文章目录
一、Transformer原理
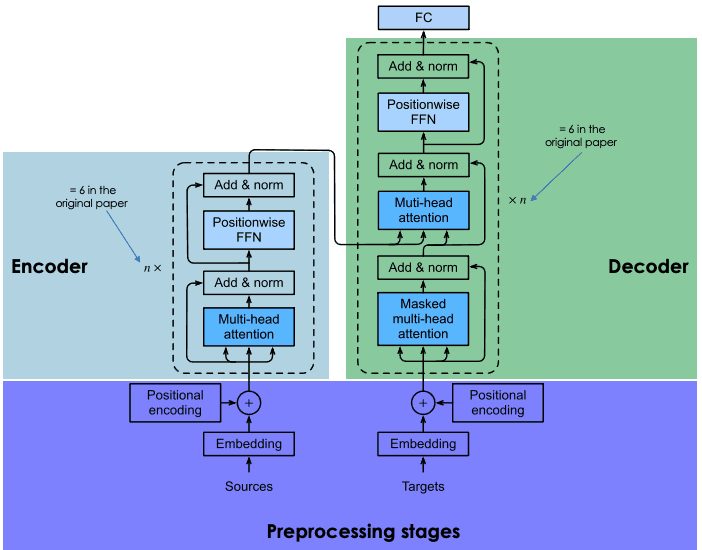
Transformer是一种基于注意力机制(Attention Mechanism)的深度学习模型架构,最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。Transformer主要用于处理序列数据,如自然语言处理(NLP)任务。
Transformer的核心原理包括以下几个关键点:
注意力机制(Attention Mechanism):
- 自注意力(Self-Attention):在序列中的每个位置计算一个加权和,这个和是序列中所有位置的表示。自注意力允许模型在计算每个位置的表示时考虑整个序列的信息。
- 多头注意力(Multi-Head Attention):通过并行的多个注意力头,模型能够捕捉到不同的特征子空间的信息。每个头独立计算注意力并进行合并,使得模型能够处理更复杂的模式。
位置编码(Positional Encoding):
- 因为Transformer模型本身不包含任何顺序信息(不像RNN那样依赖于序列的顺序处理),所以需要通过位置编码将位置信息引入到模型中。这些编码被加到输入的嵌入向量中,帮助模型理解序列中每个位置的相对或绝对位置。
编码器-解码器结构(Encoder-Decoder Architecture):
- 编码器(Encoder):由多个相同的层(Layer)堆叠而成,每一层包括一个多头自注意力机制和一个前馈神经网络(Feedforward
Neural Network)。 - 解码器(Decoder):与编码器结构相似,但每一层多了一个对编码器输出的注意力机制,帮助解码器在生成序列时参考编码器的输出。
- 编码器(Encoder):由多个相同的层(Layer)堆叠而成,每一层包括一个多头自注意力机制和一个前馈神经网络(Feedforward
前馈神经网络(Feedforward Neural Network):
每个编码器和解码器层都包含一个位置逐点的前馈神经网络。这个网络通常包括两个线性变换和一个非线性激活函数。
残差连接(Residual Connection)和层归一化(Layer Normalization):
为了加速训练并稳定梯度,每个子层(包括多头注意力和前馈神经网络)都采用了残差连接,并在其输出后进行层归一化。
Transformer模型的优点包括:
- 并行化处理:相比于RNN,Transformer不需要顺序处理,因此可以更好地利用GPU进行并行化计算。
- 捕捉长距离依赖:通过注意力机制,Transformer能够更好地捕捉序列中远距离的位置之间的依赖关系。
这些特性使得Transformer在许多自然语言处理任务中取得了显著的效果,比如机器翻译、文本生成、文本分类等。
二、Bert的原理
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练模型,旨在生成丰富的、上下文相关的词嵌入(word embeddings)。它是由Google AI团队于2018年提出的,并在各种自然语言处理(NLP)任务中取得了显著的效果。BERT的核心思想是双向编码器和掩码语言模型预训练。
- BERT的核心原理
- 双向编码器(Bidirectional Encoder):
BERT的结构是基于Transformer的编码器部分,利用多层双向自注意力机制(Bidirectional Self-Attention)。
双向自注意力允许模型在计算每个词的表示时,能够同时考虑它左侧和右侧的上下文信息。
- 掩码语言模型(Masked Language Model, MLM):
在预训练阶段,BERT使用掩码语言模型任务。输入序列中的部分词会被随机掩盖(替换为特殊的[MASK]标记),模型的目标是根据上下文预测这些被掩盖的词。
例如,给定句子“BERT is a [MASK] model”,模型需要预测[MASK]应该是“language”。
掩码语言模型使得BERT能够生成上下文相关的词嵌入,因为它在训练过程中学会了利用左右两侧的上下文信息进行预测。
- 下一句预测(Next Sentence Prediction, NSP):
除了掩码语言模型,BERT还使用下一句预测任务进行预训练。模型给定一对句子,判断第二个句子是否是第一个句子的下一句。
例如,给定句子对“A man is walking. He is wearing a hat.”,模型需要预测这两个句子是否在原始文本中相邻。
NSP任务使得BERT能够理解句子之间的关系,这在涉及句子对的任务(如问答和自然语言推理)中非常有用。
- BERT的架构
BERT的架构主要包括以下部分:
- 输入表示(Input Representation):
输入由三种嵌入向量之和组成:词嵌入(Token Embedding)、位置嵌入(Position Embedding)和分段嵌入(Segment Embedding)。
词嵌入是词汇表中每个词的向量表示。位置嵌入表示词在序列中的位置。分段嵌入用于区分两个句子。
- 多层Transformer编码器(Multi-layer Transformer Encoder):
BERT由多层Transformer编码器堆叠而成,每层包含多头自注意力机制和前馈神经网络。
在双向自注意力机制的帮助下,模型能够生成上下文相关的词表示。
- 预训练和微调(Pre-training and Fine-tuning):
预训练阶段:使用大规模文本语料库进行掩码语言模型和下一句预测任务的训练。
微调阶段:在特定的下游任务上进行微调,通过添加一个任务特定的输出层,使用预训练的BERT模型作为基础。
- 应用和效果
BERT在各种NLP任务中都取得了显著的效果,包括但不限于:
文本分类
命名实体识别(NER)
问答系统(QA)
语言推理(NLI)
BERT的出现极大地推动了NLP领域的发展,其双向上下文建模能力和预训练-微调范式使得它在许多任务上达到了最先进的性能。