A u t o f o r m e r Autoformer Autoformer
摘要
我们设计了 A u t o f o r m e r Autoformer Autoformer作为一种新型分解架构,带有自相关机制。我们打破了序列分解的预处理惯例,并将其革新为深度模型的基本内部模块。这种设计使 A u t o f o r m e r Autoformer Autoformer具备了对复杂时间序列的渐进分解能力。进一步地,受随机过程理论的启发,我们基于序列周期性设计了自相关机制,它在子序列级别进行依赖关系的发现和表示聚合。在效率和准确性方面,自相关机制都优于自注意力机制。
1.简介
最近的深度预测模型已经取得了很大的进展,特别是基于变压器的模型。得益于自关注机制,变压器在对序列数据的长期依赖关系建模方面具有很大的优势,这使得更强大的大模型成为可能。我们尝试利用序列的周期性来更新自关注中的点向连接。观察到,周期之间处于相同相位位置的子序列往往呈现相似的时间过程。因此,尝试基于序列周期性导出的过程相似性构建一个序列级连接。
提出了一个原始的自耦器来代替变压器进行长期时间序列预测。自耦器仍然沿用残差和编解码器结构,但将变压器改造为分解预测结构。通过嵌入我们提出的分解块作为内部算子,自耦器器可以逐步从预测的隐藏变量中分离出长期趋势信息。这种设计允许我们的模型在预测过程中交替分解和细化中间结果。受随机过程理论的启发,自耦器引入了自相关机制来代替自关注,该机制基于序列的周期性发现子序列的相似性,并从底层周期中聚合相似的子序列。这种序列智能机制为长度为 L L L的序列实现了 O ( L l o g L ) O(L log L) O(LlogL)复杂度,并通过将逐点表示聚合扩展到子序列级别来打破信息利用瓶颈。自耦器在六个基准上达到了最先进的精度。贡献总结如下:
- 为了解决长期未来复杂的时间模式,我们提出了自耦器作为一个分解架构,并设计了内部分解块,以赋予深度预测模型具有内在的渐进分解能力。
- 我们提出了一种自相关机制,在序列级别上具有依赖性发现和信息聚合。我们的机制超越了以前的自关注家族,可以同时有利于计算效率和信息利用率。
- 在六个基准的长期设定下,自耦器实现了38%的相对改进,涵盖了五个实际应用:能源、交通、经济、天气和疾病。
2.相关工作
- 提出的自相关机制基于时间序列的固有周期性,可以提供序列明智的连接。
- 自耦器利用分解作为深度模型的内部块,可以在整个预测过程中逐步分解隐藏序列,包括过去的序列和预测的中间结果。
3.Autoformer

将 T r a n s f o r m e r Transformer Transformer改造为一个深度分解架构,包括内部的系列分解块、自相关机制以及相应的编码器和解码器。
序列分解模块:
该模块的目的是将输入的时间序列分解为趋势周期部分和季节性部分,以便更好地进行长期预测。由于未来是未知的,因此该模块通过对预测的中间隐藏变量进行处理来提取长期稳定的趋势。具体方法是使用移动平均法,通过填充操作保持序列长度不变。最终,该模块输出分解后的季节性部分和趋势周期部分。
采用移动平均法来平滑周期性波动,并突出长期趋势。对于长度为 L L L的输入序列 X ∈ R L × d X \in \mathbb{R}^{L \times d} X∈RL×d,其过程如下:
X t = AvgPool ( Padding ( X ) ) X s = X − X t 方程一 X_t = \text{AvgPool}(\text{Padding}(X))\\ X_s = X - X_t\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\方程一 Xt=AvgPool(Padding(X))Xs=X−Xt 方程一
其中, X s X_s Xs和 X t ∈ R L × d X_t ∈ \mathbb{R}^{L \times d} Xt∈RL×d分别表示季节性和提取的趋势周期部分。我们采用带有填充操作的 A v g P o o l ( ⋅ ) AvgPool(·) AvgPool(⋅)进行移动平均,以保持序列长度不变。我们用 X s , X t = S e r i e s D e c o m p ( X ) Xs, Xt = SeriesDecomp(X) Xs,Xt=SeriesDecomp(X)来总结上述方程,这是一个模型内部模块。
模型输入
编码器的输入是过去 I I I个时间步的 X e n ∈ R I × d Xen ∈ R^{I×d} Xen∈RI×d。作为一个分解架构, A u t o f o r m e r Autoformer Autoformer解码器的输入包含两部分:季节性部分 X d e s ∈ R ( I / 2 + O ) × d X_{des} ∈ R^{(I/2+O)×d} Xdes∈R(I/2+O)×d和趋势周期部分 X d e t ∈ R ( I / 2 + O ) × d X_{det} ∈ R^{(I/2+O)×d} Xdet∈R(I/2+O)×d,这些部分需要被细化。每个初始化包含两部分:一部分是从编码器输入 X e n X_{en} Xen的后半部分(长度为 I / 2 I/2 I/2)分解得到的组件以提供近期信息,另一部分是长度为 O O O的占位符,用标量填充。具体数学公式如下:
Xens , Xent = SeriesDecomp ( Xen I 2 : I ) Xdes = Concat ( Xens , X 0 ) Xdet = Concat ( Xent , XMean ) 方程二 \begin{align*} \text{Xens}, \text{Xent} &= \text{SeriesDecomp}(\text{Xen}_{\frac{I}{2}:I}) \\ \text{Xdes} &= \text{Concat}(\text{Xens}, \text{X}_0) \\ \text{Xdet} &= \text{Concat}(\text{Xent}, \text{XMean}) \end{align*}\ \ \ \ \ \ \ \ \ \ \ \ \ 方程二 Xens,XentXdesXdet=SeriesDecomp(Xen2I:I)=Concat(Xens,X0)=Concat(Xent,XMean) 方程二
其中, X e n s , X e n t ∈ R I / 2 × d X_{ens}, X_{ent} ∈ R^{I/2×d} Xens,Xent∈RI/2×d分别表示 X e n X_{en} Xen的季节性和趋势周期部分,而 X 0 , X M e a n ∈ R O × d X_0, X_{Mean} ∈ R^{O×d} X0,XMean∈RO×d分别表示用零填充的占位符和 X e n X_{en} Xen的均值。
编码器
编码器专注于季节性部分的建模。编码器的输出包含过去的季节性信息,并将作为交叉信息来帮助解码器细化预测结果。假设我们有 N N N个编码器层。第 l l l个编码器层的整体方程可以总结为 X l en = Encoder ( X l − 1 en ) X_l^{\text{en}} = \text{Encoder}(X_{l-1}^{\text{en}}) Xlen=Encoder(Xl−1en)。具体细节如下:
S e n l , 1 , ‾ = S e r i e s D e c o m p ( A u t o − C o r r e l a t i o n ( X e n l − 1 ) + X e n l − 1 ) S e n l , 2 , ‾ = S e r i e s D e c o m p ( F e e d F o r w a r d ( S e n l , 1 ) + S e n l , 1 ) 方程三 S_{en}^{l,1},\underline{}=SeriesDecomp(Auto-Correlation(X_{en}^{l-1})+X_{en}^{l-1})\\S_{en}^{l,2},\underline{}=SeriesDecomp(FeedForward(S_{en}^{l,1})+S_{en}^{l,1}) \ \ \ \ \ 方程三 Senl,1,=SeriesDecomp(Auto−Correlation(Xenl−1)+Xenl−1)Senl,2,=SeriesDecomp(FeedForward(Senl,1)+Senl,1) 方程三
其中, ′ ‾ ′ '\underline\ \ ' ′ ′表示被消除的趋势部分。 X e n l X_{en}^l Xenl是第 l l l个编码器层的输出, X e n 0 X_{en}^0 Xen0是 X e n X_{en} Xen的嵌入表示。 S e n l , i , i ∈ { 1 , 2 } S_{en}^{l,i},i∈\{1,2\} Senl,i,i∈{1,2},分别表示第 l l l层中第 i i i个序列分解块之后的季节性组件。我们将在下一节中详细描述 A u t o − C o r r e l a t i o n ( ⋅ ) Auto-Correlation(·) Auto−Correlation(⋅),它可以无缝地替代自注意力机制。
解码器
解码器包含两个部分:用于趋势周期分量的累积结构,以及用于季节组分的堆叠自相关机制。每个解码器层都包含内部自相关和编码器-解码器自相关,这可以分别细化预测并利用过去的季节信息。模型在解码过程中从中间的隐藏变量中提取潜在趋势,允许 A u t o f o r m e r Autoformer Autoformer逐步细化趋势预测,并消除在自相关中发现基于周期的依赖关系时的干扰信息。假设有 M M M个解码器层。利用来自编码器的潜变量 X e n N X_{en}^N XenN,第 l l l个解码器层的方程可以总结为 X d e l = D e c o d e r ( X d e l − 1 , X e n N ) X_{de}^l=Decoder(X_{de}^{l-1},X_{en}^N) Xdel=Decoder(Xdel−1,XenN)。解码器可以形式化如下:
S l , 1 d e , T l , 1 d e = SeriesDecomp (Auto-Correlation ( X l − 1 d e ) + X l − 1 d e ) S l , 2 d e , T l , 2 d e = SeriesDecomp (Auto-Correlation ( S l , 1 d e , X N e n ) + S l , 1 d e ) S l , 3 d e , T l , 3 d e = SeriesDecomp (FeedForward ( S l , 2 d e ) + S l , 2 d e ) T l d e = T l − 1 d e + W l , 1 ∗ T l , 1 d e + W l , 2 ∗ T l , 2 d e + W l , 3 ∗ T l , 3 d e 方程四 \begin{align*} S_{l,1}^{de}, T_{l,1}^{de} &= \text{SeriesDecomp (Auto-Correlation}(X_{l-1}^{de})+X_{l-1}^{de}) \\ S_{l,2}^{de}, T_{l,2}^{de} &= \text{SeriesDecomp (Auto-Correlation}(S_{l,1}^{de},X_N^{en})+S_{l,1}^{de}) \\ S_{l,3}^{de}, T_{l,3}^{de} &= \text{SeriesDecomp (FeedForward}(S_{l,2}^{de})+S_{l,2}^{de}) \\ T_{l}^{de} &= T_{l-1}^{de} + W_{l,1} \ast T_{l,1}^{de}+ W_{l,2} \ast T_{l,2}^{de}+W_{l,3} \ast T_{l,3}^{de} \\ \end{align*}\ \ \ \ \ \ \ \ \ 方程四 Sl,1de,Tl,1deSl,2de,Tl,2deSl,3de,Tl,3deTlde=SeriesDecomp (Auto-Correlation(Xl−1de)+Xl−1de)=SeriesDecomp (Auto-Correlation(Sl,1de,XNen)+Sl,1de)=SeriesDecomp (FeedForward(Sl,2de)+Sl,2de)=Tl−1de+Wl,1∗Tl,1de+Wl,2∗Tl,2de+Wl,3∗Tl,3de 方程四
其中, X d e l = S d e l , 3 , l ∈ { 1 , . . . , M } X_{de}^l=S_{de}^{l,3},l\in\{1,...,M\} Xdel=Sdel,3,l∈{1,...,M}表示第 l l l层解码器的输出。 X 0 d e X_0^{de} X0de 是从 X d e s X_{des} Xdes 中嵌入的,用于深度变换,而 T 0 d e = X d e t T_0^{de} = X_{det} T0de=Xdet 用于累积。 S l , i d e S_{l,i}^{de} Sl,ide 和 T l , i d e T_{l,i}^{de} Tl,ide,其中 i ∈ { 1 , 2 , 3 } i ∈ \{1, 2, 3\} i∈{1,2,3},分别表示在第 l l l 层中经过第 i i i 个序列分解块后的季节组分和趋势-周期组分。 W l , i W_{l,i} Wl,i,其中 i ∈ { 1 , 2 , 3 } i ∈ \{1, 2, 3\} i∈{1,2,3},表示第 i i i 个提取的趋势 T l , i d e T_{l,i}^{de} Tl,ide 的投影器。
最终的预测是这两个细化后的分解组分的和,即 W S ∗ X M d e + T M d e W_S * X_M^{de} + T_M^{de} WS∗XMde+TMde,其中 W S W_S WS 是将深度变换后的季节组分 X M d e X_M^{de} XMde 投影到目标维度的投影器。
自相关机制

提出了具有序列间连接的自相关机制,以扩大信息利用率。自相关机制通过计算序列的自相关来发现基于周期的依赖关系,并通过时间延迟聚合来聚合相似的子序列。
基于周期的依赖关系,观察到在周期中的相同相位位置自然提供了相似的子过程。受随机过程理论的启发,对于一个真实的离散时间过程 { X t } \{X_t\} {Xt},我们可以通过以下方程得到自相关 R X X ( τ ) R_{XX}(τ) RXX(τ):
R X X ( τ ) = lim L → ∞ 1 L ∑ t = 1 L X t X t − τ 方程五 R_{XX}(\tau) = \lim_{L \to \infty} \frac{1}{L} \sum_{t=1}^{L} X_t X_{t-\tau}\\ 方程五 RXX(τ)=L→∞limL1t=1∑LXtXt−τ方程五
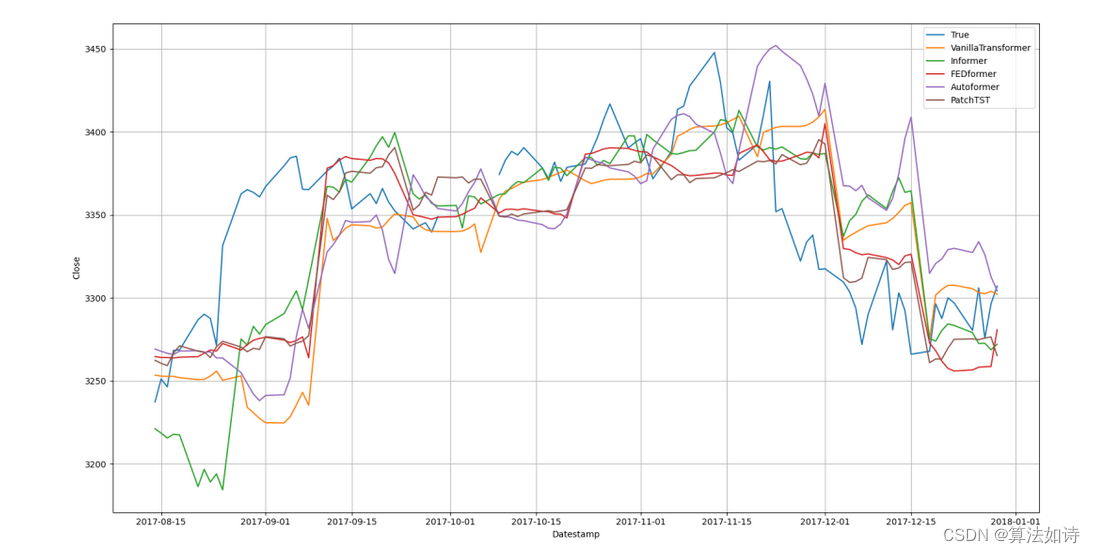
R X X ( τ ) R_{XX}(τ) RXX(τ)反映了 { X t } \{X_t\} {Xt}与其延迟 τ τ τ的序列 { X t − τ } \{X_{t−τ}\} {Xt−τ}之间的时间延迟相似性。如图所示,我们使用自相关 R ( τ ) R(τ) R(τ)作为估计周期长度τ的非标准化置信度。然后,我们选择最可能的 k k k个周期长度 τ 1 , … , τ k τ_1,…,τ_k τ1,…,τk。基于上述估计的周期,可以推导出基于周期的依赖关系,并可以通过相应的自相关进行加权。
时间延迟聚合 基于周期的依赖关系连接了估计周期内的子序列。因此,我们提出了时间延迟聚合模块,该模块可以根据选定的时间延迟 τ 1 , … , τ k τ_1,…,τ_k τ1,…,τk滚动序列。这种操作可以将处于估计周期相同相位位置的相似子序列对齐,这与自注意力家族中的逐点点积聚合不同。最后,我们通过 s o f t m a x softmax softmax归一化的置信度聚合子序列。对于单头情况和长度为 L L L的时间序列 X X X,经过投影器后,我们得到查询 Q Q Q、键 K K K和值 V V V。因此,它可以无缝地替代自注意力。自相关机制如下:
τ 1 , … , τ k = arg Top k { R Q , K ( τ ) } R ^ Q , K ( τ 1 ) , … , R ^ Q , K ( τ k ) = SoftMax ( R Q , K ( τ 1 ) , … , R Q , K ( τ k ) ) Auto-Correlation ( Q , K , V ) = ∑ i = 1 k Roll ( V , τ i ) ⋅ R ^ Q , K ( τ i ) 方程六 \tau_1, \ldots, \tau_k = \text{arg Top}_k \left\{ R_{Q, K}(\tau) \right\} \\ \widehat{R}_{Q, K}(\tau_1), \ldots, \widehat{R}_{Q, K}(\tau_k) = \text{SoftMax} \left( R_{Q, K}(\tau_1), \ldots, R_{Q, K}(\tau_k) \right) \\ \text{Auto-Correlation}(Q, K, V) = \sum_{i=1}^{k} \text{Roll}(V, \tau_i) \cdot \widehat{R}_{Q, K}(\tau_i)\\方程六 τ1,…,τk=arg Topk{RQ,K(τ)}R
Q,K(τ1),…,R
Q,K(τk)=SoftMax(RQ,K(τ1),…,RQ,K(τk))Auto-Correlation(Q,K,V)=i=1∑kRoll(V,τi)⋅R
Q,K(τi)方程六
其中 a r g T o p k ( ⋅ ) arg\ Topk(⋅) arg Topk(⋅)是获取 T o p k Topk Topk个自相关值的参数,并令$k=\lfloor c×logL \rfloor , , ,c 是一个超参数。 是一个超参数。 是一个超参数。R_{Q,K} 是序列 是序列 是序列Q 和 和 和K 之间的自相关。 之间的自相关。 之间的自相关。Roll(X,τ) 表示对 ∗ X ∗ 进行时间延迟 表示对*X*进行时间延迟 表示对∗X∗进行时间延迟τ 的操作,其中超出第一个位置的元素将被重新引入到最后的位置。对于编码器 − 解码器自相关, 的操作,其中超出第一个位置的元素将被重新引入到最后的位置。对于编码器-解码器自相关, 的操作,其中超出第一个位置的元素将被重新引入到最后的位置。对于编码器−解码器自相关,K 、 、 、V 来自编码器 来自编码器 来自编码器X_{en}^N 并会被调整为长度 并会被调整为长度 并会被调整为长度O ,而 ,而 ,而Q 来自解码器的前一个块。对于 来自解码器的前一个块。对于 来自解码器的前一个块。对于Autoformer 中使用的多头版本,具有 中使用的多头版本,具有 中使用的多头版本,具有d_{model} 个通道和 个通道和 个通道和h 个头的隐藏变量,第 个头的隐藏变量,第 个头的隐藏变量,第i 个头的查询、键和值是 个头的查询、键和值是 个头的查询、键和值是Q_i,K_i,V_i\in \mathbb{R}^{L\times \frac{d_{model}}{h}},i\in{1,…,h}$,。其过程如下:
MultiHead ( Q , K , V ) = W output × Concat ( head 1 , … , head h ) where head i = Auto-Correlation ( Q i , K i , V i ) 方程七 \text{MultiHead}(Q, K, V) = W_{\text{output}} \times \text{Concat}(\text{head}_1, \ldots, \text{head}_h) \\ \text{where } \text{head}_i = \text{Auto-Correlation}(Q_i, K_i, V_i)\\方程七 MultiHead(Q,K,V)=Woutput×Concat(head1,…,headh)where headi=Auto-Correlation(Qi,Ki,Vi)方程七
高效计算:对于基于周期的依赖关系,这些依赖关系指向底层周期中相同相位位置的子过程,并且本质上是稀疏的。在这里,我们选择最可能的延迟来避免选择相反的相位。由于我们聚合了 O ( l o g L ) O(log L) O(logL)个长度为 L L L的序列,因此方程 6 6 6和 7 7 7的复杂度为 O ( L l o g L ) O(Llog L) O(LlogL)。对于自相关计算(方程 5 5 5),给定时间序列 { X t } , R X X ( τ ) \{X_t\},R_{X X} (τ) {Xt},RXX(τ)可以通过基于维纳-辛钦定理的快速傅里叶变换( F F T FFT FFT)来计算:
S X X ( f ) = F ( X t ) F ∗ ( X t ) = ∫ − ∞ ∞ X t e − i 2 π t f d t ⋅ ∫ − ∞ ∞ X t e − i 2 π t f d t ‾ R X X ( τ ) = F − 1 ( S X X ( f ) ) = ∫ − ∞ ∞ S X X ( f ) e i 2 π f τ , d f 方程八 \begin{align*} S_{XX}(f) &=F(X_t) F^*(X_t) = \int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt \cdot \overline{\int_{-\infty}^{\infty} X_t e^{-i2\pi tf} dt}^ \ \\R_{XX}(\tau) &= F^{-1}(S_{XX}(f)) = \int_{-\infty}^{\infty} S_{XX}(f) e^{i2\pi f\tau} , df \end{align*}方程八 SXX(f)RXX(τ)=F(Xt)F∗(Xt)=∫−∞∞Xte−i2πtfdt⋅∫−∞∞Xte−i2πtfdt =F−1(SXX(f))=∫−∞∞SXX(f)ei2πfτ,df方程八
其中 τ ∈ { 1 , . . . , L } τ ∈ \{1, ..., L\} τ∈{1,...,L}, F F F表示 F F T FFT FFT, F − 1 F^{-1} F−1是其逆变换。 ∗ * ∗表示共轭操作, S X X ( f ) S_{X X} (f) SXX(f)是频域中的。请注意,通过 F F T FFT FFT可以一次性计算 { 1 , . . . , L } \{1, ..., L\} {1,...,L}中所有延迟的序列自相关。因此,自相关计算达到了 O ( L l o g L ) O(Llog L) O(LlogL)的复杂度。
自相关与自注意族
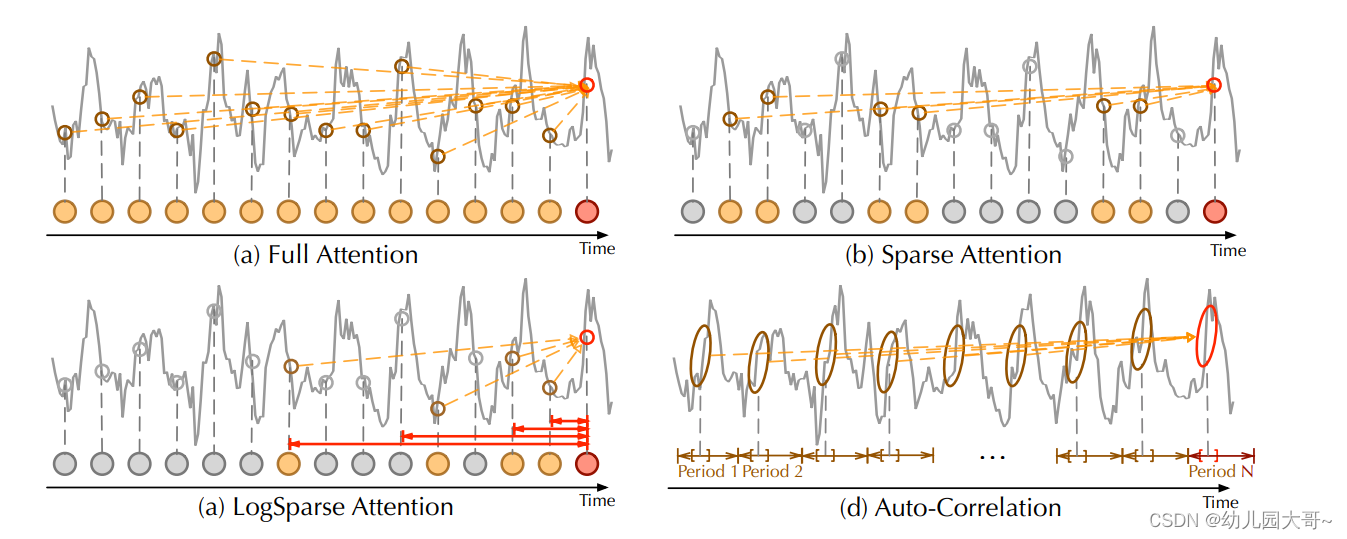
与逐点自注意力族不同,自相关展示了序列之间的连接(如图所示)。具体来说,对于时间依赖性,我们基于周期性来查找子序列之间的依赖关系。相比之下,自注意力族仅计算分散点之间的关系。尽管一些自注意力机制考虑了局部信息,但它们仅利用这些信息来帮助发现逐点依赖关系。对于信息聚合,我们采用时间延迟块来聚合来自底层周期中的相似子序列。相反,自注意力通过点积来聚合选定的点。得益于固有的稀疏性和子序列级别的表示聚合,自相关可以同时提高计算效率和信息利用率。