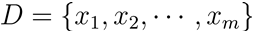AI学习指南机器学习篇-层次聚类原理
1. 引言
在机器学习领域,层次聚类是一种常见的无监督学习方法。它通过计算样本之间的相似度或距离来将它们分组成层次结构,形成一棵树状图,可视化地展现数据的聚类关系。本文将详细介绍层次聚类的原理,包括凝聚聚类和分裂聚类两种方法,并结合示例来解释如何构建聚类树。
2. 层次聚类原理
2.1 凝聚聚类
凝聚聚类是一种自底向上的聚类方法,它的基本思想是首先将每个样本看作一个单独的类别,然后通过计算样本之间的相似度或距离,不断将相似度最大的两个类别合并,直到所有样本被归为一个类别为止。这种方法的优势在于不需要事先指定聚类的数量,同时能够展现数据的聚类层次。
2.2 分裂聚类
分裂聚类与凝聚聚类相反,它是一种自顶向下的聚类方法。该方法首先将所有样本看作一个整体,然后通过计算样本之间的相似度或距离,将最不相似的样本分开,然后逐步分裂成更小的子集,直到满足某种停止准则为止。分裂聚类的优势在于能够处理大规模数据,且能够控制聚类的数量。
3. 构建聚类树的方法
构建聚类树是层次聚类的核心问题,而构建聚类树的关键在于计算样本之间的相似度或距离,并将其转化为树状图。下面将介绍两种常用的方法来构建聚类树。
3.1 相似度/距离计算
在层次聚类中,计算样本之间的相似度或距离是至关重要的。常用的相似度/距离计算方法包括欧氏距离、曼哈顿距离、余弦相似度等。例如,对于两个样本xi和xj,它们之间的欧氏距离可以表示为:
d(xi, xj) = sqrt(Σ(xi - xj)^2)
其中Σ表示对所有维度求和。根据不同的数据特点和需求,选择合适的相似度/距离计算方法是非常重要的。
3.2 聚类树构建
在计算得到样本之间的相似度或距离之后,接下来就是构建聚类树。常用的方法包括单链接聚类、完全链接聚类和平均链接聚类。以单链接聚类为例,对于n个样本,初始时将每个样本看作一个单独的类别。然后通过计算样本之间的相似度/距离,找到最相似的两个类别并将它们合并成一个新的类别。同时更新相似度矩阵,并继续上述过程,直到所有样本被归为一个类别。
4. 示例演示
为了更加直观地理解层次聚类的原理和构建聚类树的方法,下面将通过一个简单的示例来演示。
假设有以下6个样本:
| 样本 | 特征1 | 特征2 |
|---|---|---|
| A | 1 | 1 |
| B | 2 | 1 |
| C | 4 | 3 |
| D | 5 | 4 |
| E | 6 | 5 |
| F | 7 | 5 |
首先,我们需要计算样本之间的欧氏距离:
d(A, B) = sqrt((2-1)^2 + (1-1)^2) = 1
d(A, C) = sqrt((4-1)^2 + (3-1)^2) = 3.605
...
接下来,利用单链接聚类算法,不断合并相似度最大的两个类别,最终构建出聚类树。
5. 总结
通过本文的介绍,相信读者已经对层次聚类的原理和构建聚类树的方法有了更深入的理解。层次聚类作为一种简单而强大的聚类方法,被广泛应用于数据挖掘、模式识别、生物信息学等领域。在实际应用中,需要根据具体问题选择合适的相似度/距离计算方法和聚类树构建方法,从而得到准确的聚类结果。希望本文能够帮助读者更好地理解层次聚类,并在实践中取得更好的效果。
以上就是本文对层次聚类原理的详细介绍,希望对读者有所帮助。如果有任何疑问或意见,欢迎在评论区留言交流讨论。