仁者见仁智者见智,每个程序员的方法都不一样,老的程序员和新的程序员之间的思维差距很大,新入公司的和老员工的代码差距也很大。
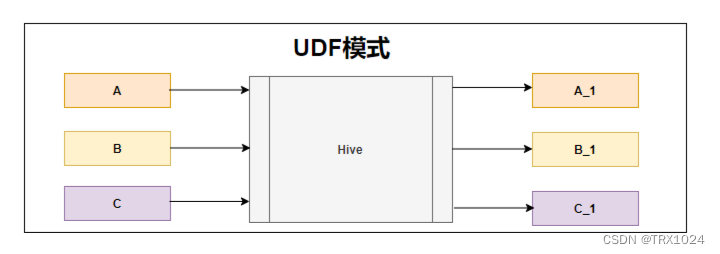
在Apache Hive中,实现全增量统一的用户定义表生成函数(UDTF)、内置函数、聚合、Join等计算引擎常见算子,可以通过编写Hive的UDF(用户定义函数)、UDAF(用户定义聚合函数)、UDTF以及配置Hive的内置功能来完成。以下是java代码实现。
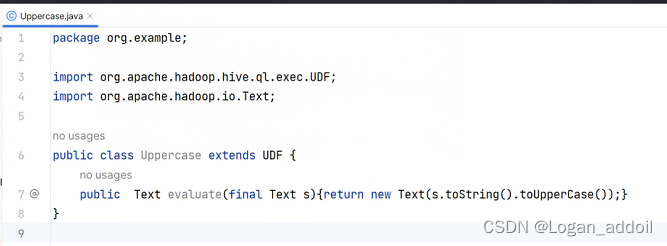
1. 用户定义函数(UDF)
UDF用于对单个输入记录进行处理并返回单个输出值。例如,可以编写一个UDF来实现字符串的反转。
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class ReverseStringUDF extends UDF {
public Text evaluate(Text input) {
if (input == null) {
return null;
}
return new Text(new StringBuilder(input.toString()).reverse().toString());
}
}
编译并将JAR文件添加到Hive中:
ADD JAR /path/to/your/hive-udfs.jar;
CREATE TEMPORARY FUNCTION reverse_string AS 'com.example.hive.udf.ReverseStringUDF';
使用UDF:
SELECT reverse_string(column_name) FROM your_table;
2. 用户定义聚合函数(UDAF)
UDAF用于对一组输入记录进行处理并返回一个单一值。例如,实现一个计算平均值的UDAF。
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class AverageUDAF extends UDAF {
public static class AverageEvaluator implements UDAFEvaluator {
private long count;
private double sum;
public AverageEvaluator() {
init();
}
public void init() {
count = 0;
sum = 0;
}
public boolean iterate(Double value) {
if (value != null) {
count++;
sum += value;
}
return true;
}
public Double terminatePartial() {
return (count == 0) ? null : (sum / count);
}
public boolean merge(Double other) {
if (other != null) {
sum += other;
count++;
}
return true;
}
public Double terminate() {
return (count == 0) ? null : (sum / count);
}
}
}
编译并将JAR文件添加到Hive中:
ADD JAR /path/to/your/hive-udafs.jar;
CREATE TEMPORARY FUNCTION average_udaf AS 'com.example.hive.udaf.AverageUDAF';
使用UDAF
SELECT average_udaf(column_name) FROM your_table;
3. 用户定义表生成函数(UDTF)
UDTF用于将单个输入记录生成多个输出记录。例如,实现一个将逗号分隔的字符串拆分为多行的UDTF。
import org.apache.hadoop.hive.ql.exec.UDTF;
import org.apache.hadoop.io.Text;
public class ExplodeUDTF extends UDTF {
public void process(Object[] args) {
String input = args[0].toString();
String[] parts = input.split(",");
for (String part : parts) {
forward(new Object[]{part});
}
}
public void close() {
}
}
编译并将JAR文件添加到Hive中:
ADD JAR /path/to/your/hive-udtfs.jar;
CREATE TEMPORARY FUNCTION explode_udtf AS 'com.example.hive.udtf.ExplodeUDTF';
使用UDTF:
SELECT explode_udtf(column_name) FROM your_table;
4. Join操作
Hive支持多种Join操作,如Inner Join、Left Join、Right Join、Full Outer Join。以下是一个简单的Join示例:
SELECT a.*, b.*
FROM table_a a
JOIN table_b b ON a.id = b.id;
5. 内置函数与聚合函数
Hive提供了丰富的内置函数和聚合函数,以下是一些常见的内置函数和聚合函数示例:
内置函数
字符串函数:
SELECT CONCAT('Hello', ' ', 'World'), SUBSTR('Hello World', 1, 5), LENGTH('Hello World') FROM your_table;
日期函数
SELECT CURRENT_DATE, YEAR('2024-06-04'), MONTH('2024-06-04') FROM your_table;
数学函数
SELECT ROUND(3.14159, 2), CEIL(3.14159), FLOOR(3.14159) FROM your_table;
聚合函数
SUM、AVG、COUNT:
聚合函数
SUM、AVG、COUNT:
GROUP BY:
SELECT category, SUM(sales) FROM sales_table GROUP BY category;