
增加分区:
bin/kafka-topics.sh --alter --topic <topic-name> --partitions <new-number-of-partitions> --bootstrap-server <broker-list>
注意:减少分区是不被支持的,因为可能会导致数据丢失。
Kafka 高级概念
Kafka 的副本机制是如何实现的?
每个分区的消息都有一个 leader 副本和多个 follower 副本。生产者只向 leader 副本发送消息,follower 副本从 leader 副本同步数据。当 leader 副本不可用时,Kafka 会自动选举一个新的 leader 副本,确保数据的高可用性。
Kafka 的分区分配策略有哪些?
Kafka 有两种主要的分区分配策略:
- Range Assignor:按范围分配,每个消费者分配到连续的分区。
- RoundRobin Assignor:按轮询分配,确保每个消费者分配到相同数量的分区。
Kafka 实践应用
Kafka 在大数据处理中的应用有哪些?
- 日志收集:集中收集分布式系统中的日志数据。
- 实时数据流处理:处理实时数据流,如点击流、交易数据等。
- 数据集成:将不同数据源的数据整合到数据仓库中。
- 监控与告警:实时监控系统状态,并触发告警。
如何优化 Kafka 的性能?
- 调整批量大小:增加
batch.size参数,减少网络开销。 - 压缩数据:启用消息压缩,减少数据传输量。
- 优化硬件配置:使用高性能磁盘和网络设备。
- 调整分区数:合理设置分区数,提升并行处理能力。
- 调整内存和缓存设置:优化 JVM 内存设置和操作系统缓存。
Kafka 面试题
基础题
- 什么是 Kafka?
- Kafka 的主要用途是什么?
- 解释 Kafka 的基本架构组件。
- 什么是 Kafka 的主题和分区?
进阶题
- 如何确保 Kafka 消息的可靠性?
- Kafka 是如何处理消息的持久化的?
- 如何配置 Kafka 生产者和消费者?
- 解释 Kafka 的副本机制。
高级题
- Kafka 的分区分配策略有哪些?各有什么优缺点?
- 如何优化 Kafka 的性能?
- Kafka 在大数据处理中的实际应用有哪些?
- 如何处理 Kafka 中的数据丢失和重复问题?
以上就是 Kafka 面试题的详细指南。通过深入理解和准备这些问题,希望你能够在 Kafka 面试中表现出色。