🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职相关(简历撰写技巧、面经资料与心得)多方面综合学习平台,强烈推荐AI小白及AI爱好者学习,性价比非常高!加入星球➡️点击链接
【 书生·浦语大模型实战营】学习笔记(一):全链路开源体系介绍
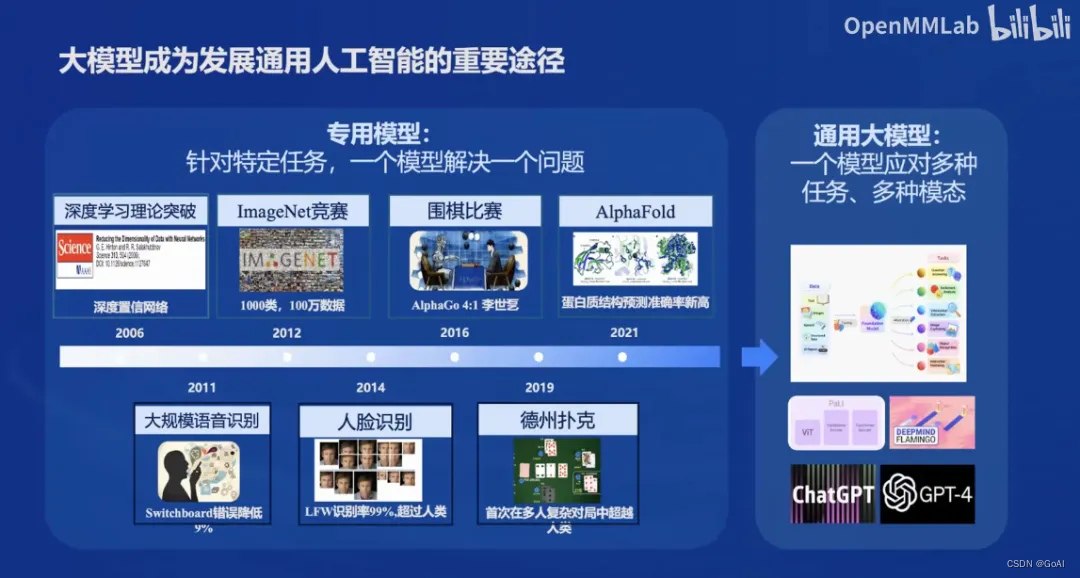
👨💻导读: 随着人工智能技术的不断发展,大模型成为发展通用人工智能的重要途径。书生·浦语大模型的全链路开源体系,使探索AI的无限可能,本文主要从书生·浦语大模型发展、分类、组成进行详细介绍,方便大家理解,如有错误请指正,欢迎学习互相交流。
一、书生浦语大模型开源历程
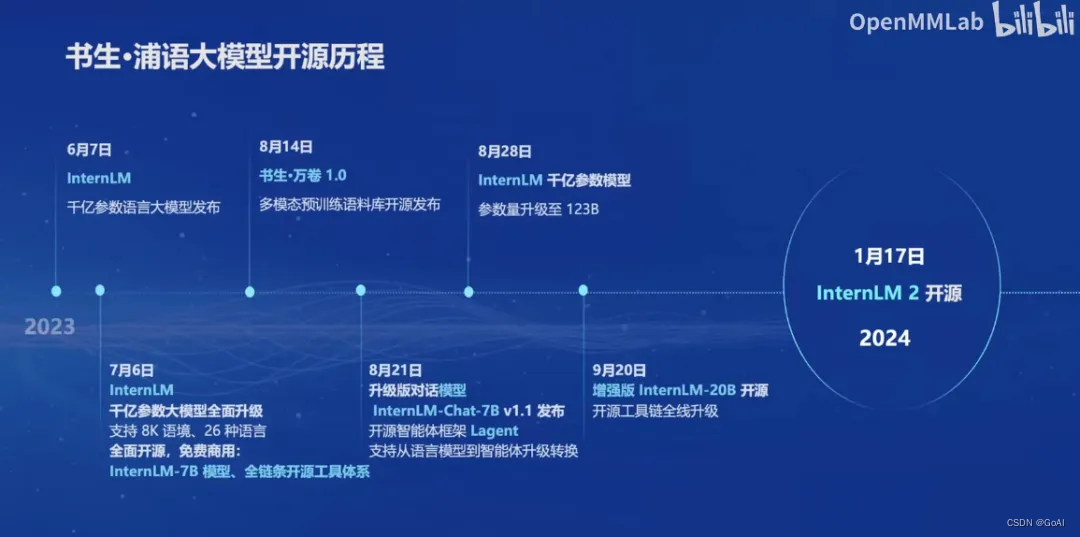
- 2023年6月7日InternLM千亿参数语言大模型发布。
- 2023年7月6日,InternLM千亿参数大模型全面升级,支持8K语境、26种语言,并全面开源,免费商用。
- 2023年8月14日,书生万卷1.0多模态预训练语料库开源发布。
- 2023年8月21日,升级版对话模型InternLM-Chat-7B v1.1发布,同时开源智能体框架Lagent,支持从语言模型到智能体升级转换。
- 2023年8月28日,InternLM千亿参数模型参数量升级到123B。
- 2023年9月20日,增强型InternLM-20B开源,开源工具链全线升级。
- 2024年1月17日,InternLM2开源。
二、InternLM2的分类
按规格分类:有7B和20B两种模型
7B:为轻量级的研究和应用提供了一个轻便但性能不俗的模型
20B:模型的综合性能更为强劲,可有效支持更加复杂的使用场景按使用需求分类:InternLM2-Base、InternLM2、InternLM2-Chat三种。
其中InternLM2在Base基础上,在多个能力方向进行了强化。而Chat版本则是在Base基础上,经过SFT和RLHF,面向对话交互进行了优化,具有很好的指令遵循,共情聊天和调用工具等能力。
三、书生浦语2.0主要亮点
书生浦语2.0在超长上下文、综合性能、对话和创作体验、工具调用能力以及数理能力和数据分析功能等方面都有显著优势。其中,InternLM2-Chat-20B在重点评测上甚至可以达到比肩ChatGPT GPT3.5水平。
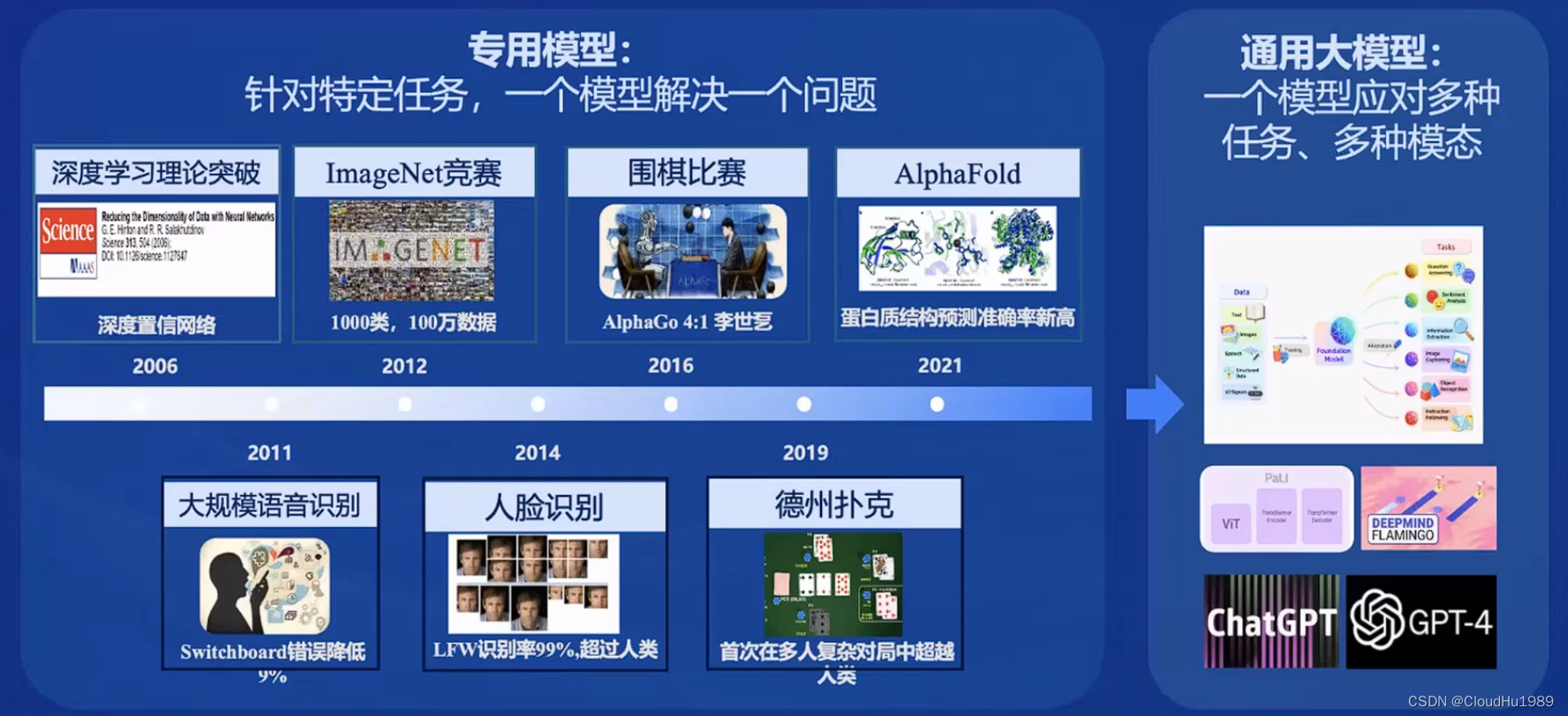
四、从模型到应用
书生浦语全链条开源开放体系包括数据、预训练、微调、部署、评测和应用等方面。这些环节的不断完善和优化,使得书生浦语大模型能够更好地服务于各种应用场景。
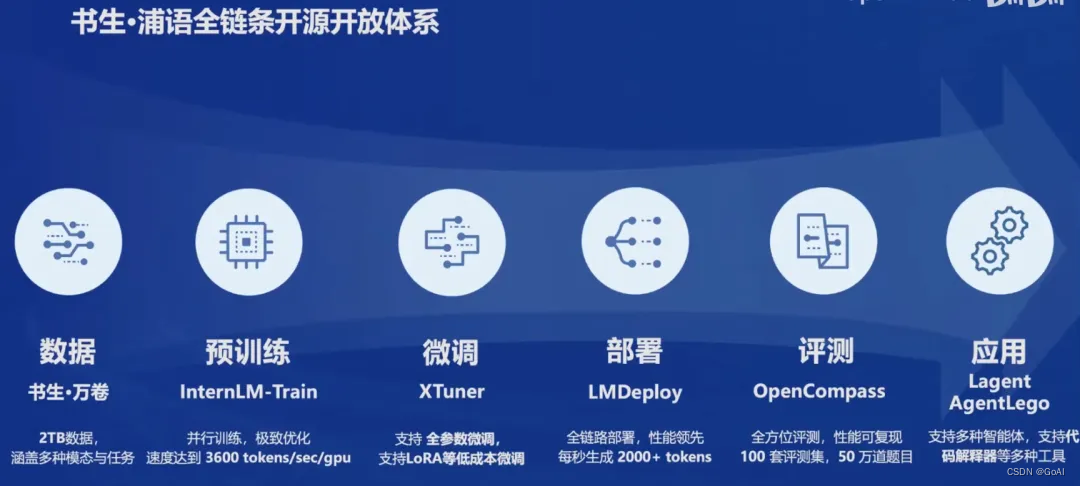
1、数据

书生·浦语大模型的数据集名为"书生·万卷",发布日期 2023 年 8 月 14 日。它是一个包含1.6万亿token的多语种高质量数据集,涵盖多种模态和任务。包含文本数据(50 亿个文档,数据量超 1TB),图像-文本数据集(超 2200 万个文件,数据量超 140GB),视频数据(超 1000 个文件,数据量超 900GB)。这个数据集为模型的训练提供了丰富的语言信息和知识基础。
2、预训练
书生·浦语大模型使用了InternLM-Train进行预训练。InternLM-Train是一个基于Transformer架构的预训练模型,它具有1040亿参数,通过在书生·万卷数据集上进行训练,使模型具备了强大的语言理解和生成能力。它支持从 8 卡到千卡训练,千卡训练效率达 92%;无缝接入 HuggingFace 等技术生态,支持各类轻量化技术。
3、微调

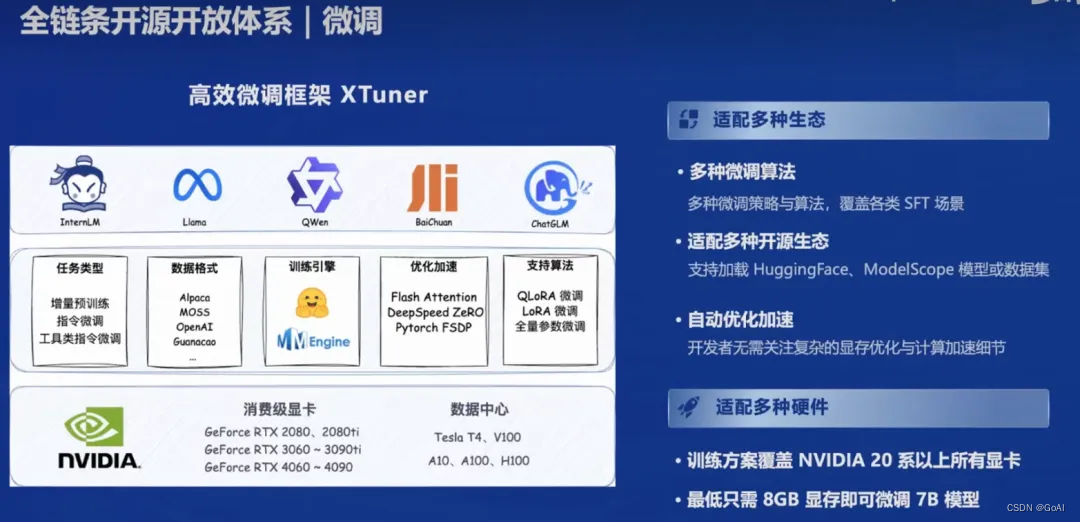
为了进一步提升模型的性能和适应特定任务,上海人工智能实验室开发了XTuner微调框架。XTuner可以根据不同的任务需求,对大模型进行微调,使其在特定领域或任务上表现更加优秀。它具有以下特点:
支持多种任务类型,如增量预训练,指令微调,工具类指令微调
支持全量参数、LoRA、QLoRA 等低成本微调,覆盖各类 SFT 场景
支持多种大语言模型的微调,如 InternLM, Llama, QWen, BaiChuan, ChatGLM,适配多种开源生态,支持加HuggingFace、ModelScope 模型或数据集
支持自动优化加速,如 Flash Attention, DeepSpeed ZeRO, 使得开发者无需关注复杂的现存优化与计算加速细节
支持多种硬件,覆盖 NVIDIA 20 系以上所有显卡,最低只需 8GB 现存即可微调 7B 模型
支持多种数据格式,如 Alpaca, MOSS, OpenAI, Guanacao 等等。
4、部署

在模型应用方面,开发LMDeploy部署框架。
LMDeploy提供大模型在 GPU 上部署的全流程解决方案,包括模型轻量化、推理和服务。可以将大模型快速部署到各种计算平台上,实现模型的实时推理和应用。
- 接口支持:Python, GRPC, RESTful
- 量化支持:4bit 、8bit
- 推理引擎:turbomind, pytorch
- 服务:openai-server, gradio, triton inference server
5、评测
在评测方面,开发了OpenCompass评测框架,包含80 套评测集,40 万道题目。OpenCompass可以对模型在多个任务和数据集上的表现进行全面评估,从而了解模型的优势和局限性。它具体包括6 大维度的评测集:
- 学科:初中考试、中国高考、大学考试、语言能力考试、职业资格考试
- 语言:字词释义、成语习语、语义相似、指代消解、翻译
- 知识:知识问答、多语种知识问答
- 理解:阅读理解、内容分析、内容总结
- 推理:因果推理、常识推理、代码推理、数学推理
- 安全:偏见、有害性、公平性、隐私性、真实性、合法性
6、应用
在应用方面,开发了Lagent多模态智能体工具箱和AgentLego多模态智能体工具箱。这些工具箱可以帮助开发者构建和训练多模态智能体,实现图文混合创作、多模态对话等应用场景。
Lagent 是一种轻量级智能体框架,它具有以下特点:
- 支持多种类型的智能体能力,如 ReAct, ReWoo, AutoGPT 灵活支持多种大语言模型,如 OpenAI 的
GPT-3.5/4, 上海人工智能实验室的 InternLM, Hugging Face 的 Transformers, meta 的 Llama 简单易拓展,支持丰富的工具,如 AI 工具(文生图、文生语音、图片描述),能力拓展(搜索,计算器,代码解释器), RapidAPI(出行 API, 财经 API, 体育咨询 API)
AgentLego是一种多模态智能体工具箱,它具有以下特色:
- 丰富的工具集合,尤其是提供了大量视觉、多模态相关领域的前沿算法功能支持多个主流智能体系统,如 Lagent, LangChain, Transformers Agent 等灵活的多模态工具调用接口,可以轻松支持各类输入输出格式的工具函数一键式远程工具部署,轻松使用和调试大模型智能体。
InternLM2技术报告
Github : https://github.com/InternLM/InternLM/
论文地址:https://arxiv.org/pdf/2403.17297.pdf
本文主要介绍 InternLM2预训练数据、预训练设置以及三个预训练阶段。
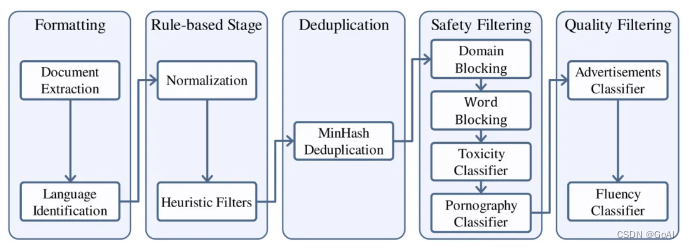
1.数据处理流程:
- 将来自不同来源的数据标准化以获得格式化数据。
- 使用启发式统计规则对数据进行过滤以获得干净数据。
- 使用局部敏感哈希(LSH)方法对数据去重以获得去重数据。
- 应用一个复合安全策略对数据进行过滤,得到安全数据。其中对不同来源的数据采用了不同的质量过滤策略,最终获得高质量预训练数据。
2.预训练设置
Tokenization:
论文选择使用GPT-4的tokenization方法,在压缩各种文本内容方面非常高效。主要参考是cl100K词汇表,它主要包含英语和编程语言的 token,共计100,256条,其中包括不到3,000个中文 token。为了在处理中文文本时优化InternLM的压缩率,同时将总体词汇量保持在100,000以下,我们从cl100k词汇中仔细挑选了前60,004个token,并将其与32,397个中文token集成。此外,我们还加入了147个备用token,最终得到的词汇量符合256的倍数,从而便于高效训练。
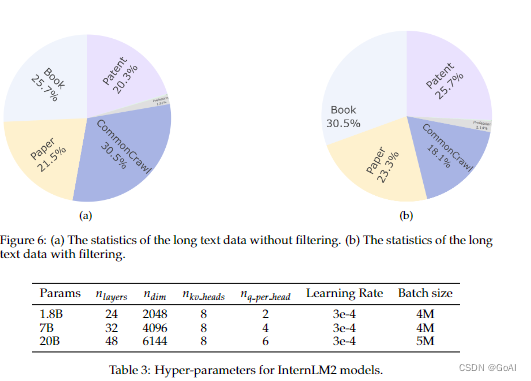
超参数:
在训练过程中,我们使用AdamW优化模型,其参数设置为beta_1=0.9, beta_2=0.95, epsilon=1e-8, weight_decay=0.1。采用余弦学习率衰减,学习率衰减至其最大值的10%,不同规模参数的超参数配置如下:
3.预训练阶段
3.1长上下文训练
扩展上下文窗口可以显著提高 LLM 在各种应用中的表现,例如检索增强生成和智能代理。
InternLM2训练过程从4K上下文的语料库开始,然后过渡到32K上下文的语料库。 尽管使用了32K长度的语料库,仍有50%的数据长度短于4096个tokens。这个长上下文训练阶段占整个预训练过程的大约9%。为了适应这些更长的序列,确保为长上下文提供更有效的位置编码(Liu et al., 2023b),我们将旋转位置嵌入(RoPE) 的基础从50,000调整到1,000,000。得益于 InternEvo 和 flash attention 的良好可扩展性,当上下文窗口从4K更改为32K时,训练速度仅降低了40%。
3.2 特定能力增强训练
经过特定能力增强训练阶段之后,InternLM2模型在编程、推理、问题回答和考试等方面表现出显著的性能提升。
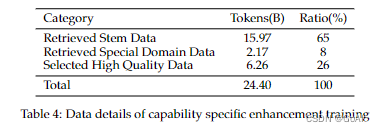
在InternLM 2中收集了一个丰富的数据集,其中包含精心策划的高质量检索数据和来自Huggingface数据集平台的各种类型的开源数据。在这个数据集中总共收集了240亿个tokens。
4. 最终与其他模型对比结果:

5.总结:
本文为实战营第一次课程笔记,主要分为两个部分,第一部分从书生·浦语大模型发展、分类、组成进行详细介绍,方便大家理解。第二部分为对 InternLM2技术报告解读,后续系列会继续更新,欢迎大家交流!