目录
ElasticSearch介绍
Elasticsearch 是一个开源的、分布式的搜索引擎和分析引擎,建立在Apache Lucene库之上。它被广泛用于全文检索、结构化搜索、数据分析以及实时应用中。Elasticsearch 的核心特性包括:
- 分布式架构:Elasticsearch 设计为分布式系统,可以轻松地在多台服务器上扩展,处理大量数据并支持高并发请求。它自动管理数据的分片(sharding)和复制(replication),确保数据的可靠性和搜索性能。
- 全文搜索:利用倒排索引技术,Elasticsearch 提供了快速且高效的全文本搜索能力,支持复杂的查询语句,包括模糊匹配、短语匹配、同义词处理等。
- 实时分析:通过实时索引和近实时搜索功能,Elasticsearch 能够迅速地对新数据进行索引,并几乎立即可用作搜索和分析,非常适合实时日志分析和监控场景。
- RESTful API:所有的操作都可以通过其直观的RESTful API进行,这意味着你可以使用任何支持HTTP协议的语言来与之交互,非常便于集成和开发。
- 数据灵活性:Elasticsearch 支持JSON文档作为数据存储的基本单元,这种灵活性使得它能够处理半结构化和非结构化的数据,适合现代应用中多样化的数据类型。
- 聚合与分析:强大的聚合框架允许用户执行复杂的数据分析操作,如分桶(bucketing)、度量(metric)计算、管道聚合(pipeline aggregations)等,这对于生成报表和进行数据洞察非常有用。
- 安全性与监控:Elastic Stack(原ELK Stack,包含Elasticsearch、Logstash、Kibana)提供了X-Pack插件,增加了安全认证、授权、监控和报警等功能,确保系统的安全性和稳定性。
- Kibana集成:Elasticsearch 经常与Kibana一起使用,Kibana是一个可视化工具,可以帮助用户创建图表、仪表盘,进行数据探索和可视化分析,使得数据分析结果更加直观易懂。
综上所述,Elasticsearch 不仅是一个高性能的搜索引擎,也是一个强大的数据分析平台,适用于从简单的网站搜索到复杂的企业级应用的各种场景。
ElasticSearch架构
Elasticsearch 的架构设计围绕着高度可扩展性和容错性展开,主要由以下几个核心组件构成:
- 节点(Node):Elasticsearch 集群中的每一个运行实例称为一个节点(Node)。每个节点都存储数据、参与索引和搜索操作。节点之间通过网络通信,协同工作以实现集群功能。
- 集群(Cluster):一群节点的集合构成了一个Elasticsearch集群(Cluster)。集群由一个唯一的名称标识,默认为"elasticsearch"。所有节点必须属于同一个集群才能共享数据和负载均衡。
- 主节点(Master Node):在一个集群中,有一个或多个节点会被选举为主节点(Master Node)。主节点不直接存储数据,而是负责集群的管理和协调任务,比如新建或删除索引、跟踪哪些节点是集群的一部分、管理分片分配等。如果主节点失败,另一个节点会被选举为新的主节点。
- 数据节点(Data Node):负责存储数据和执行数据相关操作(如索引、搜索)的节点称为数据节点(Data Node)。在大型集群中,数据节点通常只负责数据处理,以优化资源使用。
- 索引(Index):索引是具有相似特征的文档集合。类似于传统数据库中的数据库或表的概念。每个索引都有一个唯一的名字,并且可以被分成多个分片(Shard)来分散存储和处理。
- 分片(Shard):索引可以被分割成多个分片,每个分片是一个独立的Lucene索引。分片有主分片(Primary Shard)和副本分片(Replica Shard)之分。主分片是原始数据的容器,而副本分片则是主分片的复制,用于提高数据的可用性和搜索性能。
- 副本(Replication):为了提高数据可靠性,Elasticsearch 允许为索引的每个主分片创建多个副本。这样即使某个节点或分片发生故障,数据也不会丢失,同时还能提高搜索请求的处理速度。
- 客户端(Client):客户端是应用程序与Elasticsearch集群交互的接口,它发送请求到集群并接收响应。客户端可以是Java客户端、HTTP REST API客户端或者是Elasticsearch提供的各种语言的客户端库。
- 发现模块(Discovery Module):负责节点之间的发现和选举主节点。它依赖于如Zen Discovery这样的模块来实现节点间的通信和集群状态的维护。
整个Elasticsearch架构设计得非常灵活,可以根据需要动态地添加或移除节点,调整索引的分片数量,以及设置副本策略,从而轻松应对数据量的增长和查询负载的变化。
ElasticSearch深度分页
在 Elasticsearch 中,深度分页(即请求结果集中的大量偏移量,如从第10000条记录开始获取结果)可能会导致性能问题,尤其是当涉及大量数据时。这是因为Elasticsearch为了获取指定偏移量后的结果,需要遍历跳过的所有文档,这会消耗大量的CPU资源和内存。
为了解决这个问题,Elasticsearch 提供了几种更高效的替代方案来实现深度分页:
- Search After:这是一种基于排序字段的分页方法。首先执行一个搜索请求,获取到第一批结果,并记住最后一个文档的排序值。然后,在下一次请求中,使用search_after参数,传入上一次请求中最后一个文档的排序值作为搜索起点。这种方法避免了需要指定from和size带来的性能开销,特别适用于连续翻页的场景。
- Scroll:Scroll API 适合一次性获取大量数据,特别是在数据视图不会频繁变化的情况下。启动一个 Scroll 会话后,Elasticsearch 会保持对当前视图的快照,允许你通过多次滚动请求来迭代所有匹配的结果。每个Scroll请求都会返回一个_scroll_id_,以及一批结果,直到没有更多结果为止。需要注意的是,Scroll会话是有生命周期的,过期后会失效。
- Pit(Point in Time) API:这是Elasticsearch 7.0引入的一个新特性,类似于Scroll API,但提供了更好的性能和灵活性。PIT API允许你打开一个索引的快照视图,然后在这个快照上执行多次搜索,而不需要像Scroll那样维护一个长时间的会话。使用PIT时,你需要先创建一个点在时间的引用,然后在每次请求中带上这个引用进行查询,直到不再需要该视图时手动关闭它。
这些方法相比传统的深度分页(使用from和size参数),能够显著提高性能和用户体验,尤其是在处理大数据集时。选择哪种方法取决于具体的应用场景和需求。
ElasticSearch调优手段有哪些
1、索引设计与映射优化:
- 合理选择分析器:根据查询需求选择合适的分析器,平衡索引速度和查询效率。
- 使用合适的数据类型:比如,对于不需要精确排序的字段使用keyword类型代替text类型。
- 禁用无用字段的存储:减少存储空间,提高索引速度。
- 设置合理的副本数:平衡查询性能和数据安全性。
2、分片与副本策略:
- 分片数量调整:过多的分片会导致内存碎片化和管理开销增大,建议单个节点上的分片数量不超过几千个。
- 副本分布:确保副本均匀分布在各个节点上,避免数据倾斜。
3、硬件优化:
- 内存配置:合理分配 JVM 堆内存,避免频繁GC。确保有足够的系统内存用于文件缓存。
- 磁盘选择:使用高速磁盘(如SSD)可以显著提高I/O性能。
- 网络配置:优化网络设置,确保足够的带宽和低延迟。
4、查询优化:
- 使用过滤器上下文查询:对于只用于过滤的条件使用filter,避免分数计算。
- 优化聚合操作:限制聚合的深度和范围,使用aggs的子选项如size、terminate_after限制结果集大小。
- 缓存利用:利用请求缓存和查询结果缓存。
5、系统与配置调优:
- 索引刷新间隔:适当增加index.refresh_interval以减少索引写入时的I/O压力。
- 合并策略:调整index.merge.policy以优化段合并,减少磁盘I/O和提升查询速度。
- 监控与日志:启用并监控Elasticsearch的慢日志和性能指标,及时发现并解决问题。
6、集群监控与管理:
- 使用APM监控:集成Elastic Stack的APM工具,监控应用程序和Elasticsearch的性能。
- 热温冷架构:根据数据访问频率,设计不同的索引存储策略,例如使用ILM(索引生命周期管理)自动迁移数据至低成本存储。
7、插件与模块管理:
- 确保安装必要的插件,同时避免不必要的插件以减少系统负担。
调优是一个持续的过程,需要根据实际应用场景、数据量和查询模式不断测试和调整。此外,保持Elasticsearch及其依赖软件的版本更新也是维持高性能的关键。
ElasticSearch脑裂了怎么办
Elasticsearch脑裂(Split-Brain)是指集群中的一部分节点无法与其他节点通信,导致集群分裂成多个独立的子集群,每个子集群都认为自己是主集群并可能独立进行写操作,从而造成数据不一致的问题。解决脑裂问题通常涉及以下几个步骤:
1、预防措施:
配置最小主节点数(discovery.zen.minimum_master_nodes):这是防止脑裂的最重要设置。这个值应该是(N/2)+1,其中N是集群中可能成为主节点的节点数。确保该值正确设置,可以避免在部分节点不可达时形成多个主节点。
2、立即识别与诊断:
使用cluster-health API检查集群状态,确认是否发生脑裂。
查看集群日志,寻找网络问题或节点故障的线索。
3、恢复通信:
确保网络问题被解决,恢复节点间的网络连接。
如果是单个或少数节点故障,考虑重启这些节点。
4、处理数据冲突:
如果脑裂期间发生了写操作,可能需要手动或通过工具(如Elasticsearch的Reindex API)来合并或选择性地恢复数据。
评估受影响的索引和文档,决定是否需要回滚到某个时间点的快照或者手动修复差异。
5、避免进一步操作:
在问题未完全解决之前,避免在集群上执行大规模写操作,以免情况复杂化。
6、集群重建:
在极端情况下,如果数据不一致严重且难以修复,可能需要从最近的完整备份恢复集群,然后重新导入自备份以来的数据变化。
7、长期策略:
定期审查和测试灾难恢复计划,包括备份与恢复策略。
采用跨数据中心部署和更高级的容错机制,如使用专用网络、改进网络架构,或部署专用的网络设备来提高网络稳定性和可靠性。
ElasticSearch的倒排索引
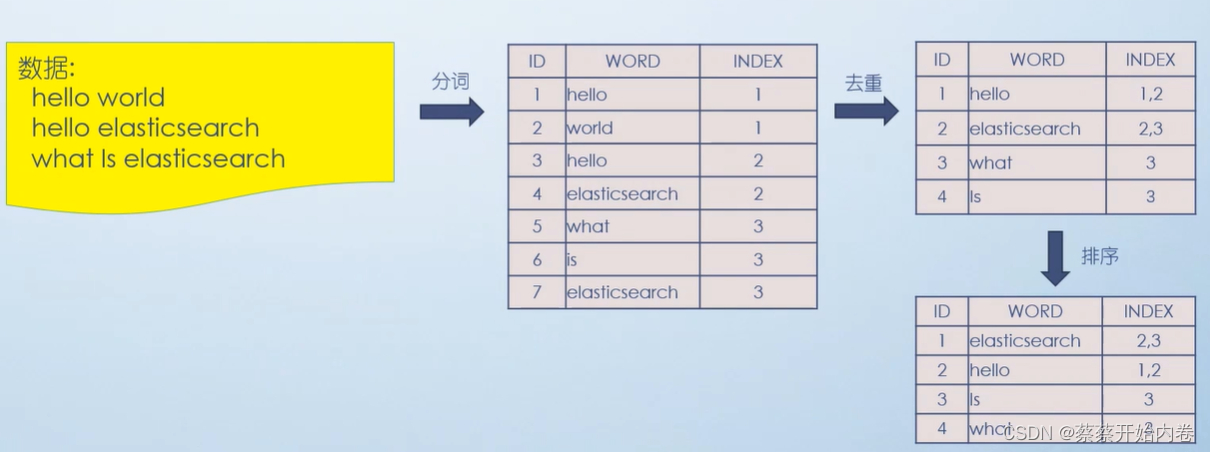
Elasticsearch中的倒排索引(Inverted Index)是一种数据结构,它颠覆了传统的文档到词汇的索引方式,转而采用词汇到文档的映射关系,这种设计极大地优化了全文搜索的速度和效率。下面是倒排索引的基本概念及其在Elasticsearch中的应用:
基本原理
- 文档分词:当文档被添加到Elasticsearch中时,首先会对其进行分析(分析过程包括分词、去除停用词等),将文本拆分成一个个词项(Term)。
- 创建倒排表:对于每一个词项,系统会维护一个列表,记录所有包含该词项的文档及其出现频率、位置等信息。这个列表被称为倒排列表(Posting List)。因此,倒排索引本质上是一个词项到其所在文档集合的映射。
特点与优势
- 快速查询:查询时,Elasticsearch直接查找相关词项的倒排列表,立即知道哪些文档包含该词,无需遍历整个文档集。
- 支持多关键词查询:通过交集、并集等操作轻松实现AND、OR逻辑查询,因为每个词项都有自己的倒排列表,容易合并这些列表来找到满足条件的文档。
- 排序与相关度评分:倒排索引中还包含了词频、文档频率等信息,可以用于计算文档与查询的相似度,实现高效的排序。
Elasticsearch中的扩展
- 分片与副本:Elasticsearch将数据分散存储在多个分片(Shard)中,每个分片有自己的倒排索引,同时通过副本(Replica)提高可用性和查询性能。
- 近实时搜索(NRT):Elasticsearch提供了近乎实时的索引更新能力,文档一旦被索引就能很快被搜索到,尽管这需要一个轻微的刷新周期。
- 压缩与缓存:为了节省空间和提高效率,倒排索引可以被压缩存储,并且Elasticsearch利用缓存技术加快频繁查询的响应速度。
倒排索引是Elasticsearch高效全文检索的核心,通过这种数据结构,Elasticsearch能够支持大规模数据集上的快速、复杂的全文搜索请求。
ElasticSearch如何实现master选举
ElasticSearch实现master选举的过程主要通过其内置的Zen Discovery机制来完成。以下是ElasticSearch实现master选举的详细步骤:
1. 节点发现
- Zen Discovery模块:通过Ping机制来发现集群中的节点。节点使用Ping机制相互通信以了解彼此的存在。Ping机制可以基于多种传输方式,如多播(multicast)或单播(unicast)。
- 节点ID:每个节点都有一个唯一的ID(node id),用于在集群中标识自己。
2. 主节点候选
- 配置检查:只有配置了node.master: true的节点才能成为主节点的候选。
- 候选节点列表:所有主节点候选节点会形成一个候选列表,用于后续的选举过程。
3. 选举过程
- 排序:在选举过程中,每个候选节点都会将已知的候选节点列表进行排序。排序通常基于节点ID或其他可配置的规则。
- 预选阶段:每个候选节点会向其他候选节点发送预选请求,并等待响应。如果一个节点收到了超过一半的响应,它将进入下一阶段。
- 选举阶段:在选举阶段,每个候选节点会向其他候选节点发送选举请求,并等待响应。选举规则通常基于多数决定原则,即一个节点需要获得超过半数的投票才能成为主节点。
- 投票规则:投票规则可能会考虑节点的健康状况、存储的数据量、负载情况等因素。同时,为了防止恶意节点滥用选举机制,ElasticSearch还采用了数据一致性检查、节点认证等安全措施。
4. 选举结果
- 主节点确定:如果某个候选者得到了超过半数的投票,并且该节点也投票给了自己,那么它将成为新的主节点。
- 集群状态更新:一旦新的主节点被选出,集群状态将更新,所有节点都将与新主节点通信,并遵循其指令。
5. 特殊情况处理
- 网络分区:如果发生网络分区,Zen Discovery机制会尝试重新选举主节点,以确保集群的可用性。
- 主节点故障:如果当前主节点发生故障,其他候选节点将自动开始新的选举过程,以选出新的主节点。
6. 配置优化
- 最小主节点数:为了防止脑裂问题(即集群中出现多个主节点的情况),可以通过设置discovery.zen.minimum_master_nodes参数来指定最小主节点数。这个值应该设置为候选节点数的一半加一(N/2+1)。
7. 注意事项
- 节点数量:集群中的节点数量应足够多,以确保在发生节点故障时能够成功选举出新的主节点。
- 监控和日志:定期检查集群状态和日志,以便及时发现并解决问题。
通过以上步骤,ElasticSearch能够确保在集群中选举出一个稳定、可靠的主节点,从而维护集群的正常运行和数据的可用性。
ElasticSearch的搜索过程说下
Elasticsearch的搜索过程可以分为几个关键步骤,这些步骤共同实现了高效、实时的数据检索功能。下面是一个简化的概述:
1. 请求接收与解析
- 当客户端(如Web应用或API请求)发送一个查询请求到Elasticsearch时,首先由某个节点(可以是任意节点,因为所有节点对搜索请求都是透明的)接收这个请求。
- 接收节点会解析请求,提取出查询语句、过滤条件、排序需求、分页参数等信息。
2. 查询分发与执行
- Query Parsing:解析后的查询被转换成一种结构化查询语言,便于执行。
- Distributed Querying:解析后的查询会被广播到集群中的所有数据节点(或根据索引映射预先确定的节点)。Elasticsearch使用一种称为“Query-Then-Fetch”的策略,或者在某些场景下使用更高效的“Distributed Term Frequency”(DFS)查询模式。
- Shard-Level Search:每个节点上的分片(shard)独立执行查询,只搜索本地数据。这意味着搜索操作在各个节点上并行执行,极大地提升了效率。
3. 结果收集与聚合
- Partial Results:每个分片完成搜索后,将部分结果(匹配的文档ID和评分)返回给最初接收请求的节点(协调节点)。
- Score Calculation:协调节点汇总所有分片的结果,计算最终的文档评分(如果查询需要的话),并根据请求中的排序规则对文档进行排序。
- Aggregation:如果查询中包含了聚合(aggregations),协调节点还会执行聚合操作,对结果集进行统计分析,比如计数、平均值、百分位数等。
4. 结果返回
- 最终排序和处理后的结果被汇总成响应,包含匹配的文档ID、分数(如果查询中请求了分数)、聚合结果等信息。
- 协调节点将此响应返回给客户端。
5. 缓存与优化
- Elasticsearch还会利用查询缓存来加速重复查询的响应时间。如果一个查询的执行结果已经被缓存,它可以直接从缓存中读取而不需要再次执行整个搜索流程。
注意事项
- Elasticsearch支持复杂的查询语法,包括全文本搜索、布尔查询、范围查询、地理空间查询等,以及多种聚合类型。
- 性能优化是搜索过程中一个重要考虑因素,包括索引设计、分片和副本策略、查询优化等。
- Elasticsearch提供了丰富的API和工具,允许开发者细粒度地控制搜索行为和性能。
ElasticSearch如何在并发情况下保证读写一致
Elasticsearch在并发读写场景下确保数据一致性主要依靠以下几个机制:
1. 事务日志(Translog)
- 持久化保证:Elasticsearch使用事务日志(Transaction Log)记录每次写操作,类似于数据库中的WAL(Write-Ahead Log)。在索引操作完成之前,相关信息会先写入事务日志。这样即使在写入过程中发生故障,也能从事务日志恢复,确保数据不会丢失。
- 刷新(Refresh):默认每隔一秒(可配置),Elasticsearch会执行一次刷新操作(Refresh),将内存中的缓冲区(Buffer)数据写入新的Lucene段(Segment),同时清空缓冲区。这使得新索引的数据可以被搜索到,但此时数据尚未完全持久化到磁盘。
- 提交(Commit):事务日志在达到一定条件(例如时间间隔或事务日志大小)时,会触发一个提交(Commit)操作,将缓冲区数据和事务日志中的信息真正持久化到磁盘上的Lucene段,并清空事务日志。这是确保数据持久化和一致性的关键步骤。
2. 版本控制(Versioning)
- Elasticsearch为每条文档记录一个内部版本号,每次文档更新都会导致版本号递增。在并发写入时,通过对比版本号来决定写操作的成功与否,从而避免并发冲突。如果客户端尝试更新的文档版本号低于当前版本号,该操作将失败,客户端需要重新获取最新版本并重试。
3. 乐观锁(Optimistic Locking)
- Elasticsearch采用乐观锁策略来处理并发写入。当多个写请求同时到达时,Elasticsearch假设大部分情况下不会有冲突,因此先允许写操作进行。但在提交阶段,通过版本号校验来确保写操作的一致性。如果检测到冲突,则其中一个或多个写操作会因版本冲突而失败。
4. 读写分离
- 在读写并发较高的场景下,Elasticsearch可以通过设置副本分片来实现读写分离。主分片负责处理写操作,而副本分片则负责处理读请求,这样可以减少读写操作之间的冲突,提高系统的整体吞吐量。
5. 索引别名(Index Aliases)
- 索引别名可以用来指向实际的索引,这样在进行索引滚动更新时,可以先创建新索引并写入新数据,待数据完全同步后再切换别名指向,这一过程对客户端是透明的,保证了读写的一致性。
综上所述,Elasticsearch通过事务日志、版本控制、乐观锁机制、读写分离以及索引别名等策略,在高并发读写场景下确保了数据的一致性和可靠性。
ElasticSearch的常用分词器有哪些,有什么优缺点
1. 标准分词器(Standard Analyzer)
优点:
- 通用性:适用于大多数英文文本的全文搜索场景。
- 简单高效:基于空格和标点符号进行分词,处理速度快。
- 小写化:自动将英文文本转换为小写,有助于实现不区分大小写的搜索。
缺点:
- 中文处理不足:对于中文文本,标准分词器会将每个汉字视为一个独立的词项,这通常不是理想的中文分词方式。
2. IK Analyzer
优点:
- 细粒度分词:提供了细粒度和粗粒度两种分词模式(ik_smart和ik_max_word),能够满足不同场景的需求。
- 高性能:分词效果好且性能较高,广泛应用于中文搜索场景。
- 自定义词典:支持自定义词典,可以根据实际需求添加或修改分词规则。
缺点:
- 依赖性强:需要手动下载并集成到ElasticSearch中,增加了部署的复杂性。
3. SmartCN Analyzer
优点:
- 中文优化:基于Lucene的SmartCN分词器进行封装,能够较好地处理中文的复杂结构,如人名、地名、数字、日期等。
- 内置支持:作为ElasticSearch的内置分词器之一,无需额外安装即可使用。
缺点:
- 灵活性不足:相较于IK Analyzer等第三方分词器,SmartCN Analyzer在分词规则和自定义方面可能较为受限。
4. Jieba Analyzer
优点:
- 准确性高:采用统计和规则的方式进行分词,具有较高的分词准确性。
- 多领域适用:适合处理中文的特定领域文本,如新闻、微博等。
缺点:
- 集成复杂:需要通过Java的Jython库将基于Python的Jieba分词器集成到ElasticSearch中,增加了部署难度。
5. HanLP Analyzer
优点:
- 多语种支持:支持多语种分词,具有较高的分词准确性和多语种支持能力。
- 深度学习技术:采用深度学习和统计的方式进行分词,能够处理复杂的语言现象。
缺点:
- 资源消耗大:由于采用了深度学习技术,可能需要更多的计算资源和内存。
6. 自定义分词器(Custom Analyzer)
优点:
- 高度灵活:允许用户根据具体需求定义自己的分词规则、字符过滤器和词项过滤器。
- 适用性强:能够精确匹配特定业务场景的分词需求。
缺点:
- 配置复杂:需要深入理解ElasticSearch的分词机制,并进行复杂的配置工作。
总结
在选择ElasticSearch的分词器时,需要根据具体的业务场景和需求来权衡各种分词器的优缺点。对于中文搜索场景,IK Analyzer和HanLP Analyzer是较为常用的选择;而对于英文或通用文本搜索场景,标准分词器或SmartCN Analyzer可能更为合适。同时,自定义分词器提供了高度的灵活性,但也需要更多的配置工作。
引用:通义千问、文心一言