目录
一.顺序表与链表的区别
顺序表的问题及思考:
- 中间/头部插入删除,涉及到移动数据,时间复杂度为o(n)
- 增容需要申请新空间,拷贝数据,释放旧空间,会有损耗。(realloc)
- 增容一般呈2倍的增长,当前容量为100,增加到200,只存放5字节,浪费了95字节
- 顺序表中间头部插入效率低下,增容造成运行效率降低
- 链表解决了上述问题
顺序表相关文章链接:顺序表复习(C语言版)
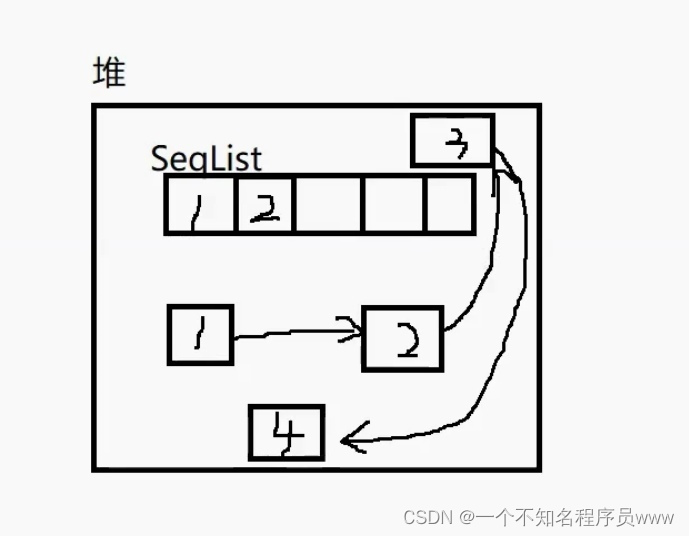
上图就形象地表示了线性表与链表的区别,链表存储位置不连续,是用指针相连;线性表(SeqList)在内存中是连续存放的
二.链表概念
线性表是一类相同元素的集合,例如苹果和香蕉(都是水果)
逻辑结构:一定线性
物理结构:不一定线性(因为在内存中的存放位置是不连续的)
int a =10;float f =0.1 变量a和f的物理空间不一定连续,即存放位置不一定连续
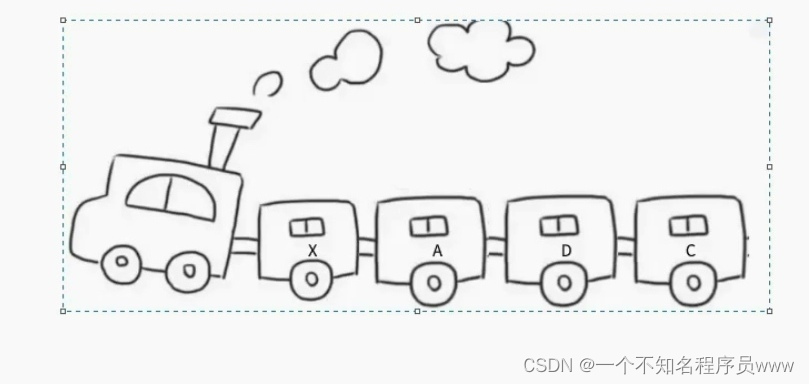
链表和火车很相似
通过一个钩子连在一起,地址空间是链接在一起的,车头也是车厢,因为它也可以装人
旺季:增加车厢
淡季:减少车厢
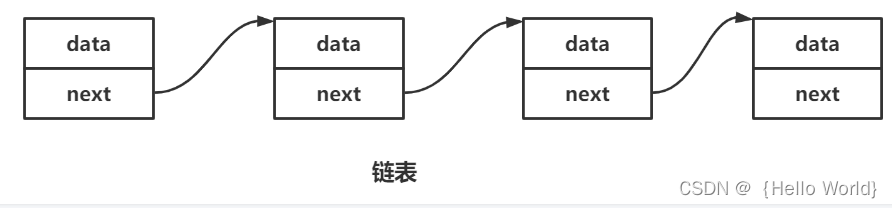
链表是由一个一个节点组成,结点可以看成车厢
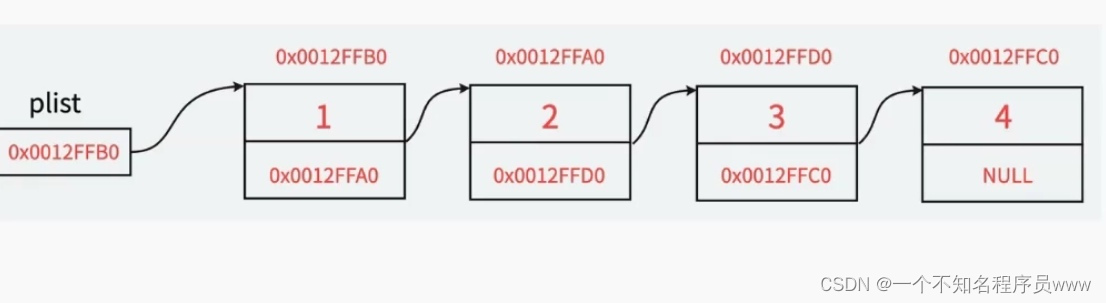
plist位置称之为头结点,头结点指向的结点叫做首元结点,最后一个指针域指向NULL的结点叫做尾元结点
结点和节点:同一个东西,随便用哪个
结点由什么组成的呢?
有两个组成部分
1.数据域 --->在该域内存储了数据
2.指针域 --->存储了指向下一个结点的指针
三.单链表
1.单链表的开始与初始化
链表就是在定义链表的结点结构
struct SListNode single list node
{
int data; //int a =10;//int* pa =&a
struct SListNode* next; //指向下一个节点的指针
}SLTNode;
typedef int SLTTDataType;上述代码就是在对链表进行初始化,定义了一个结构体,并在里面定义了一个data还有一个指针next(next指向下一个结点)
void SListTest01()
{
//创建节点
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));
node1->data = 1;
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
node2->data = 2;
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
node3->data = 3;
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
node4->data = 4;
//将四个节点连接起来
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
//调用链表的打印
SLTNode* plist = node1;
void SLTPrint(plist); //为了让代码逻辑更加清晰
}上述代码依旧是对链表的初始化,将四个结点进行创建,然后相连接;在初始化代码写完以后,直接跟了一个链表打印函数
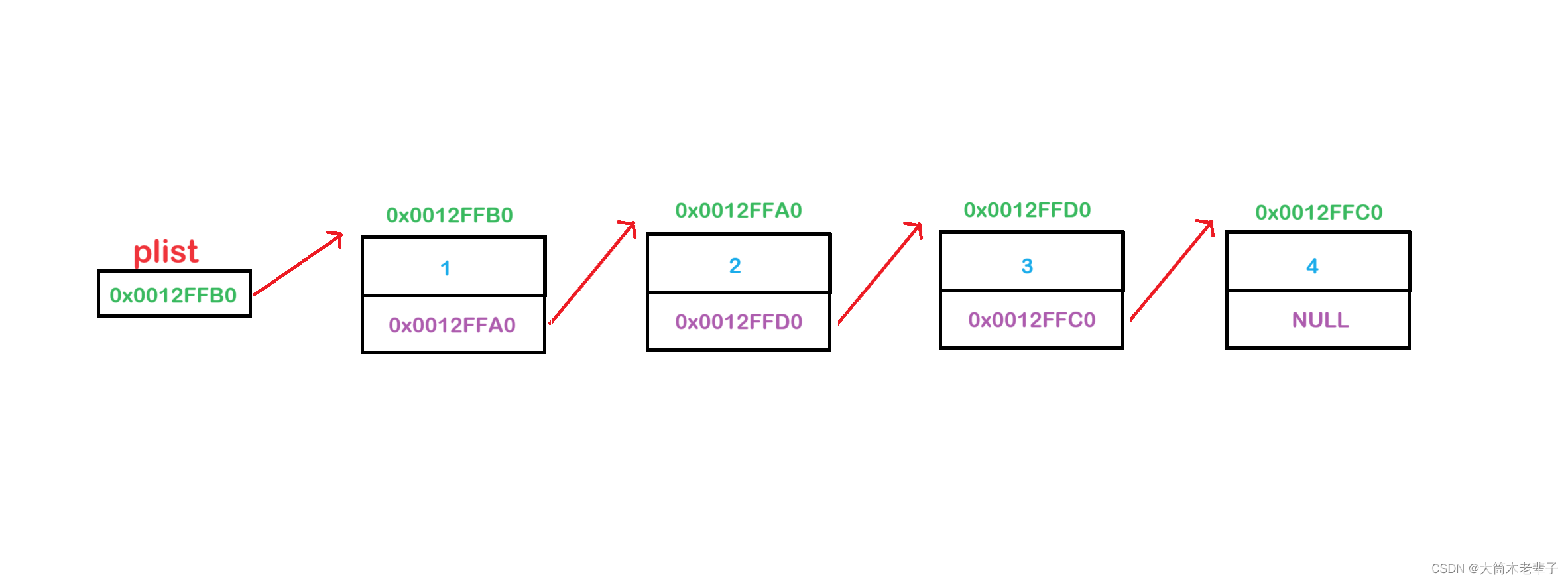
2.单链表的打印
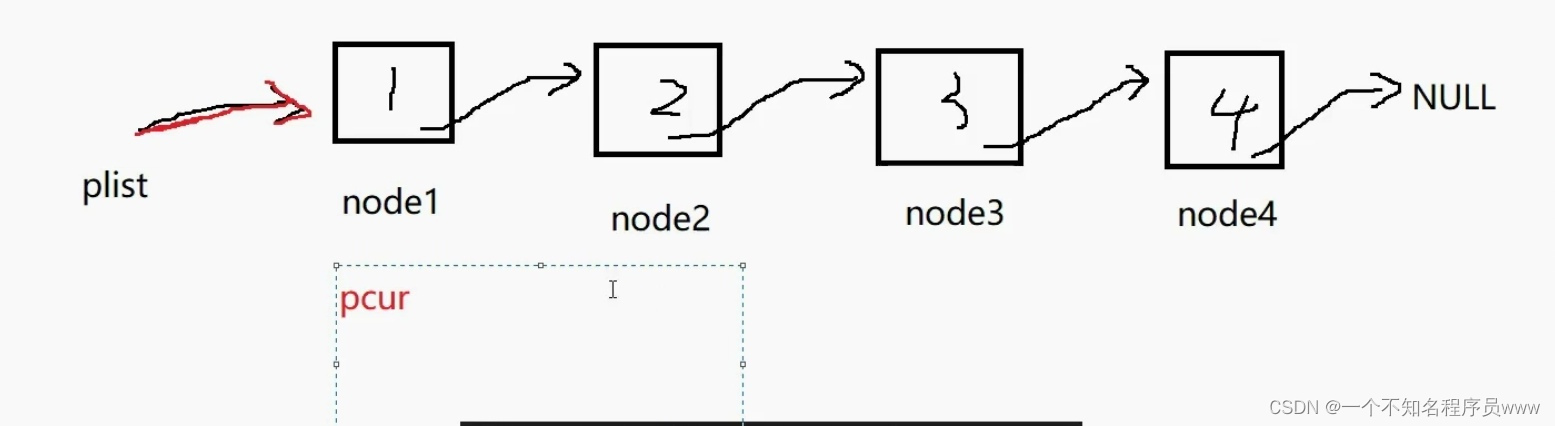
紧接上文代码,上文中 SLTNode* plist = node1就是在说明,plist是个指针,且与node1一样都是一级指针;因此它指向node1所在的这块空间,这就可以看成让node1和plist两个指针指向同一块空间,且这块空间在早些时候已经通过node1指针初始化完毕了;因此如果创建一个pcur,让他等于plist,那么pcur依旧指向node1所指向的空间,这就可以看出三个指针指向同一块空间
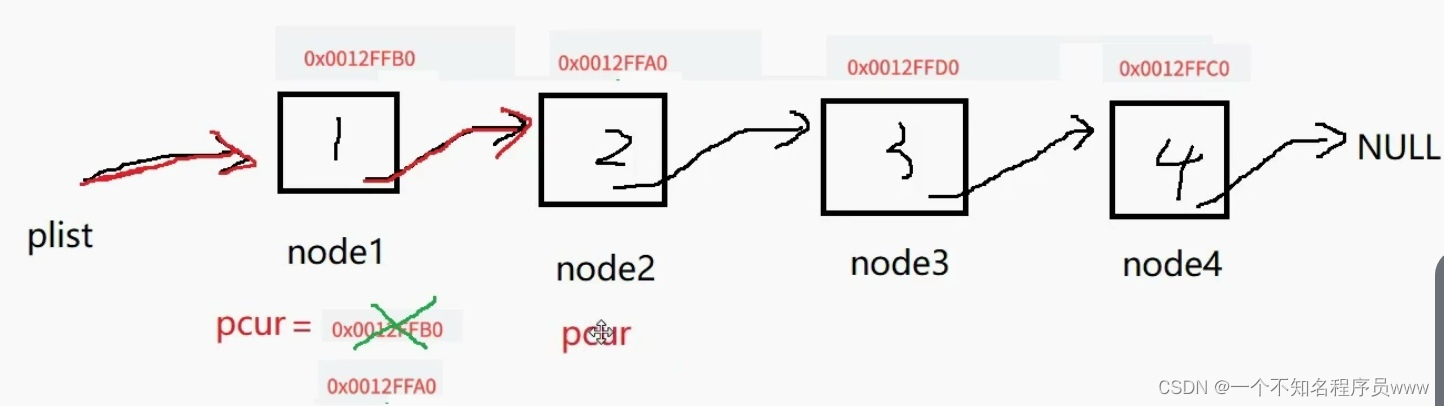
先是打印pcur所指向空间的data,然后让pcur里指向下一个结点的指针覆盖pcur这个结点,pcur就自然而然向后移动了
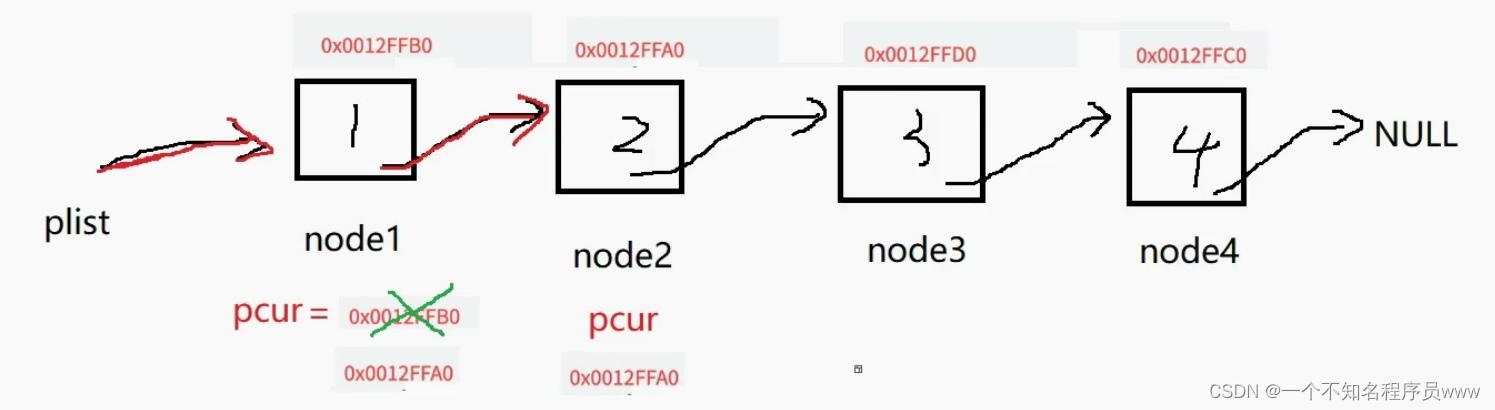
重复上述操作,先打印所指向空间的data值,然后再让其指向的下一个结点地址将现在这个结点地址覆盖
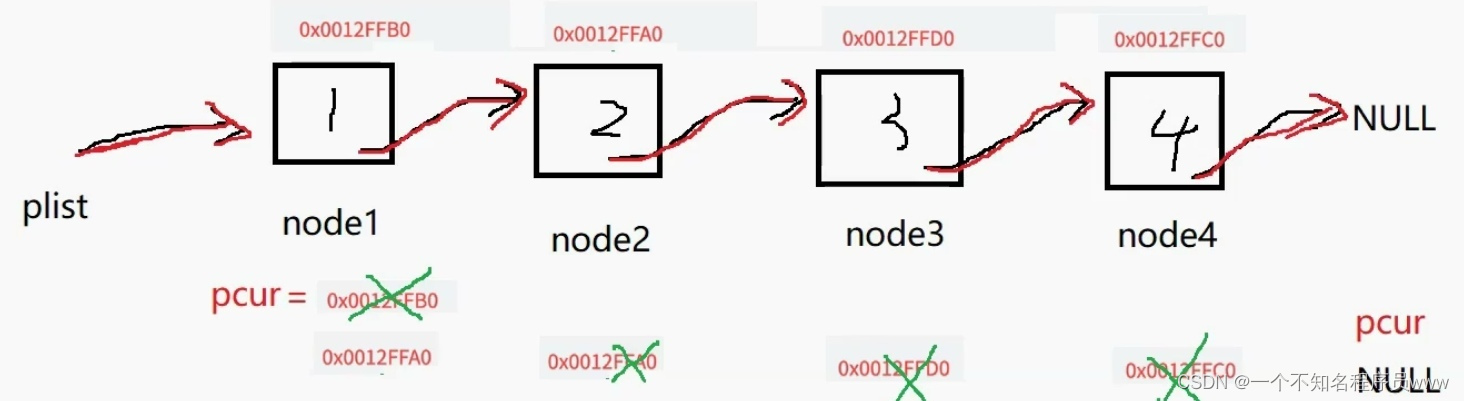
由上图可知,当pcur指向的空间为NULL时,打印操作完成;由上四图,不难得出下述代码:
void SLTPrint(SLTNode* phead) //传的是首元结点
{
SLTNode* pcur = phead;
while (pcur) //pcur != NULL
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
3.单链表的尾插
因为在此以后我们需要多次进行单链表的增删查改操作,因此我们可以专门写一个函数,这个函数是专门用来创建新结点的,在顺序表那篇文章中已经讲解过,故在此省略
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode*));
if (newnode == NULL)
{
perror("malloc fail!");
exit(-1);
}
newnode->data = x;
newnode->next = NULL; //此处指向空指针是为了方便后续操作
}接下来就要开始进行尾插操作
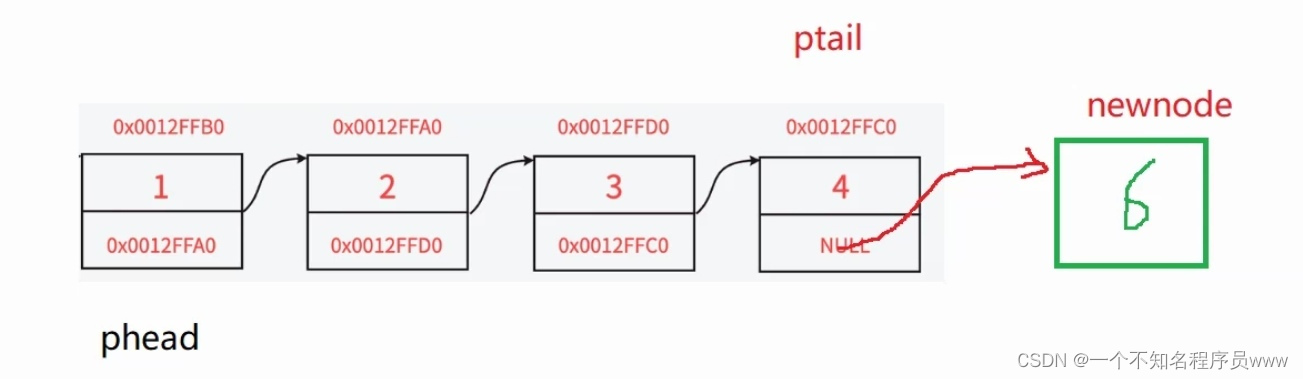
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = SLTBuyNode(x);
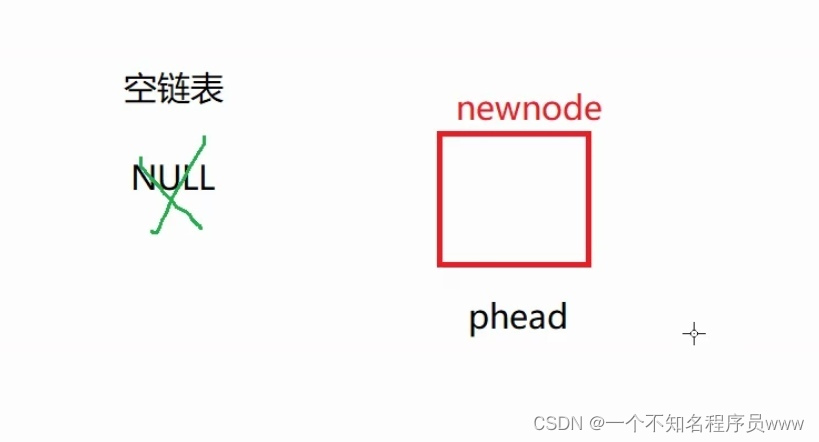
//空链表的情况
if (*pphead == NULL)
{
*pphead = newnode; //newnode的data有了,next指向空指针,将pphead地址覆盖,指向新的newnode空间,完成尾插
}
//非空链表的情况
else
{
//找尾
SLTNode* ptail = *pphead; //不想让*pphead变动位置(变动了就需要使用二级指针了),因此又定义了一个变量ptail指针
while (ptail->next)
{
ptail = ptail->next;
}
//退出循环就说明已经找到尾了,此时ptail指向空指针
ptail->next = newnode; //让ptail指向新结点
}
}上述代码指针部分较难理解,因此笔者将在下文进行详细解释
重难点:单链表实现时的指针详解
上述代码中,为什么使用二级指针?
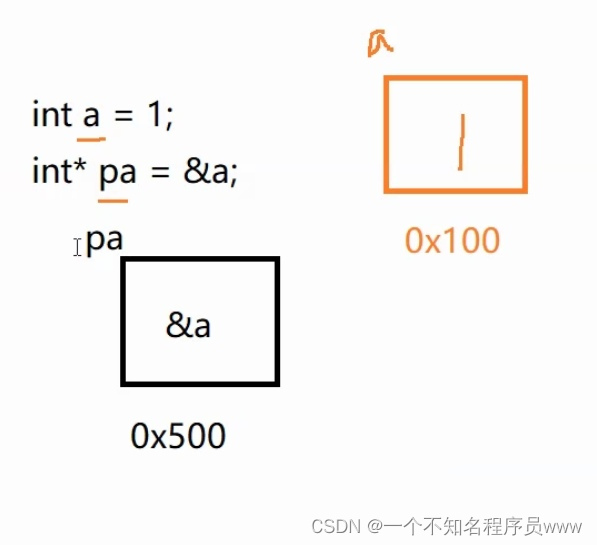
在函数中,想要通过形参改变实参的值(即对其进行某些操作,且这些操作是针对该参数而言的,而不是该参数针对别的变量而言的),就必须在传参时传地址。即使实际参数是一个指针,我们也需要通过指针的地址来改变该指针本身。(如下图所示)
所以,我们在函数传参时,传的是指针的地址,因此需要函数用二级指针来接收。
但请注意,只有二级指针类型的形式参数,在进行了一次解引用操作状态下的改变,才需要用到二级指针类型的形式参数。
此处我们可以类比一级指针和整型变量。要通过形式参数改变实际参数,那么需要形式参数是一个指向需改变变量的指针,然后才可以通过形式参数改变该变量;而想要改变一级指针变量,那么就需要通过二级变量来改变。(前者是结点里的指针域、数据域的内容的改变,后者是结点本身的改变)
所以,如果需要改变结点,就用二级指针;如果只需要改变某个结点指针域、数据域内容,那就传一级指针,此时就没有必要传二级指针了。
上述代码中,为什么有些地方需要解引用,而有些地方不需要呢?
解引用(即*操作符)可以看作是把指针降级(文章链接部分有指针其他内容复习),把二级指针变成一级指针,把一级指针变成指针指向的内容;所以上述代码中,部分地方使用了一次解引用操作,即从指向结点的指针地址变为了指向结点的指针(也可以看成是结点本身)。
为什么单链表的打印不需要二级指针,而单链表的尾插就需要呢?
因为单链表的打印并没有改变链表的首元结点本身,只是完成了打印操作,所以不需要通过形式参数来改变实际参数;而尾插操作需要改变链表的首元结点本身(从NULL变成了newnode),因此需要通过形参来改变实参。
SLTNode* 和 * 的区别是?
SLTNode* 是在告诉编译器,这个变量是个指针,指向了SLTNode这个类型的数据,而并不是在对变量进行解引用操作;*是解引用操作符,在上文已经讲解完毕;而在函数当中,对二级指针进行解引用,其本质上还是个二级指针,因为形式参数依然还是二级指针。
| 实参 | 形参(前面的*是指函数中使用的解引用操作符个数) | |
| 第一个结点的内容 | *plist(即xxx) | ptail -> xxx (即一般情况下的**pphead,此处只是因为是结构体指针,所以需要用结构体指针的解引用方式) |
| 指向第一个结点的指针 | plist | *pphead |
| 指向第一个结点的指针的地址 | &plist | pphead |
SLTNode* plist = NULL; //代码1
SLTNode* plist1 = node1; //代码2
SLTPushBack(&plist1, 1); //代码3
SLTPrint(plist1); //代码4
plist1->next = NULL; //代码5代码1:结点为空
代码2:一个有效结点
代码3:传输有效结点的地址
代码4:传输有效结点
代码5:对有效结点解引用,结构体里套了一个指向结构体类型(即为其本身)的指针变量,让该变量指向空,这一操作即是让该结点的下一个结点为空
4.单链表的头插
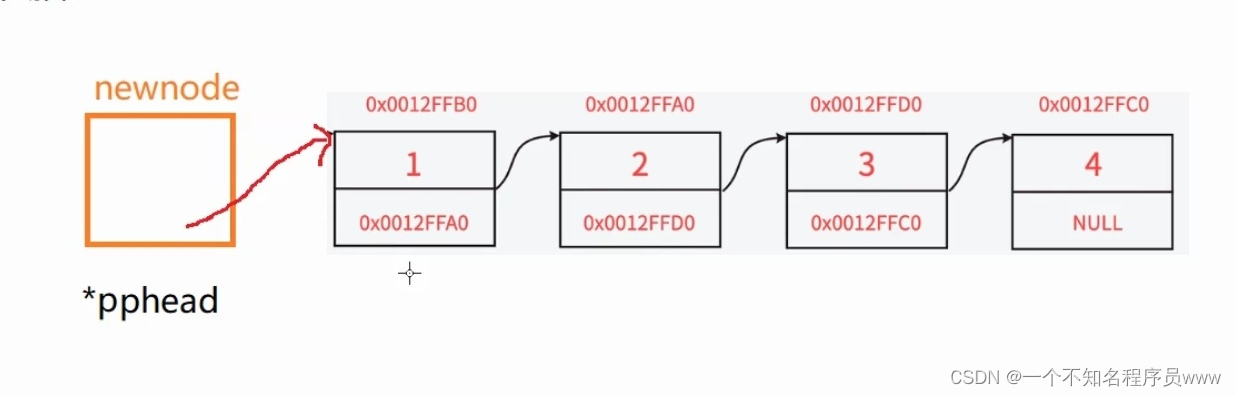
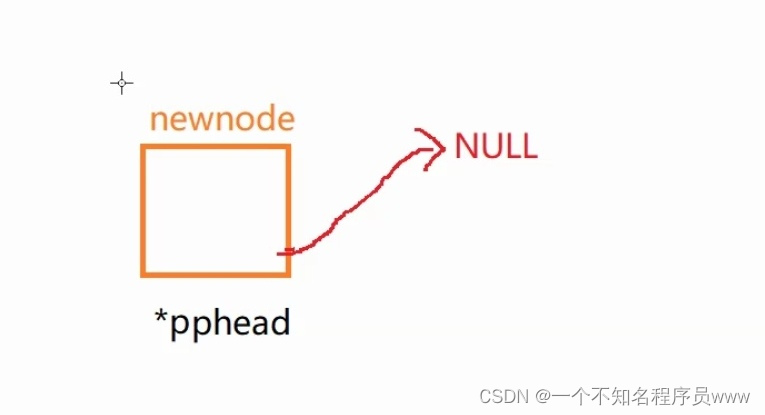
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead; //newnode指向首元结点
*pphead = newnode; //将头指针指向新创建的结点
}
5.单链表的尾删
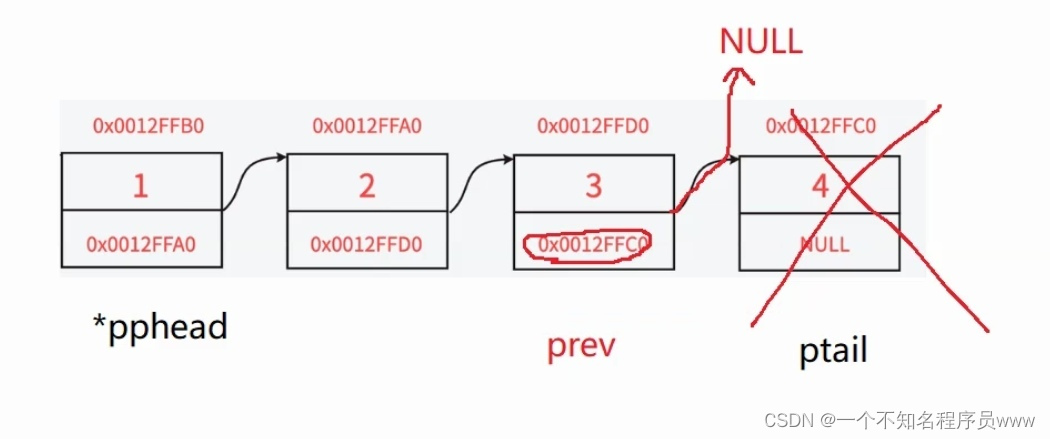
void SLTPopBack(SLTNode** pphead)
{
assert(pphead && *pphead) //指向链表结点的指针不能为空,链表也不能为空
SLTNode* prev = *pphead; //为防止野指针,要让尾元结点的next指针指向空,因此需要再创建一个指针,来完成这一操作
SLTNode* ptail = *pphead;
while (ptail->next)
{
prev = ptail; //prev需要指向尾元结点的前一个结点,因此需要跟着ptail变动
ptail = ptail->next; //ptail指向尾元结点
}
free(ptail); //释放ptail所指向的空间,就能达到尾删的目的
ptail = NULL; //动态内存开辟内容,下文有链接
prev->next = NULL; //要让prev里的next指针从指向野指针到指向空指针
}
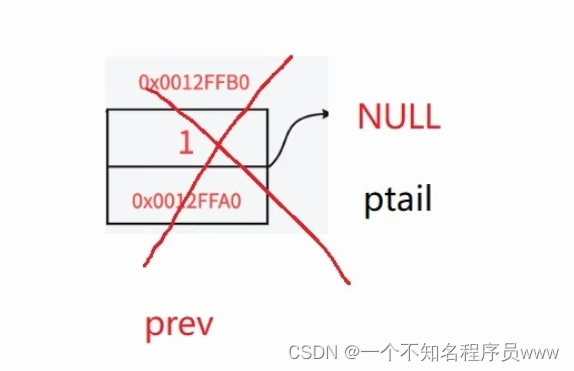
当只有一个结点的时候,循环直接跳过,ptail和prev指向同一个结点,在将ptail空间释放并变成空指针以后,又一次对prev(即ptail的同一结点)进行了解引用操作,这样代码会报错(对空指针解引用)
因此当链表只有一个节点时,代码如下所示:
//链表只有一个结点
if ((*pphead)->next = NULL) //加括号是因为 -> 优先级高于 *
{
free(*pphead);
*pphead = NULL;
}
尾删的全部代码:
void SLTPopBack(SLTNode** pphead)
{
assert(pphead && *pphead) //链表不能为空,指向链表结点的指针也不能为空
//链表只有一个结点
if ((*pphead)->next = NULL) //加括号是因为 -> 优先级高于 *
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = *pphead; //为防止野指针,要让尾元结点的next指针指向空,因此需要再创建一个指针,来完成这一操作
SLTNode* ptail = *pphead;
while (ptail->next)
{
prev = ptail; //prev需要指向尾元结点的前一个结点,因此需要跟着ptail变动
ptail = ptail->next; //ptail指向尾元结点
}
free(ptail); //释放ptail所指向的空间,就能达到尾删的目的
ptail = NULL; //动态内存开辟内容,下文有链接
prev->next = NULL; //要让prev里的next指针从指向野指针到指向空指针
}
}
6.单链表的头删
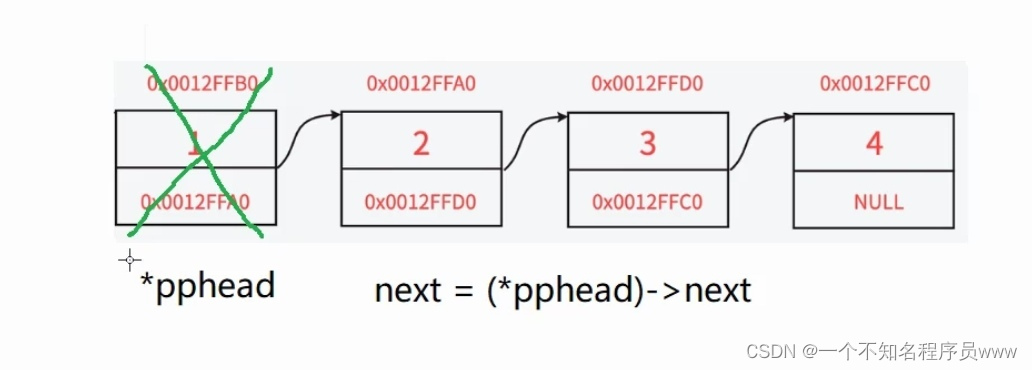
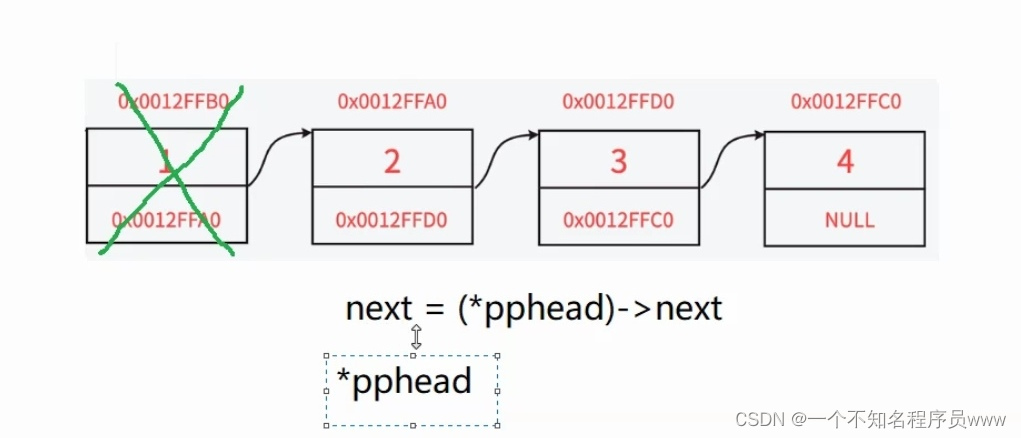
先要保存好头删前的链表第二个节点,头删以后把*pphead指针指向新的节点
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
//只有一个结点的情况上述代码也能够解决小结:
上述的插入、删除代码中,因为四种代码所以必须使用二级指针:
1.free(*pphead);2.*pphead = NULL;
3.*pphead = newnode;
4.*pphead = next;
即对一级指针类型的参数本身进行了某些操作
7.单链表的查找
在使用查找函数以后,要分为找到了和没找到两种情况,那么我们可以通过如下代码来区分(此处的3是指数据域为3的结点):
SLTNode* find = SLTFind(plist, 3);
if (find == NULL)
{
printf("没有找到");
}
else
{
printf("找到了");
}上述代码中,plist即为首元结点的指针
不需要传输首元结点指针的地址,这是因为并不需要通过查找函数来改变链表的首元结点。
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* pcur = phead; //不想形式参数是个二级指针,因此可以在函数中定义一个指针变量
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
8.在指定位置前插入数据
该函数必须要有三个参数,分别是链表的首元结点(SLTNode** pphead)、在链表的哪个结点前插入(SLTNode* pos)、所需要插入的数据(x)。如下所示:
void SLTInsert(SLTNode** pphead,SLTNode* pos,SLTDataType x)一个参数使用二级指针,一个参数使用一级指针的原因:
前一个二级指针类型是链表的首元结点地址,是需要通过形式参数来改变首元结点的;下一个一级指针类型是链表指定位置的结点,可以直接通过解引用,对结点的指针域、数据域进行操作。
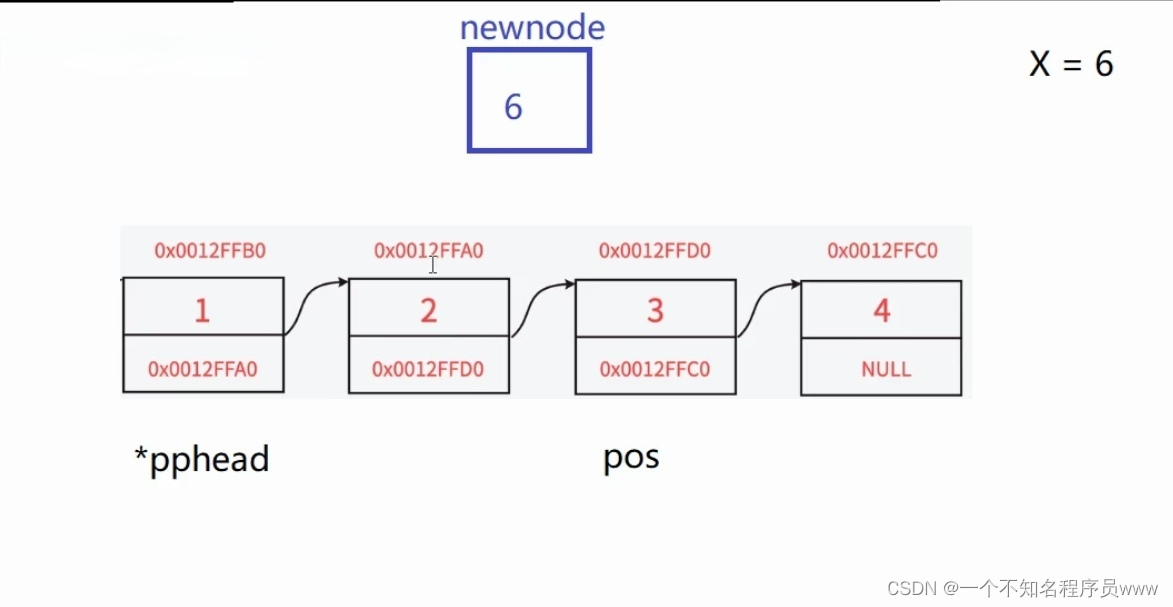
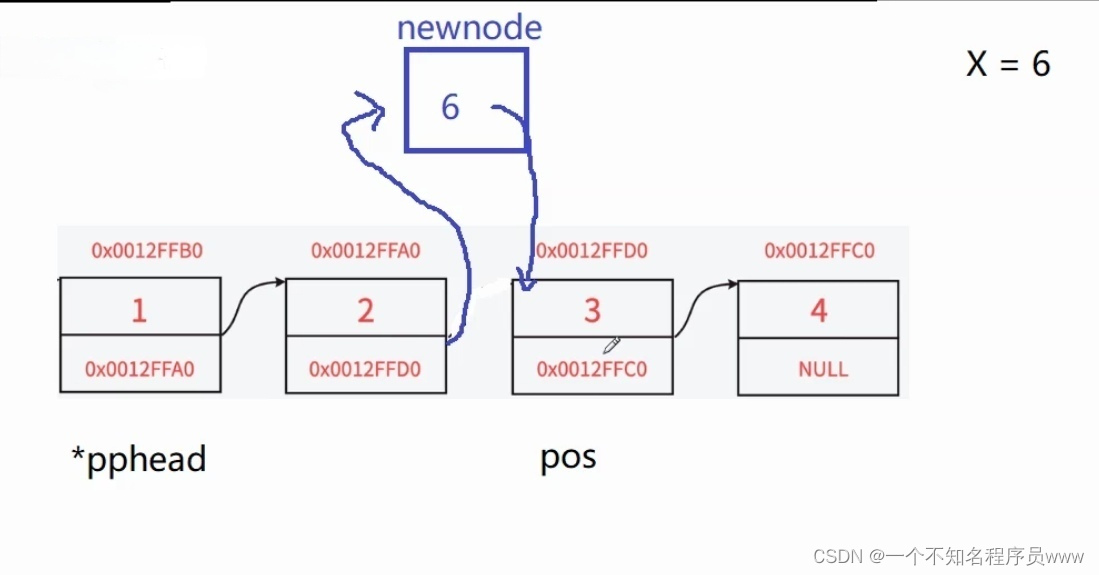
如果要在第3个结点前插入数据,就需要先创建一个结点,然后把这个结点和第3个结点相连接,然后断开第2个结点和第3个结点的连接,让第2个结点和第3个结点相连。而第2个结点就需要通过遍历获得,循环语句的退出条件是:prev->next != pos (prev为函数中定义的指针变量,遍历以前,prev == *pphead)
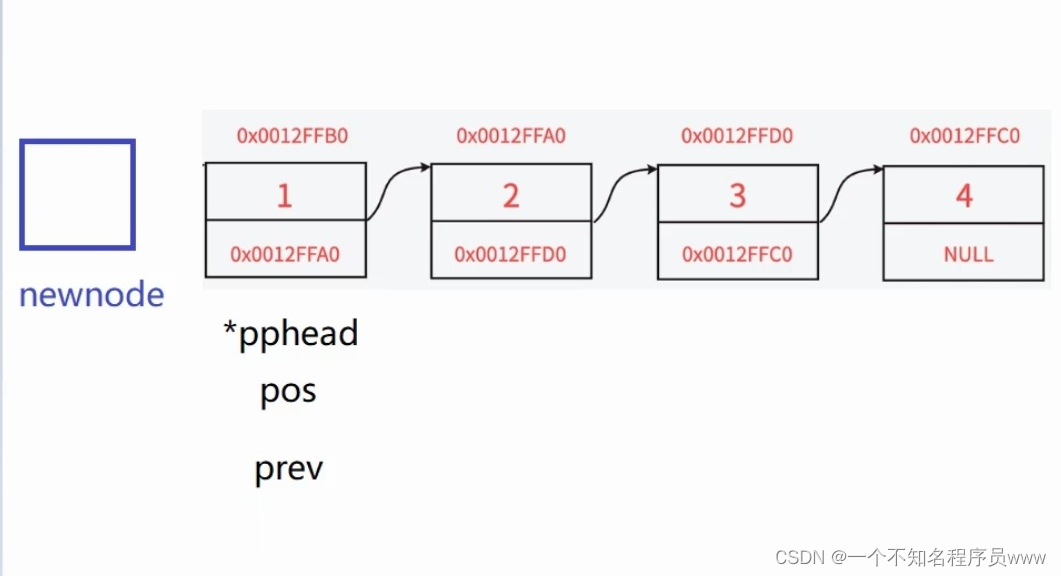
如果是在链表的首元结点之前插入数据,那么prev的next就不可能会等于pos,因此我们在代码实现里要考虑到一般情况和在首元结点之前插入数据两张情况。并且在首元结点前插入数据可以通过头插的函数来实现(这种情况也是函数需要使用二级指针的原因,因为函数需要传一个二级指针)。
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(*pphead && pphead); //链表不能为空,因为为空了,就无法确定“某一位置”了
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
if (pos == *pphead) //在首元结点之前插入
{
SLTPushFront(pphead, x);
}
else //一般情况
{
//找到pos结点的前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next; //没有找到就找下一个
}
newnode->next = pos; //完成上文的操作
prev->next = newnode;
}
}
//pos指针即为上文查找部分出现的find
9.在指定位置后插入数据
在指定位置后插入数据,不需要再创建一个指针,直接通过"指定位置"结点的next以及该结点next的next来插入即可
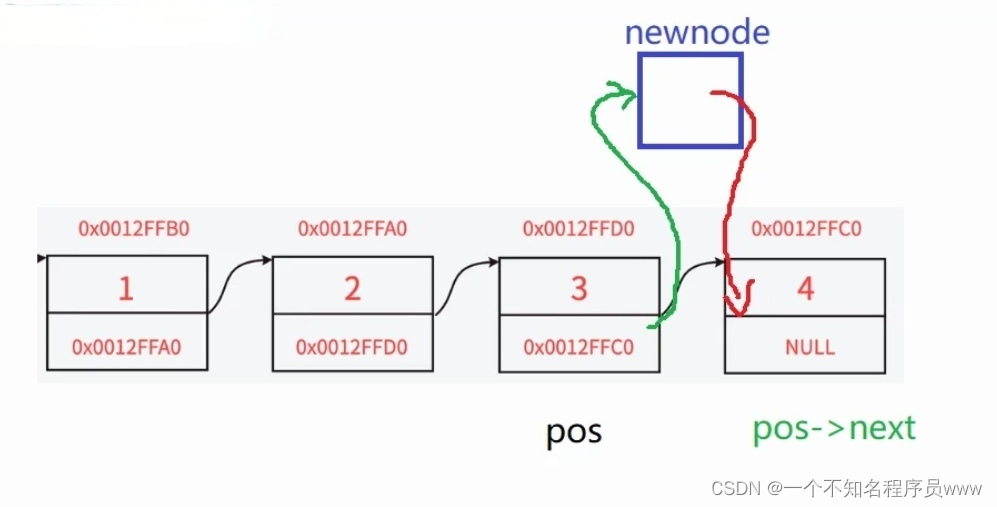
第一种:先红色,再绿色
第二种:先绿色,再红色
以上两种方式是否相同?
//第一种方式的代码
newnode->next = pos->next;
pos->next = newnode;//第二种方式的代码
pos->next = newnode;
newnode->next = pos->next;
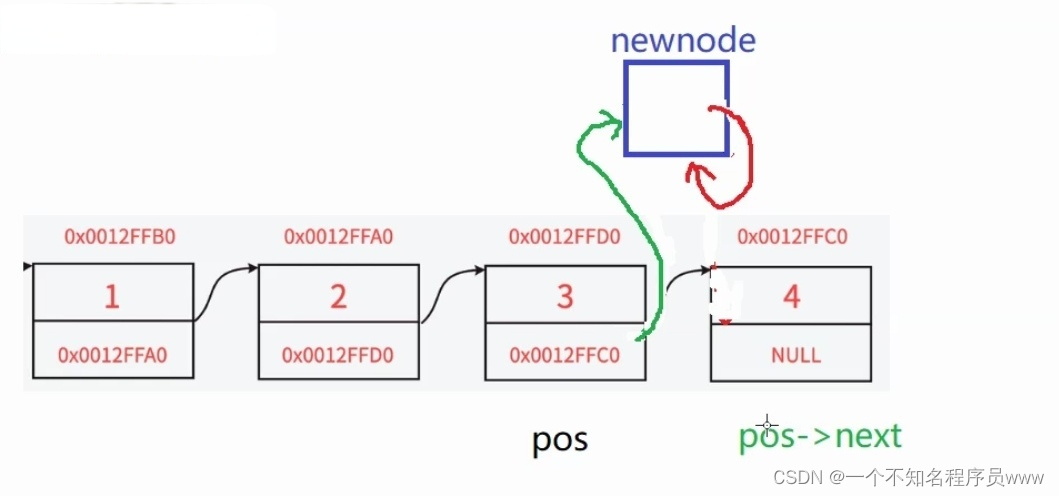
第一种方式可以完成我们需要的操作,即先让新节点指向链表的指定节点的下一个结点(next),然后再让指定节点指向新结点
第二种方式让指定节点指向新节点,此时指定结点的下一个结点即为新节点,因此让新节点指向指定的下一个结点时,即为新节点本身,无法完成需要的操作(如上图所示)
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//pos指针即为上文查找部分出现的find
10.删除pos结点
删除pos结点需要我们将pos结点的前一个结点和pos的后一个结点相接,因此还需要有个prev指针去保存pos结点的前一个结点,如下图所示
首元结点、尾元结点的删除请读者自行判断
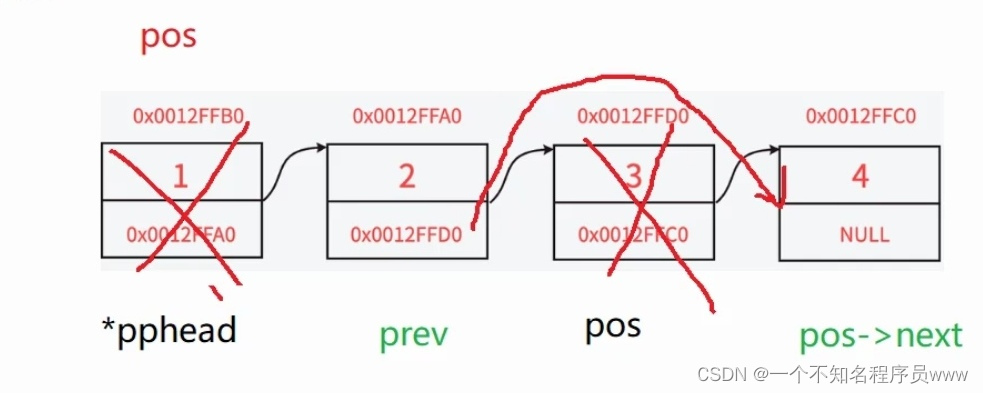
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && *pphead);
assert(pos);
//pos是首元结点
if (pos == *pphead)
{
//头删
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
}
}
//pos指针即为上文查找部分出现的find
//在使用完find指针以后,需要在函数外进行free、置空操作
11.删除pos结点之后的结点
删除pos->next,让pos结点和pos->next->next相连即能完成操作,如下图所示:
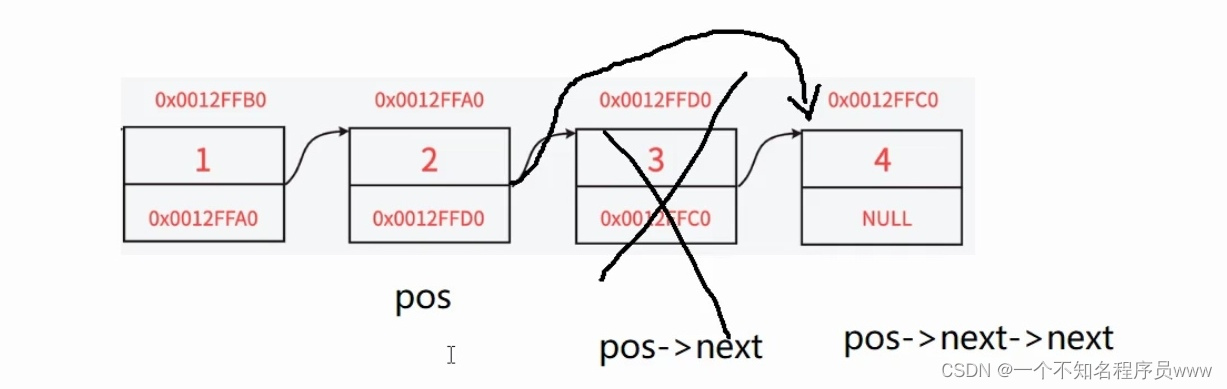
void SLTEraseAfter(SLTNode* pos)
{
assert(pos && pos->next);
SLTNode* del = pos->next; //保存pos的下一个结点
pos->next = del->next; //让pos的下一个结点(即del)和pos的下一个结点(即del)的下一个节点相链接
free(del);
del = NULL;
}
12.删除链表
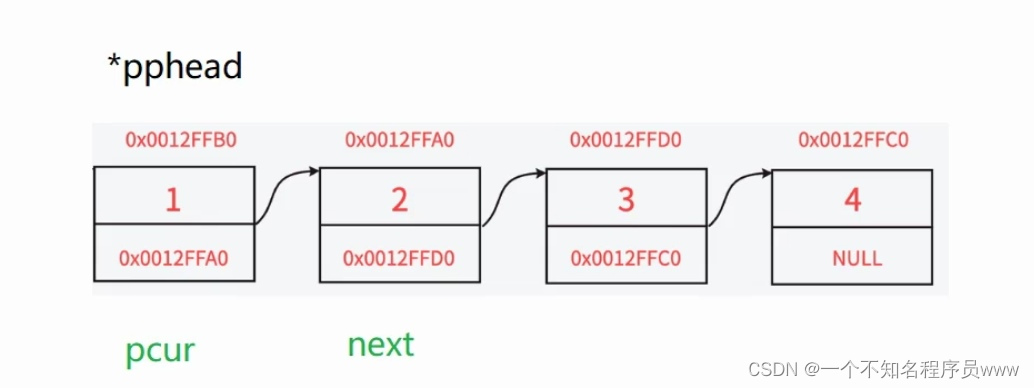
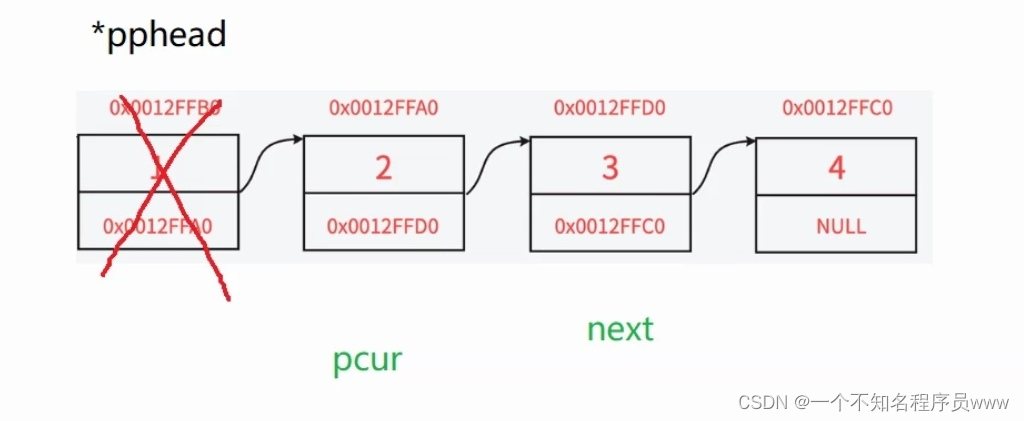
传入首元结点,然后保存好首元结点的下一个结点(next指针),然后free掉pcur以后,让next指针和pcur指针都往后走一个结点,循环退出条件为pcur为空指针。(如上图所示)
void SListDesTroy(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL; //已经释放完所有的内容了,将pphead置为空
}
13.可能存在的疑惑解答
**pphead作为形参出现那么多次,那么他到底对应哪个结点呢?
他既可以对应空指针(链表完全没有结点,对应了插入等的情况),同时也可以对应首元结点(头删和尾删等的情况)
为什么在部分函数里有时候free不需要二级指针?
例如free(ptail),在尾删板块出现。这是因为ptail是在函数里创建、使用的,无需通过函数来改变任何一个实参(它也没有对应的实参、因为它并不是一个形式参数)。在出了函数以后,ptail指针就没有作用了,如果在函数内没有进行free、置空操作,就会变成一个野指针。
单链表的开始和初始化必须要像1那样写吗?
并不是,其实完全可以通过尾插、头插等等方式进行链表的初始化的。所有函数都必须要传二级指针吗?
有些一定需要传,例如*pphead=newnode(在头插板块),因为这条代码如果不写在函数里,就完成不了头插操作;在某些情况下不一定需要传,例如free(*pphead),放到函数实现外的部分,可以通过free(plist)完成操作,不写在函数里也不会影响函数的功能实现。
如果打印函数里使用形参进行打印,不创建变量了,是否可以?
其实是可以的,因为形参是一级指针,不会影响实参。在函数中,定义一个变量pcur = *pphead了以后,为什么影响了pcur就能影响整个链表了?
在函数当中,实际上pcur能直接看成pphead解引用了一次,即可以把所有的pcur看成是(*pphead),这就像是定义宏一样;这就像是传入了一个一级指针 int *a,然后在函数了假设变量int b = *a ,然后通过b的改变来改变传入进来的*a一样。而我们会在函数里使用到pcur = *pphead有两个原因,其一就是为了代码的可读性,其二就是为了让pphead指针一直指向首元结点。
14.全部用于测试的代码
请注意,以下代码有些是不兼容的,就比如plist指针一会是NULL,一会是首元结点;同时有些功能,例如单链表的查找,不能链表是空的,需要有前提条件。因此请读者对函数进行一一尝试,需尝试的功能直接取消注释即可。
int main()
{
//SListTest01(); //对于开始和初始化
//SLTNode* plist = NULL; //从没有链表开始
对于尾插
//SLTPushBack(&plist, 1);
//SLTPrintf(plist); //此处plist又变成了首元结点,在使用完该操作以后,plist由于
//SLTPushBack(&plist, 2);
//SLTPrintf(plist);
//SLTPushBack(&plist, 3);
//SLTPrintf(plist);
//SLTPushBack(&plist, 4);
//SLTPrintf(plist);
对于头插(尾插、头插写一块了)
//SLTPushFront(&plist, 6);
//SLTPrintf(plist);
//SLTPushFront(&plist, 2);
//SLTPrintf(plist);
//SLTPushFront(&plist, 3);
//SLTPrintf(plist);
//SLTPushFront(&plist, 4);
//SLTPrintf(plist);
尾删、头删(先决条件:不为空)
//SLTPopBack(&plist);
//SLTPrint(plist);
//SLTFrontBack(&plist);
//SLTPrint(plist);
查找(先决条件:不为空)
//SLTNode* find = SLTFind(plist, 3);
//if (find == NULL)
//{
// printf("没有找到");
//}
//else
//{
// printf("找到了");
//}
指定位置的插入删除(先决条件:不为空+有具体指定位置)
//SLTNode* find = SLTFind(plist, 3); //find即为具体指定位置
//SLTInsert(&plist, find, 10);
//SLTPrint(plist);
//SLTInsertAfter(find, 10);
//SLTPrint(plist);
//SLTErase(&plist, find);
//SLTPrintf(plist);
//SLTEraseAfter(find);
//SLTPrintf(plist);
//销毁
//SListDesTroy(&plist);
//SLTPrintf(plist);
}
//以上代码是在vscode2022中进行的
四.文章链接
指针讲解:指针复习
动态内存开辟讲解:动态内存开辟复习




























![[图解]企业应用架构模式2024新译本讲解11-领域模型4](https://img-blog.csdnimg.cn/direct/c1af0c61336243618e07696d663d1976.png)


